ComfyUI-HunyuanVideo-Lora_Train
混元视频模型lora一键训练,镜像内打包了标注,训练,和用于测试的comfyui,打包所有环境,支持上传图片一键训练
 2
20元/小时
v1.0
混元视频模型(Hunyuan Video) Lora训练
镜像简介
本镜像是专为腾讯混元视频模型打造的LoRA一站式训练环境,基于ComfyUI可视化界面,集成了数据标注、模型训练与流程测试的全套工具。用户可通过简洁操作对视频生成效果进行个性化微调,实现风格迁移与角色一致性定制。适用于广告制作、短视频创作及动画设计等场景,大幅降低视频模型定制化门槛,支持高效、低成本的AI视频生成训练。
镜像快速使用教程
1. 先选择GPU型号,再点击立即部署
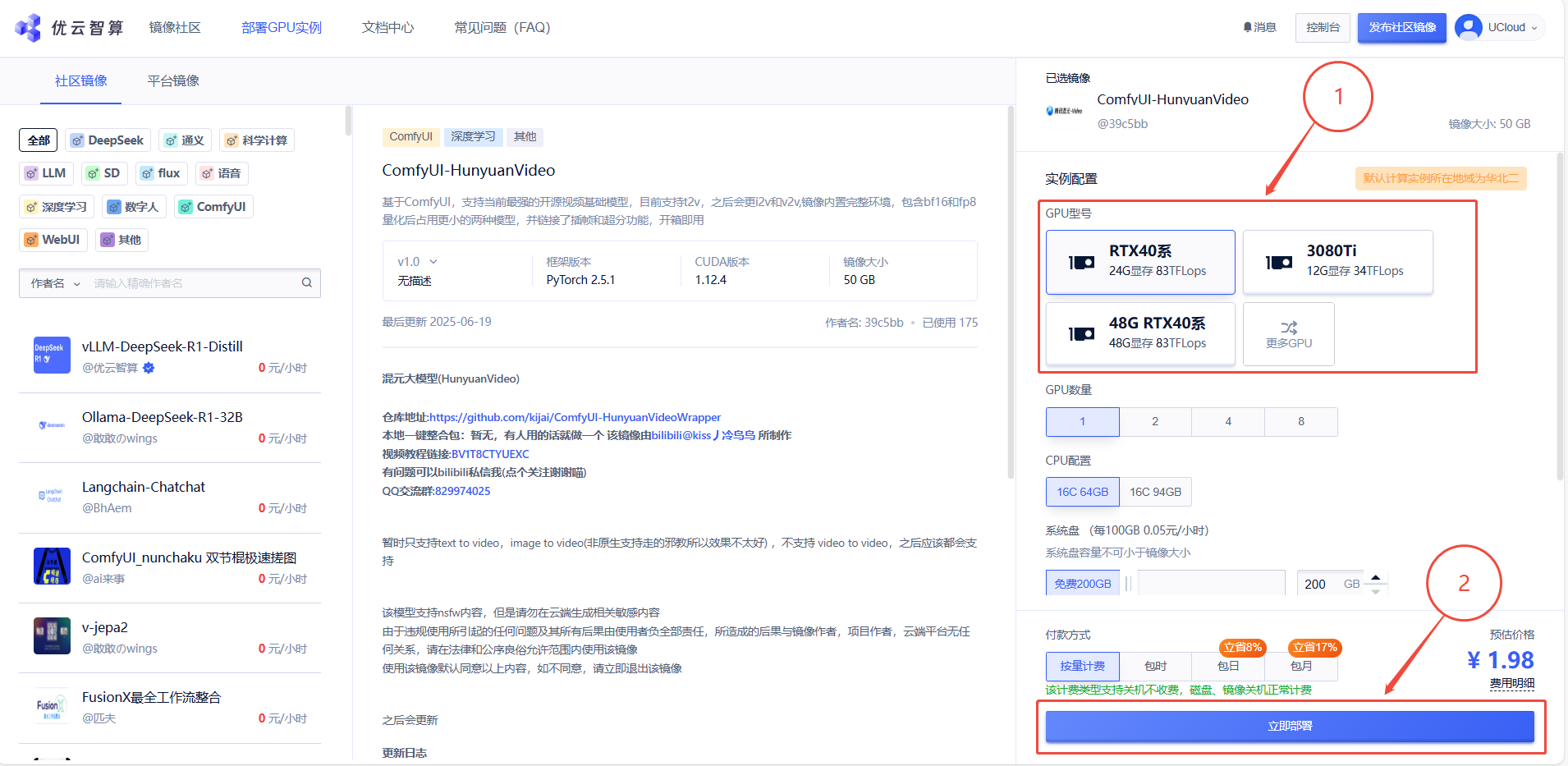
2. 在控制台-操作-更多操作-配置防火墙,进行端口的配置
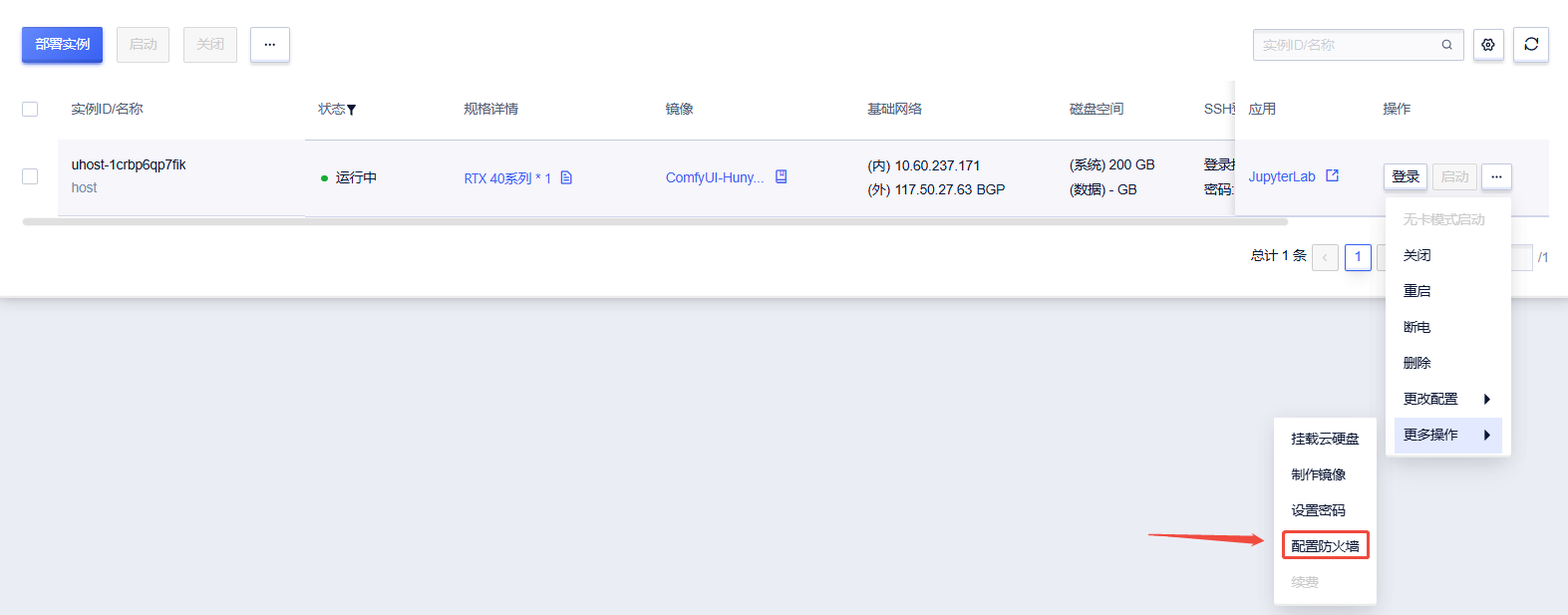
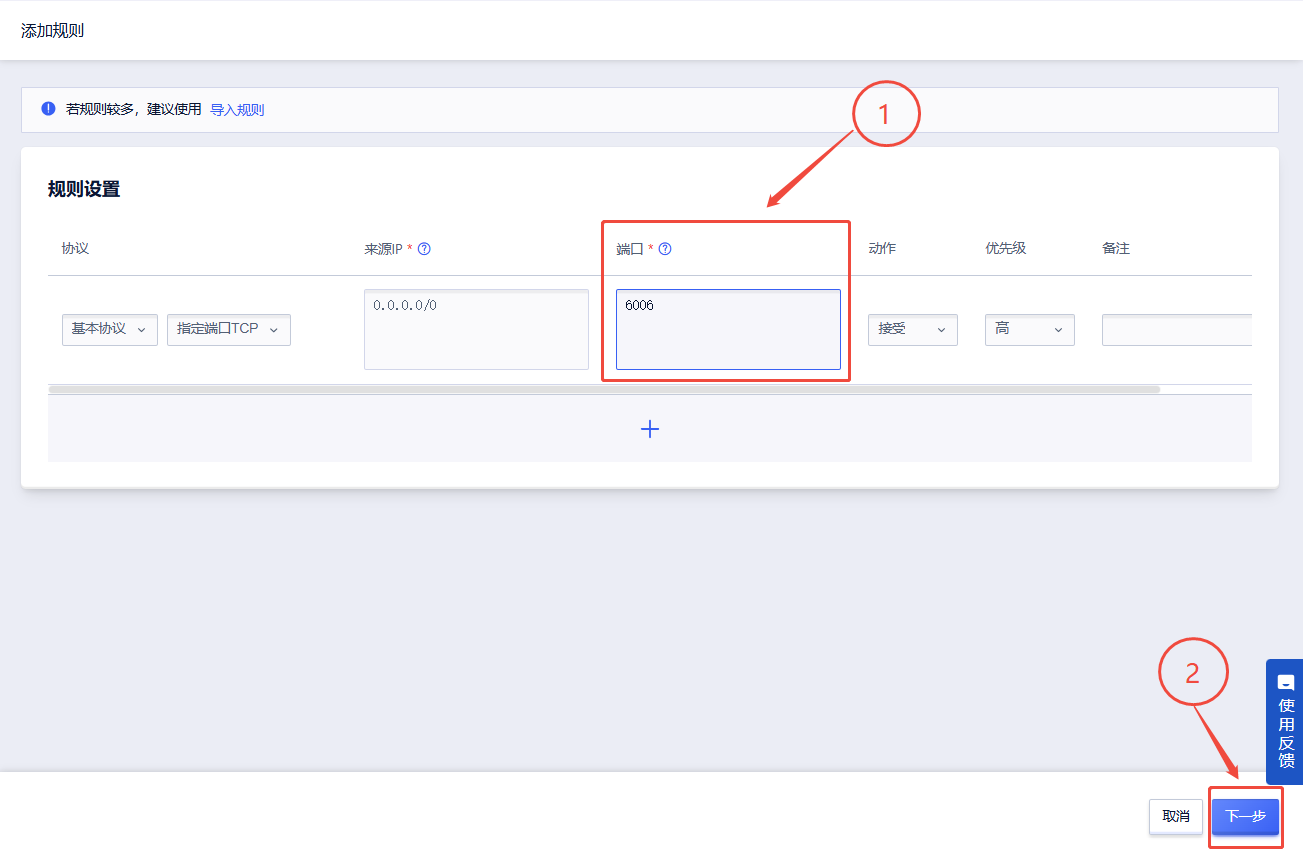
点击“编辑防火墙规则”
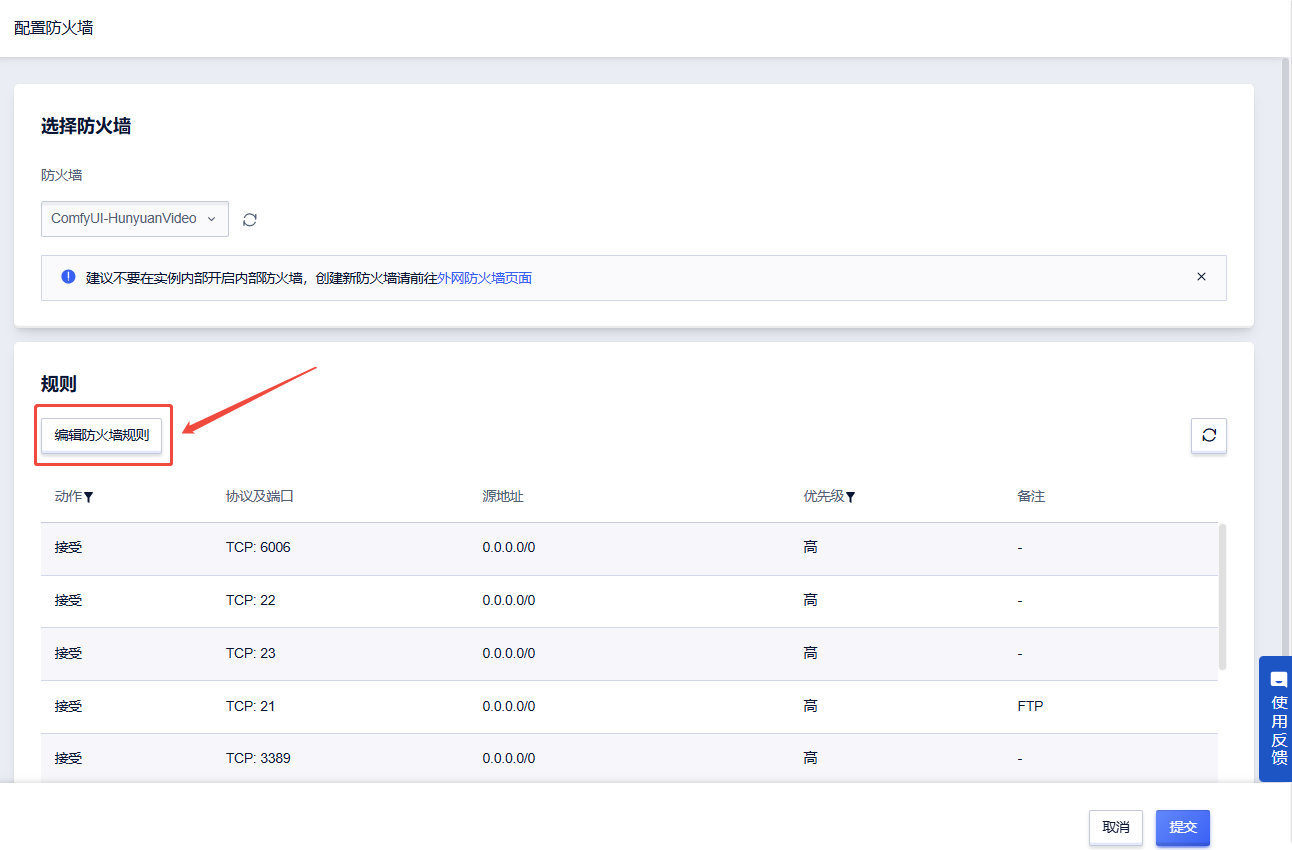
点击“添加规则”
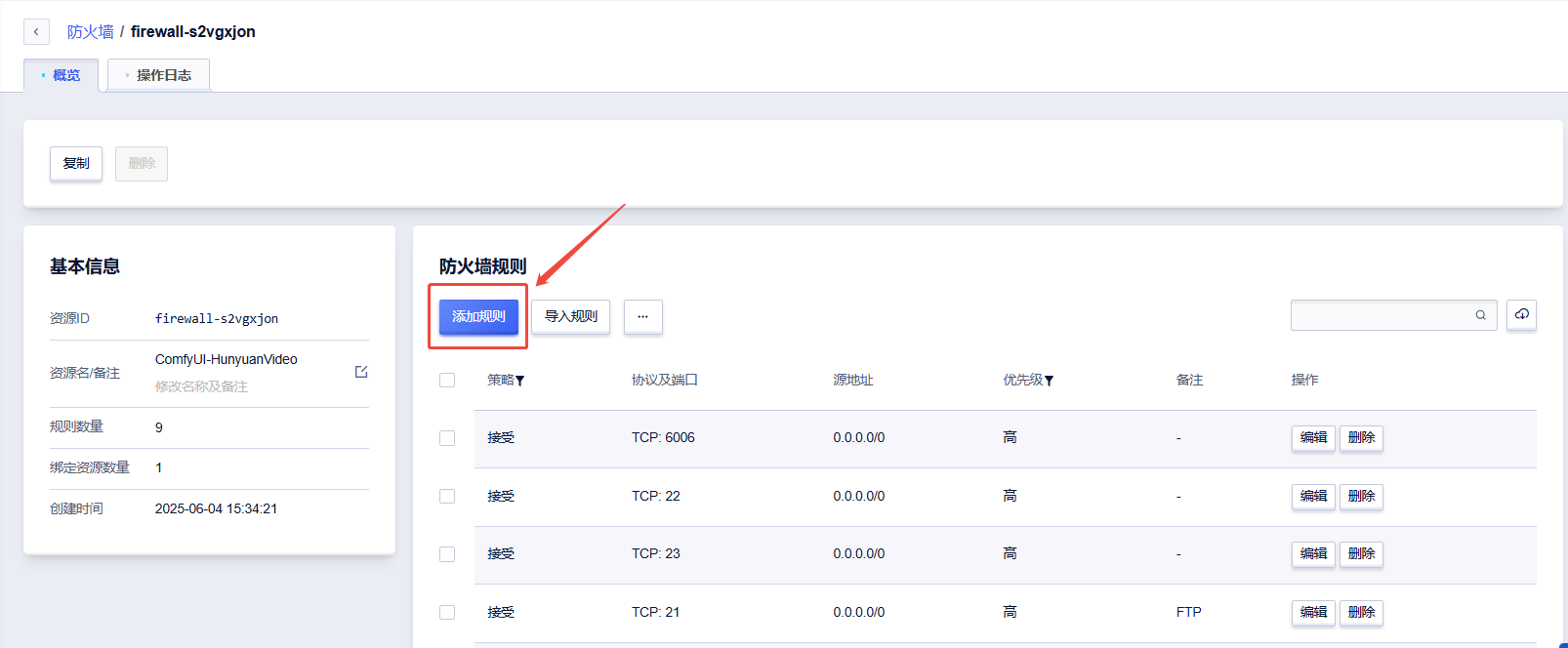
先在端口处输入端口号“6006”,再点击“下一步”以添加端口号
3. 回到控制台,点击“JupyterLab”进入

进入JupyterLab后,按如图所示顺序启动ComfyUI
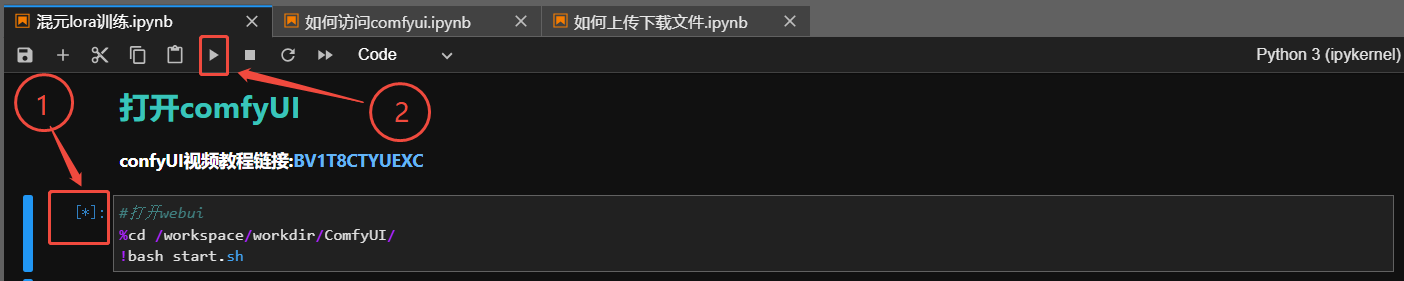
当运行出现如下结果时,即可通过 http://0.0.0.0:6006 访问ComfyUI

0.0.0.0替换为自己的外网ip,外网ip可以在控制台-基础网络(外)中获取,如图中所示外网ip为117.50.27.63

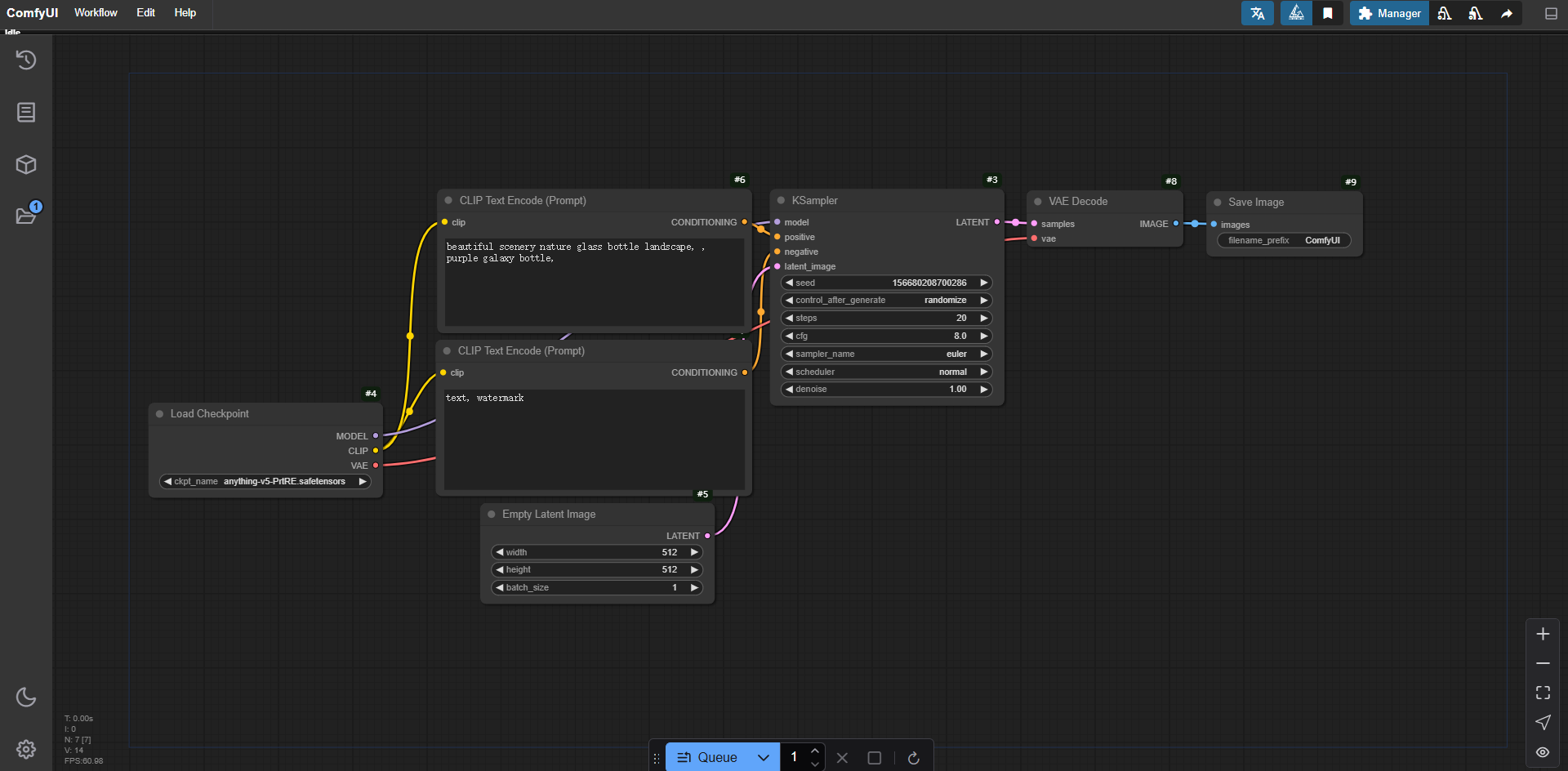
出现以下界面时,即说明ComfyUI启动成功
该lora适用于腾讯混元视频模型,可以训练 人物,镜头,动作等 lora,用于对视频输出内容进行一个固定
使用项目joycaption进行训练集的自然语言标注
项目地址https://github.com/tdrussell/diffusion-pipe
使用项目diffusion-pipe进行训练
项目地址:https://github.com/fpgaminer/joycaption
该镜像由bilibili@kiss丿冷鸟鸟 所制作
视频教程链接:BV1mE6UYxEs7
有问题可以bilibili私信我(点个关注谢谢喵)
QQ交流群:829974025
一些说明
第一次使用请务必看完
由于违规使用所引起的任何问题及其所有后果由使用者负全部责任,所造成的后果与镜像作者,项目作者,云端平台无任何关系,请在法律和公序良俗允许范围内使用该镜像
使用该镜像默认同意以上内容,如不同意,请立即退出该镜像
对于数据集
1.推荐使用自然语言进行标注,镜像内的标注目前测试过效果还可以,比我人肉标好,当然也需要部分修改
2.标注文件的文件名称,和图片名称应一致,下面是数据集的放置格式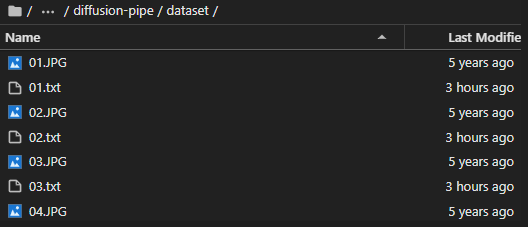
3.图片设置了分桶,自适应分辨率,所以图片大点没关系
4.镜像自带的标注目前支持jpg和png,不区分大小写,其他格式你自己改一下脚本也能用
5.对于一些rsq或者ysq,自动标注也能正常标
对于训练
0.训练默认使用hunyuan_video_vae_bf16.safetensors和hunyuan_video_720_cfgdistill_fp8_e4m3fn.safetensors
1.配置文件位于workdir/diffusion-pipe/examples中,修改之前记得备份,看不懂的别动,默认就行,有更好的参数可以发我
2.diffusion-pip那边推荐使用1024分辨率,所以推荐使用24g卡,
3.默认1epoch保存一次,10左右的epoch就能用,但是目前并不知道最佳训练配置,感兴趣可以自行尝试
4.支持二次元和真人角色混合训练,不过我没测试
5.尽量不要中断训练,我暂时不确定是否能够继续训练
镜像内置comfyui
你可以练完后把模型复制过去进行测试
comfyUI的lora文件夹位于workdir/ComfyUI/models/loras,右键复制粘贴过去即可
数据集标注
如果你已经有了标注过的图片,可跳过标注部分将`图片`和`.txt`放入`workdir/diffusion-
pip/dataset`内即可** 如果你没有标注,则将图片放入`workdir/joycaption/image_to_label`进行标注
有什么问题b站私信或者加群
@39c5bb 认证作者
认证作者
认证作者
镜像信息
已使用118 次
运行时长
937 H
镜像大小
50GB
最后更新时间
2026-02-04
支持卡型
RTX40系20803080Ti309048G RTX40系2080TiH20A800P40A100RTX50系V100S
+12
框架版本
CUDA版本
1.12.4
应用
JupyterLab: 8888
版本
v1.0
2026-02-04