 23
23so-vits-svc 项目介绍
详细文档请看
Autodl so-vits-svc镜像使用教程 https://www.yuque.com/kisspielengniaoniao/dp89hz/vh4vfw4s743rdx3q
以下是部分镜像使用教程,没有文档的全
镜像内的更新日志记得也看一下
新增声码器微调笔记本和数据集制作笔记本,相关教程之后更新
图文教程(建议看这个)
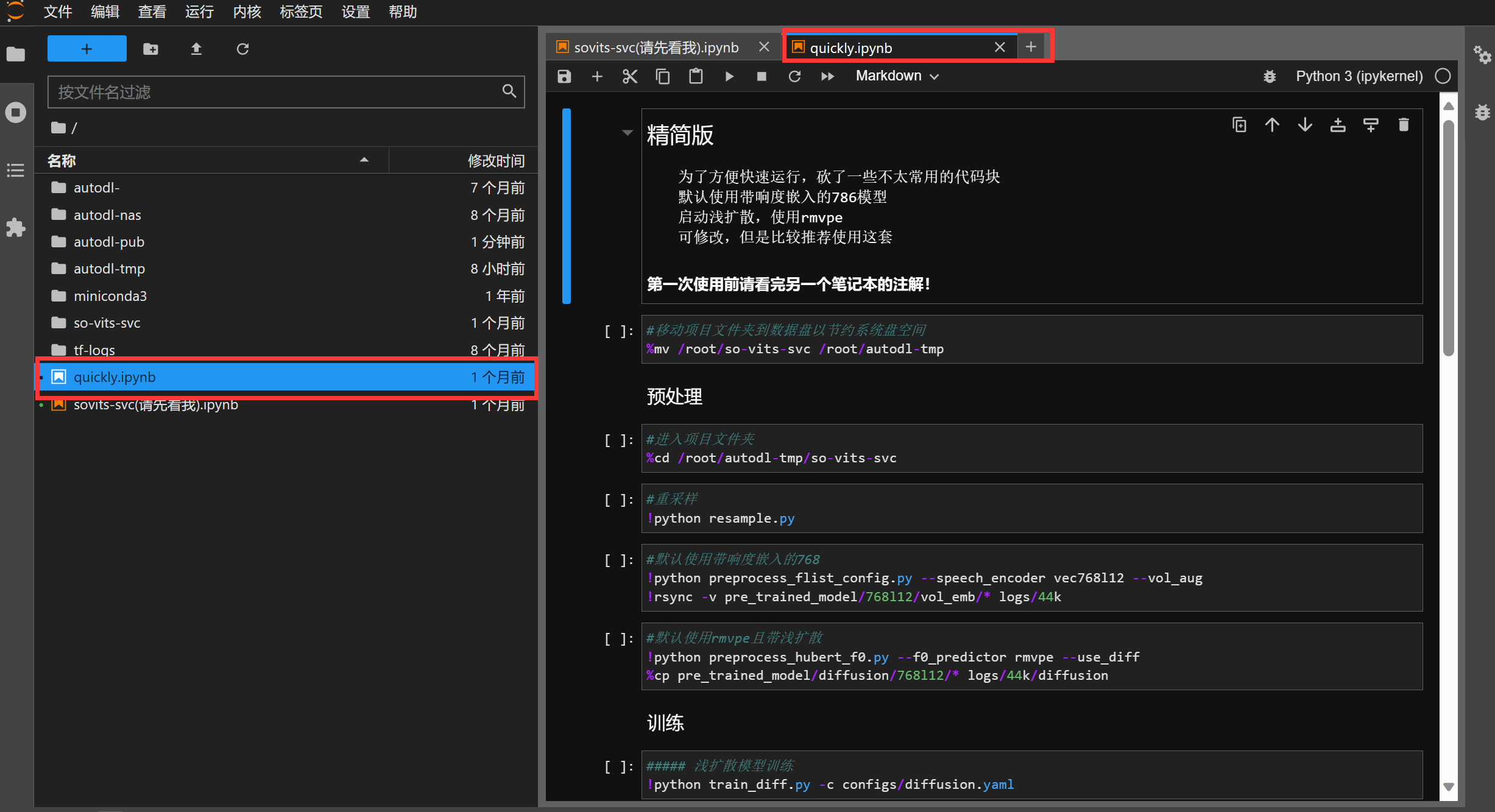
镜像更新了快速使用笔记本,可通过这个笔记本一键使用
推荐使用这个quickly.ipynb
选择的都是目前最推荐的编码器和f0预测器
使用步骤:
-
首次进入镜像,选择并点击上面的三角符号,运行第一个代码块
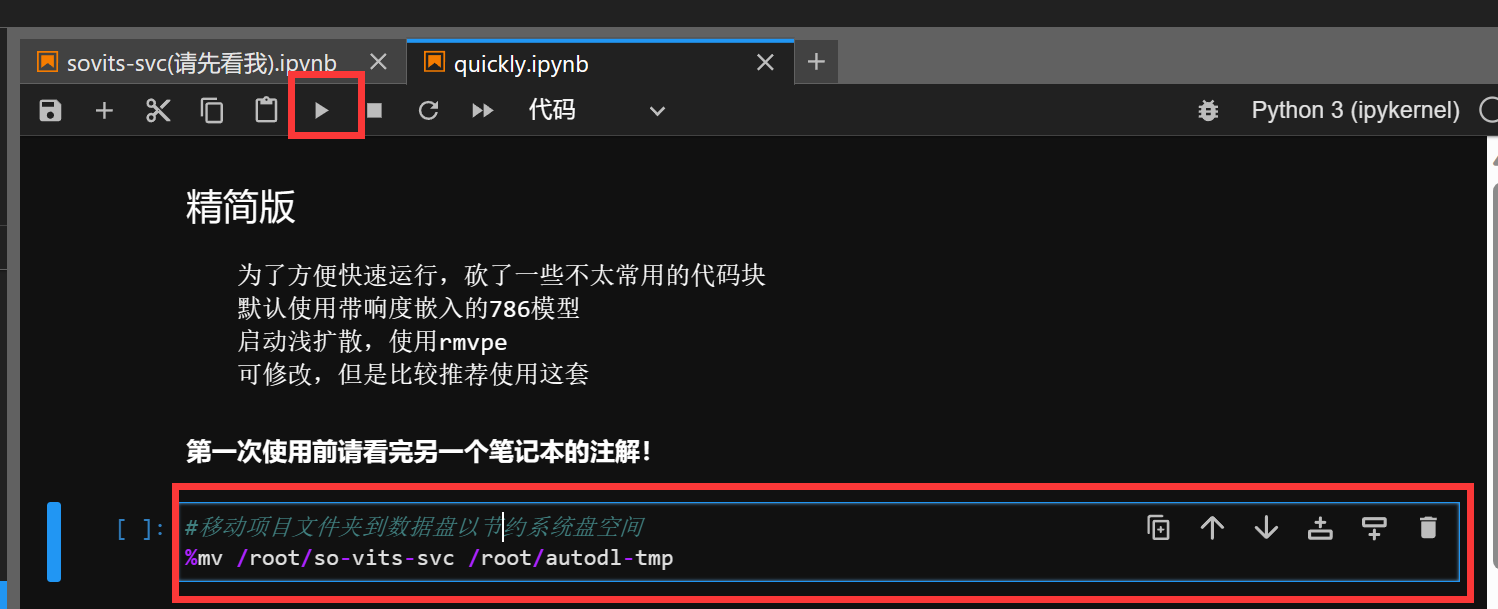
-
将你的音频片段放入so-vits-svc/dataste_raw内,格式如下 dataset/{speaker_name}/xxx.wav
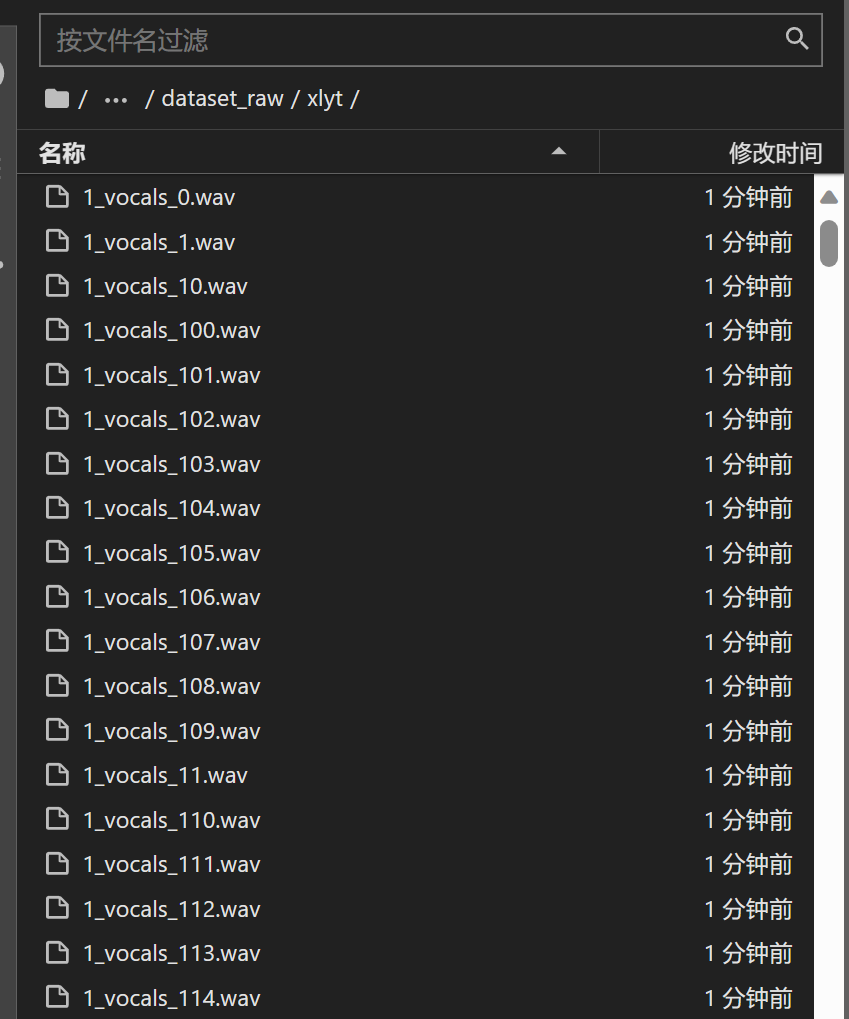 如果没有,可以使用dataset_maker笔记本进行制作,你只需要上传一段长音频即可
数据集制作可以看笔记本注释,之后再更新
如果没有,可以使用dataset_maker笔记本进行制作,你只需要上传一段长音频即可
数据集制作可以看笔记本注释,之后再更新 -
然后就可以一路运行下去,直到训练开始前
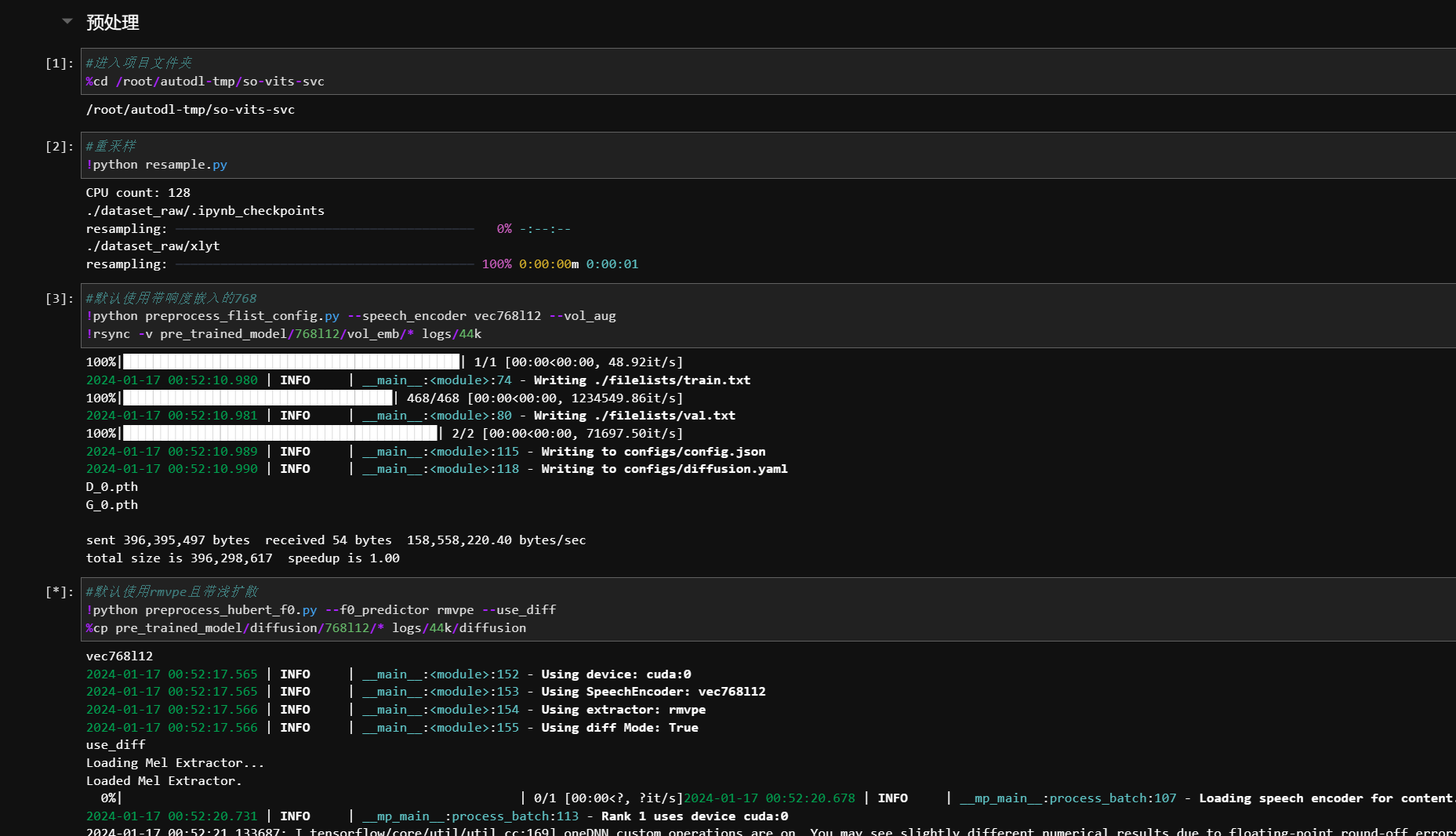
-
等待上面显示预处理完后,找到训练代码块,一共有浅扩散模型训练和主模型训练 只能同时训练一个模型,建议先训练下面的主模型,主模型训练好后再去训练浅扩散
 训练完成后,就可以打开webui进行推理了(其实训练也可以在里面进行,但是不推荐)
上面个是开启webui,运行后,到实例控制台,找到自定义服务,打开即可
下面个是tensorboard,可以不看,如果你实在想看,运行后点击实例监控,然后找到旁边的tensorboard即可
训练完成后,就可以打开webui进行推理了(其实训练也可以在里面进行,但是不推荐)
上面个是开启webui,运行后,到实例控制台,找到自定义服务,打开即可
下面个是tensorboard,可以不看,如果你实在想看,运行后点击实例监控,然后找到旁边的tensorboard即可


本地推理只需要下载 logs/44k内的G_xxxx.pth和config.json文件,如果你训练了浅扩散模型,还需要下载logs/44k/diffusion夹内的model_xxxx.pt文件和config.yaml文件,下载后放在本地推理包的对应文件夹内
本地推理地建议搭配bilibili@羽毛布团 大佬的整合包使用 百度网盘:https://pan.baidu.com/s/12u_LDyb5KSOfvjJ9LVwCIQ?pwd=g8n4 提取码:g8n4
 认证作者
认证作者