 15
15Qwen3-TTS捏声音自定义声音tts语音克隆语音克隆声音flash_attn加速版Comfyui工作流版 构建by科哥
镜像简介
本镜像集成基于flash_attn加速的语音克隆TTS模型,并通过ComfyUI工作流实现可视化操作,支持用户使用少量音频样本快速克隆自定义音色。适用于虚拟主播配音、有声书播讲、个性化语音助手及创意音频内容制作,提供高效、灵活且易于操控的本地化语音克隆与合成体验。
镜像使用教程
1、 创建实例
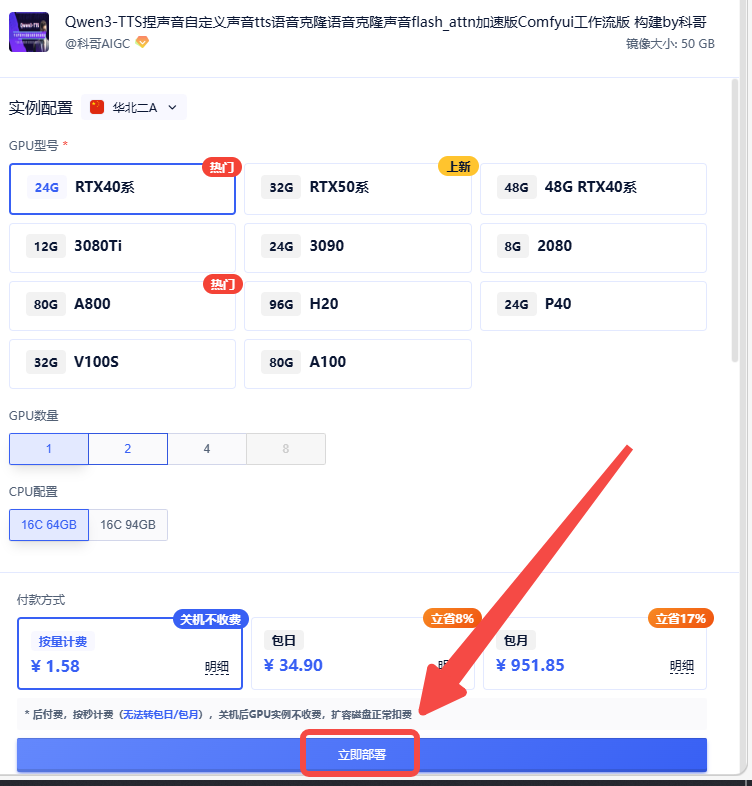
2、启动后点击「SD-WebUI」操作页面会在新的网页窗口打开
运行截图
Qwen3-TTS WebUI 用户使用手册
📖 简介
Qwen3-TTS 是一个强大的文本转语音(TTS)系统,支持多种音色生成方式。本 WebUI 提供了友好的图形界面,让您轻松生成高质量的语音。
主要特性
- 🎨 音色设计:通过文本描述生成定制音色
- 🎭 音色克隆:克隆参考音频的音色
- 🗣️ 文本合成:使用预定义说话人合成语音
- ⚡ 硬件加速:启用 flash-attn 加速推理
- 💾 自动保存:生成的音频自动保存到本地
🚀 快速开始
1. 启动 WebUI
cd /root/Qwen3-TTS
bash start_app.sh
启动选项
--debug: 调试模式,显示详细日志--no-clean: 跳过 GPU 显存清理
自动功能
- ✓ 自动检测并清理端口 7860
- ✓ 自动清理 GPU 显存(仅清理 webui/TTS 相关进程)
- ✓ 无需手动 --force 参数
启动日志示例
[INFO] 端口 7860 被占用,自动清理中...
[INFO] 进程 PID=xxx 已终止
[INFO] 端口 7860 已释放
[INFO] 检查 GPU 显存占用
[INFO] GPU 显存未被占用
[INFO] 启动 Qwen3-TTS WebUI (端口 7860)
访问地址
http://localhost:7860
2. 停止 WebUI
# 方法 1: 使用 Ctrl+C(如果在前台运行)
# 方法 2: 查找并终止进程
ps aux | grep "python -m webui.app" | grep -v grep | awk '{print $2}' | xargs kill
# 方法 3: 清理端口
lsof -ti:7860 | xargs kill
🎯 功能详解
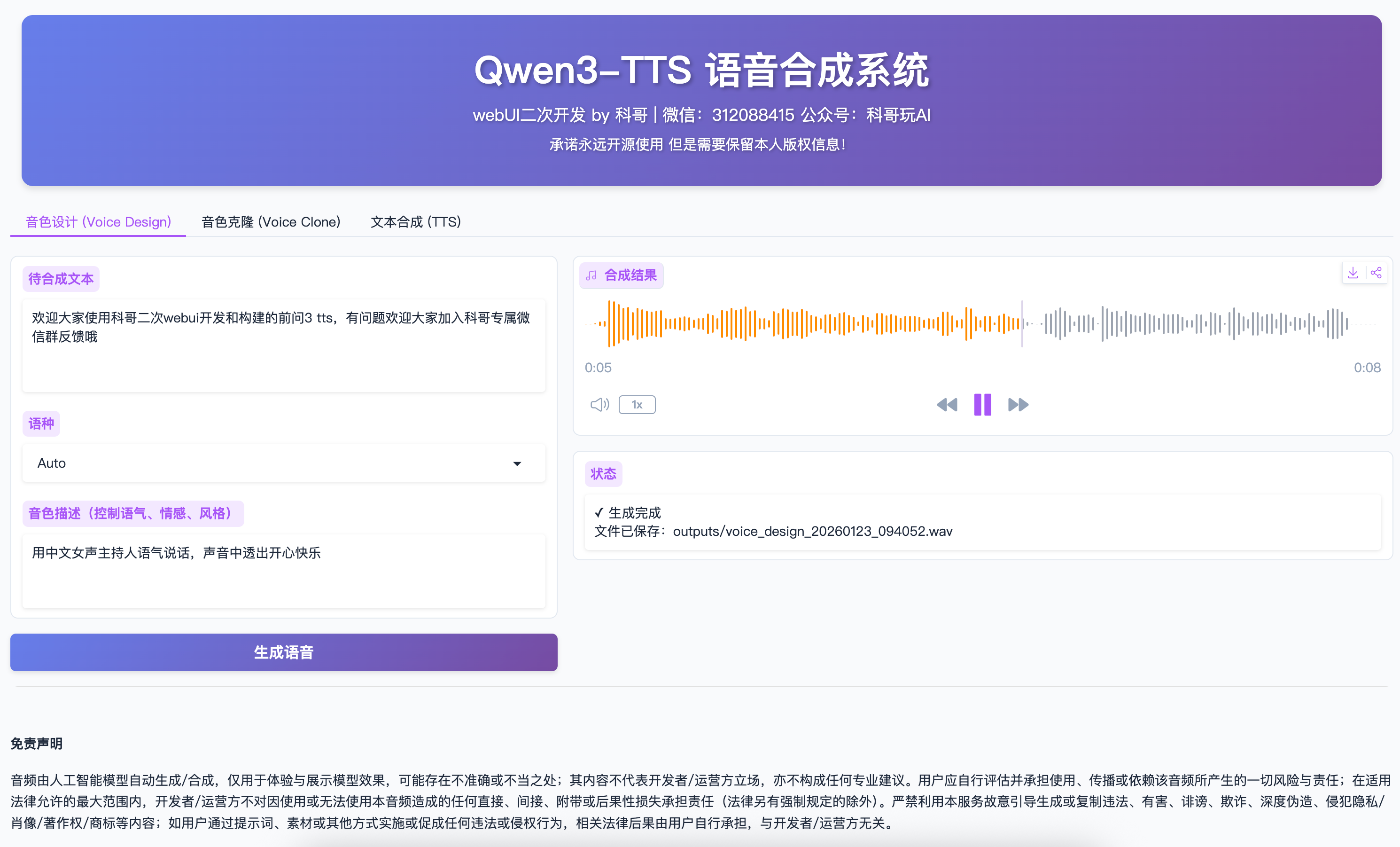
Tab 1: 音色设计 (Voice Design)
适用场景
- 需要特定情感或风格的语音
- 想要创造独特的音色
- 需要精确控制语气和情感
使用步骤
-
输入待合成文本
- 在"待合成文本"框中输入要转换的文字
- 支持中文、英文等多种语言
- 建议单次输入不超过 200 字
-
选择语种
Auto: 自动检测(推荐)zh: 中文en: 英文- 其他语种根据模型支持情况选择
-
描述音色
- 在"音色描述"框中输入期望的音色特征
- 示例:
- "用中文女声主持人语气说话,声音中透出开心快乐"
- "用特别惊讶且带有一丝恐慌的语气说"
- "用温柔的男声,语速稍慢,带有磁性"
-
生成语音
- 点击"生成语音"按钮
- 等待模型推理(通常 5-15 秒)
- 生成完成后可在右侧播放
-
保存文件
- 音频自动保存到
outputs/voice_design_时间戳.wav - 状态栏显示保存路径
- 可直接在文件管理器中查看
- 音频自动保存到
技巧与建议
- 音色描述越详细,效果越好
- 可以描述情感、语速、音调等特征
- 尝试不同的描述词获得最佳效果
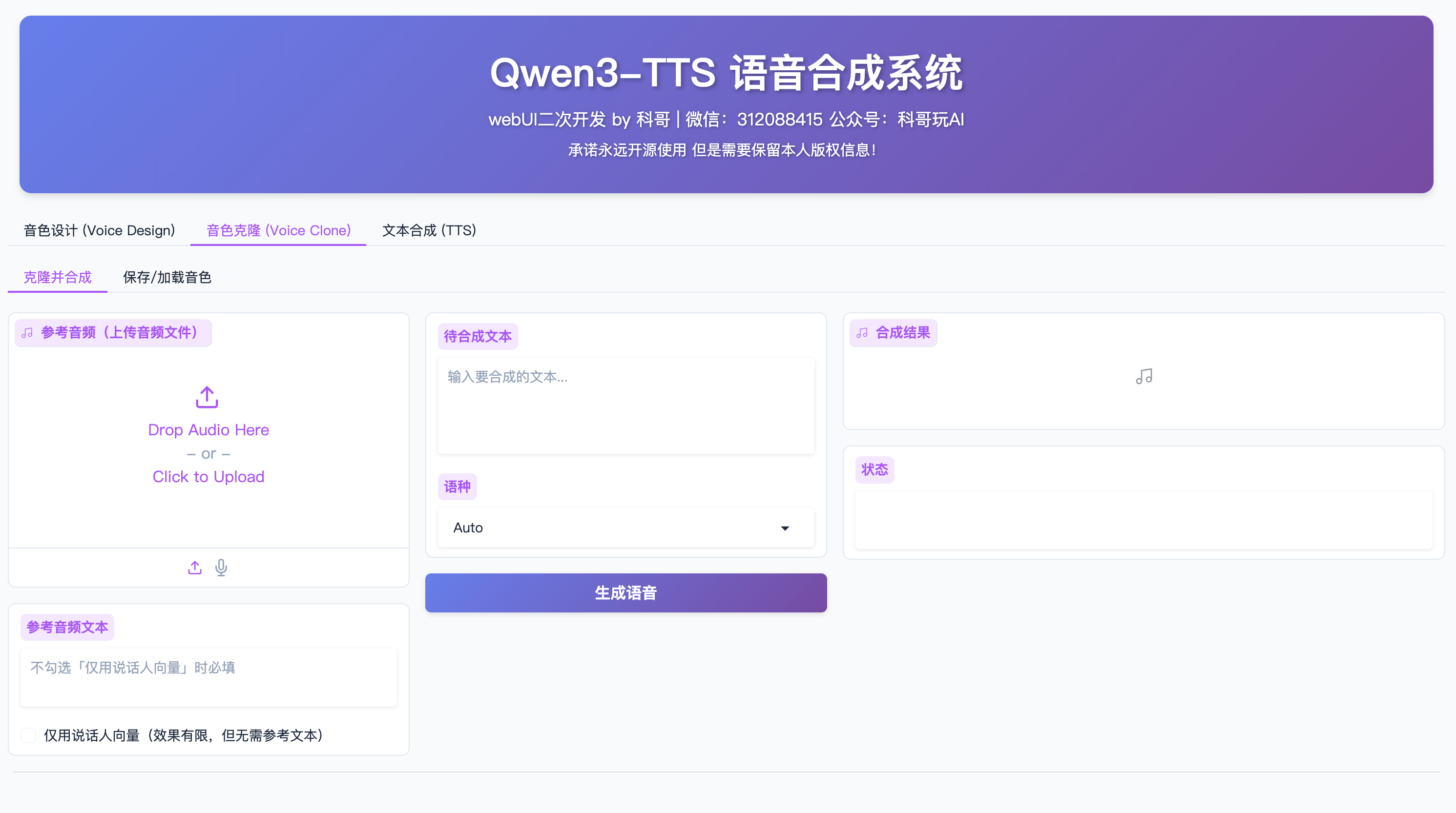
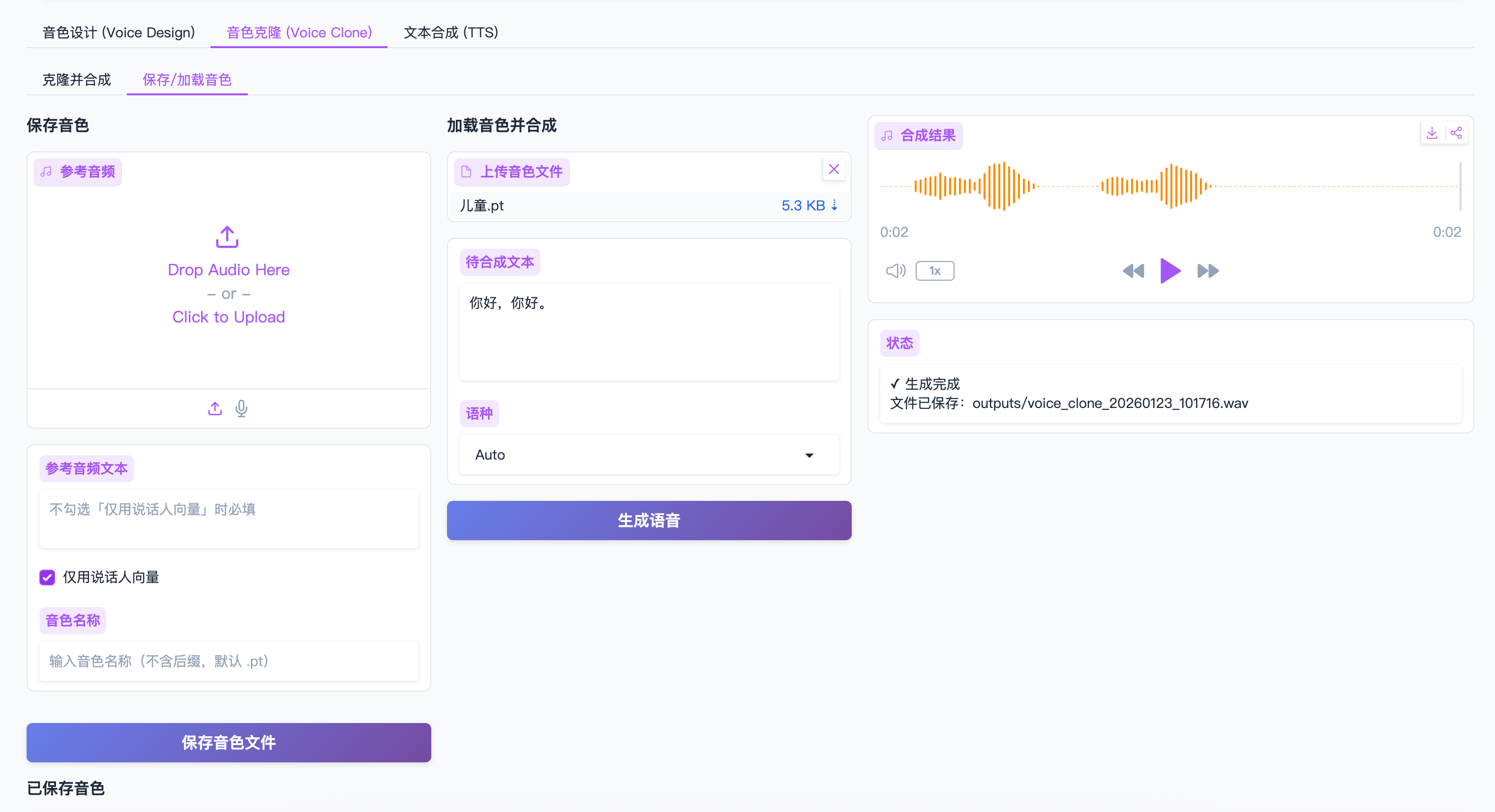
Tab 2: 音色克隆 (Voice Clone)
适用场景
- 需要模仿特定人物的声音
- 想要保持音色一致性
- 需要使用自己的声音
子功能 1: 克隆并合成
使用步骤
-
上传参考音频
- 点击"参考音频"上传音频文件
- 支持格式:WAV、MP3、FLAC 等
- 建议:
- 时长 3-10 秒
- 清晰无噪音
- 单人说话
-
输入参考音频文本
- 在"参考音频文本"框中输入音频的文字内容
- 必须与音频内容完全一致
- 如果勾选"仅用说话人向量",可以不填
-
选择克隆模式
- ☐ 仅用说话人向量
- 效果有限,但无需参考文本
- 适合快速测试
- ☑ 完整克隆(推荐)
- 需要参考文本
- 效果更好,音色更准确
- ☐ 仅用说话人向量
-
输入待合成文本
- 输入要用克隆音色说的内容
- 可以与参考文本不同
-
生成语音
- 点击"生成语音"
- 等待推理完成
- 音频保存到
outputs/voice_clone_时间戳.wav
子功能 2: 保存/加载音色 ⭐ 全新升级
音色管理系统
现在支持完整的音色管理功能,包括命名保存、列表管理、试听和快速加载。
保存音色
-
上传参考音频
- 点击"参考音频"上传音频文件
- 支持格式:WAV、MP3、FLAC 等
- 建议:时长 3-10 秒,清晰无噪音
-
输入参考音频文本
- 在"参考音频文本"框中输入音频的文字内容
- 如果勾选"仅用说话人向量",可以不填
-
命名音色
- 在"音色名称"输入框中输入名称
- 示例:
我的音色、女声主持人、温柔男声 - 系统会自动添加
.pt后缀 - 实时验证:
- 绿色 ✓:名称可用
- 红色 ✗:名称已存在或包含非法字符
- 禁止字符:
/ \ : * ? " < > |和空格
-
保存
- 点击"保存音色文件"
- 音色保存到
voices/目录 - 包含两个文件:
音色名称.pt:音色数据音色名称_ref.wav:参考音频
- 音色列表自动更新
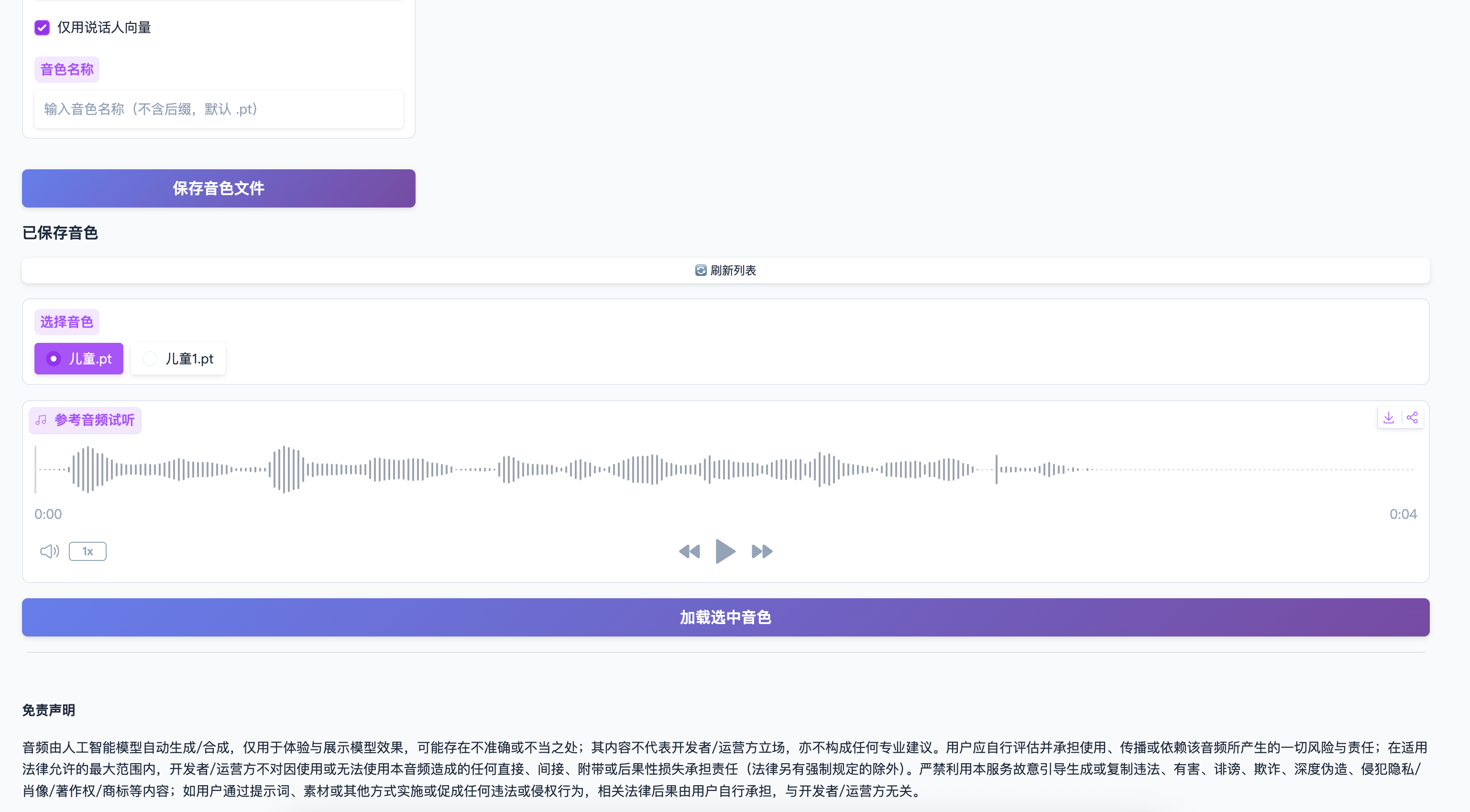
音色列表
-
自动加载
- 页面打开时自动显示已保存的音色
- 无需手动刷新
-
查看音色
- 在"已保存音色"列表中查看所有音色
- 点击"🔄 刷新列表"手动更新(如果需要)
-
试听音色
- 在列表中选择一个音色
- 参考音频自动显示在"参考音频试听"播放器中
- 点击播放按钮试听
-
加载音色
- 选择要使用的音色
- 点击"加载选中音色"按钮
- 音色文件自动填充到"上传音色文件"组件
使用音色生成语音
- 加载音色后(通过列表或手动上传)
- 在"待合成文本"框中输入要说的内容
- 选择语种(通常选择
Auto) - 点击"生成语音"
- 音频保存到
outputs/voice_clone_时间戳.wav
音色文件管理
查看音色文件
# 列出所有音色
ls -lh voices/
# 查看音色数量
ls -1 voices/*.pt | wc -l
音色文件结构
voices/
├── 我的音色.pt # 音色数据(约 5KB)
├── 我的音色_ref.wav # 参考音频(约 200KB)
├── 女声主持人.pt
├── 女声主持人_ref.wav
└── ...
删除音色
# 删除单个音色(需要删除两个文件)
rm voices/我的音色.pt
rm voices/我的音色_ref.wav
# 或使用通配符
rm voices/我的音色*
优势
- ✓ 音色持久化保存,不会丢失
- ✓ 可以管理多个音色
- ✓ 支持试听参考音频
- ✓ 一键快速加载
- ✓ 音色可以分享(复制 .pt 和 _ref.wav 文件)
- ✓ 页面加载时自动显示音色列表
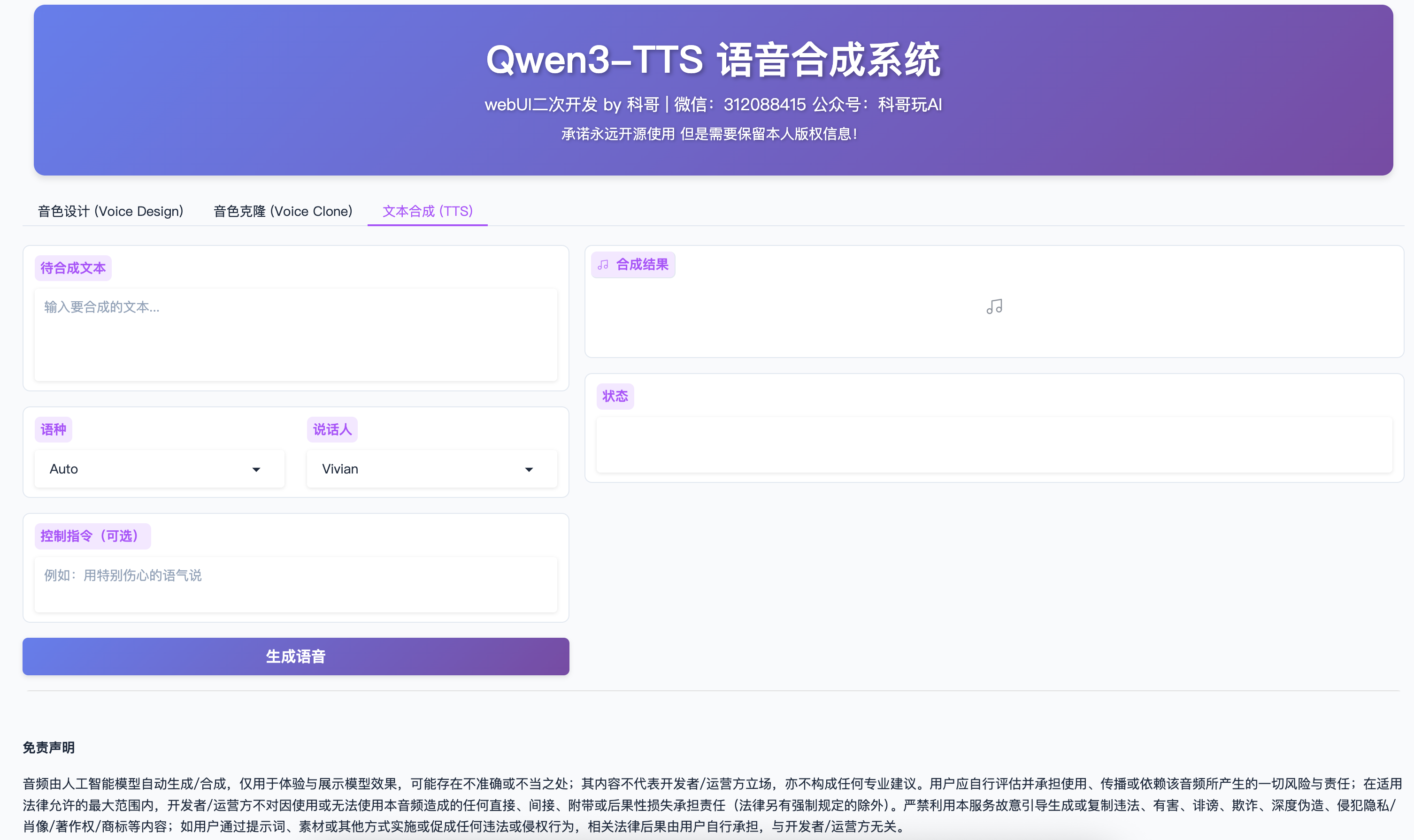
Tab 3: 文本合成 (TTS)
适用场景
- 快速生成语音
- 使用预定义的高质量音色
- 不需要自定义音色
使用步骤
-
输入待合成文本
- 在文本框中输入内容
-
选择语种
- 通常选择
Auto即可
- 通常选择
-
选择说话人
- 从下拉菜单选择预定义的说话人
- 可用说话人:
- Vivian(默认)
- 其他说话人根据模型配置
-
添加控制指令(可选)
- 在"控制指令"框中输入情感或风格描述
- 示例:
- "用特别伤心的语气说"
- "用兴奋的语气说"
- "语速稍快"
-
生成语音
- 点击"生成语音"
- 音频保存到
outputs/tts_时间戳.wav
📁 文件管理
生成的音频文件
保存位置
/root/Qwen3-TTS/outputs/
文件命名规则
voice_design_20260123_143052.wav # 音色设计
voice_clone_20260123_143053.wav # 音色克隆
tts_20260123_143054.wav # 文本合成
查看文件
# 列出所有生成的音频
ls -lh outputs/
# 查看最新生成的 5 个文件
ls -lt outputs/*.wav | head -5
# 统计文件数量
ls outputs/*.wav | wc -l
清理文件
# 删除所有音频文件
rm outputs/*.wav
# 删除 7 天前的文件
find outputs/ -name "*.wav" -mtime +7 -delete
# 只保留最新的 100 个文件
ls -t outputs/*.wav | tail -n +101 | xargs rm
音色文件 ⭐ NEW
保存位置
/root/Qwen3-TTS/voices/
文件结构
voices/
├── 我的音色.pt # 音色数据(约 5KB)
├── 我的音色_ref.wav # 参考音频(约 200KB)
├── 女声主持人.pt
├── 女声主持人_ref.wav
└── ...
查看音色
# 列出所有音色
ls -lh voices/
# 查看音色数量
ls -1 voices/*.pt | wc -l
# 查看音色详情
for pt in voices/*.pt; do
echo "音色: $(basename $pt)"
echo " 大小: $(du -h $pt | cut -f1)"
wav="${pt%.pt}_ref.wav"
if [ -f "$wav" ]; then
echo " 参考音频: $(du -h $wav | cut -f1)"
fi
echo
done
删除音色
# 删除单个音色(删除两个文件)
rm voices/我的音色.pt
rm voices/我的音色_ref.wav
# 或使用通配符
rm voices/我的音色*
# 删除所有音色
rm voices/*.pt voices/*.wav
备份音色
# 备份到其他目录
cp -r voices/ /backup/voices_backup_$(date +%Y%m%d)/
# 压缩备份
tar -czf voices_backup_$(date +%Y%m%d).tar.gz voices/
⚙️ 高级功能
实时监控
使用监控脚本查看 WebUI 运行状态:
bash monitor_webui.sh
显示内容
- 进程状态(PID、CPU、内存)
- 端口监听状态
- 生成文件统计
- 最新日志
退出监控
按 Ctrl+C
查看日志
# 查看启动日志
tail -f /tmp/webui_final2.log
# 查看最近 50 行日志
tail -50 /tmp/webui_final2.log
# 搜索错误日志
grep -i error /tmp/webui_final2.log
性能优化
已启用的优化
- ✅ flash-attn 硬件加速
- ✅ GPU 推理
- ✅ 模型缓存
查看 GPU 使用情况
nvidia-smi
# 实时监控
watch -n 1 nvidia-smi
🎨 使用技巧
1. 获得最佳音质
文本准备
- 使用标准标点符号
- 避免过长的句子(建议 50 字以内)
- 数字建议用中文表示(如"一百"而不是"100")
音色描述
- 具体描述情感和风格
- 可以参考专业术语(如"磁性"、"清脆")
- 多次尝试不同描述
参考音频
- 选择清晰、无噪音的音频
- 时长 3-10 秒最佳
- 避免背景音乐
2. 提高生成速度
- 使用较短的文本
- 避免同时生成多个音频
- 确保 GPU 可用
3. 批量生成
虽然 WebUI 不直接支持批量,但可以:
- 保存音色文件
- 多次使用相同音色生成
- 或使用 Python API(需要编程)
❓ 常见问题
Q1: 生成速度很慢怎么办?
检查项
- GPU 是否可用:
nvidia-smi - flash-attn 是否启用:查看启动日志
- 系统资源是否充足:
htop
解决方案
- 确保 GPU 驱动正常
- 重启 WebUI
- 减少文本长度
Q2: 音频质量不好怎么办?
可能原因
- 参考音频质量差
- 音色描述不够准确
- 文本格式问题
改进方法
- 使用高质量参考音频
- 优化音色描述
- 调整文本格式
Q3: 无法访问 WebUI
检查步骤
# 1. 检查进程是否运行
ps aux | grep webui
# 2. 检查端口是否监听
lsof -i:7860
# 3. 检查防火墙
# 如果是远程访问,确保端口开放
解决方案
- 重启 WebUI:
bash start_app.sh --force - 检查日志:
tail /tmp/webui_final2.log - 更换端口(修改配置文件)
Q4: 生成的音频在哪里?
位置
/root/Qwen3-TTS/outputs/
查看
ls -lh outputs/
下载
- 使用 SCP/SFTP 下载到本地
- 或在 WebUI 中直接播放和下载
Q5: 如何更换说话人?
文本合成 Tab
- 直接从下拉菜单选择
音色设计/克隆
- 通过描述或参考音频定制
Q6: 支持哪些语言?
主要支持
- 中文(普通话)
- 英文
其他语言
- 根据模型配置可能支持其他语言
- 建议使用
Auto自动检测
🔧 故障排除
错误:端口被占用
OSError: Cannot find empty port in range: 7860-7860
解决 启动脚本已自动处理端口清理,无需手动操作。如果仍有问题:
# 手动清理端口
lsof -ti:7860 | xargs kill
# 然后重新启动
bash start_app.sh
错误:模型加载失败
FileNotFoundError: Model not found
解决
- 检查模型文件是否存在:
ls models/ - 检查网络连接(如需下载)
- 查看日志获取详细错误
错误:CUDA 不可用
CUDA is not available
解决
- 检查 GPU:
nvidia-smi - 检查 CUDA 安装
- 重启系统
错误:音频保存失败
Permission denied: outputs/
解决
# 检查目录权限
ls -ld outputs/
# 修复权限
chmod 755 outputs/
📞 获取帮助
查看系统状态
# 完整状态检查
bash monitor_webui.sh
# GPU 状态
nvidia-smi
# 磁盘空间
df -h
# 内存使用
free -h
日志位置
- 启动日志:
/tmp/webui_final2.log - 监控输出:实时显示
- 错误日志:包含在启动日志中
重置环境
# 停止 WebUI
lsof -ti:7860 | xargs kill
# 清理缓存
rm -rf __pycache__
rm -rf webui/__pycache__
# 重启
bash start_app.sh --force
💡 最佳实践
1. 日常使用
- 定期清理
outputs/目录 - 保存常用的音色文件
- 记录好用的音色描述
2. 性能优化
- 避免过长的文本
- 使用音色文件而不是每次上传
- 关闭不必要的后台程序
3. 质量保证
- 使用高质量参考音频
- 详细的音色描述
- 多次尝试找到最佳参数
📚 附录
支持的音频格式
输入
- WAV
- MP3
- FLAC
- OGG
输出
- WAV (16kHz/24kHz, 16-bit)
推荐配置
最低配置
- GPU: NVIDIA GTX 1060 (6GB)
- 内存: 8GB
- 磁盘: 20GB
推荐配置
- GPU: NVIDIA RTX 3090/4090
- 内存: 16GB+
- 磁盘: 50GB+
快捷命令
# 启动(自动清理端口和 GPU)
bash start_app.sh
# 调试模式
bash start_app.sh --debug
# 跳过 GPU 清理
bash start_app.sh --no-clean
# 监控
bash monitor_webui.sh
# 查看日志
tail -f /tmp/restart.log
# 清理音频
rm outputs/*.wav
# 清理音色
rm voices/*.pt voices/*.wav
# 检查 GPU
nvidia-smi
# 查看音色列表
ls -lh voices/
# 查看生成的音频
ls -lh outputs/
文档版本: v2.0 ⭐ 新增音色管理系统 最后更新: 2026-01-23 维护者: Claude
🆕 v2.0 更新内容
音色管理系统
- ✓ 命名保存音色到
voices/目录 - ✓ 实时文件名验证(重复检测、非法字符)
- ✓ 音色列表自动加载
- ✓ 参考音频试听功能
- ✓ 一键快速加载音色
- ✓ 保存后自动更新列表
启动脚本增强
- ✓ 自动清理端口 7860
- ✓ 自动清理 GPU 显存
- ✓ 无需手动 --force 参数
- ✓ 智能进程管理
用户体验改进
- ✓ 页面加载时自动显示音色
- ✓ 实时名称验证提示
- ✓ 更流畅的操作流程
如有问题或建议,请查看 todo.md 或联系技术支持。
bug反馈可以加入科哥专属群交流➕ 广告勿进!

科哥在UCloud镜像列表【不断更新中】:
 认证作者
认证作者
 支持自启动
支持自启动