 4
4ComfyUI-OmniVoice-TTS小米团队开源单人多人声音克隆语音克隆捏声音
支持4090显卡
项目源码:
运行截图:
【插入一个小广告 给需要使用各种大模型和ai模型的多一个选择】: 【好消息】欢迎测试使用! 1.api中转站【推荐】,全球最卷,有些比官网便宜90+%: https://ai.kegeai.top/register?aff=78Gs
-
工作流有sora,veo3,grok3等ai视频生成,谷歌香蕉修图,gpt,gemini3,claude,deepseek等等500+模型api
-
注册帮助: https://kege-aigc.feishu.cn/docx/Gr5wddbYwogvkSxYfdxc7ou1nFb?from=from_copylink
bug反馈可以加入科哥专属群交流➕ 广告勿进!

科哥在UCloud镜像列表【不断更新中】:
OmniVoice TTS 用户使用手册
基于 ComfyUI 的零样本多语言语音合成工具 — 支持声音克隆、声音设计、多人对话,覆盖 600+ 种语言。
目录
1. 快速开始
1.1 启动 ComfyUI
- [开始已经自动运行 直接打开控制面板的 【打开COmfyUI】 即可]
- 手动运行:进入jupyterlab,打开终端,然后输入指令回车执行即可:
- cd /root && bash run.sh
启动 ComfyUI 后,在浏览器中打开界面(通常为 http://127.0.0.1:8188)。
1.2 加载工作流
在 ComfyUI 界面中:
- 点击右上角的 菜单按钮(或拖拽
.json文件到画布) - 选择 Load → 找到对应的工作流文件
- 工作流会自动加载到画布上
四个预设工作流位于:
ComfyUI/user/default/workflows/
├── 1.单人声音克隆.json
├── 2.单人长文本声音克隆.json
├── 3.声音设计 捏一个声音.json
└── 4.多人对话.json
1.3 首次运行
首次运行时,插件会自动从 HuggingFace 下载所需的模型文件(约 2-4GB),请耐心等待。下载完成后即可正常使用。
1.4 执行生成
- 在工作流中填写所需的文本和参数
- 点击右侧面板的 Queue Prompt 按钮
- 等待生成完成,音频会自动输出
2. 四大核心功能
| 功能 | 对应节点 | 适用场景 |
|---|---|---|
| 单人声音克隆 | OmniVoice Voice Clone TTS | 用 3-15 秒参考音频克隆声音,生成短文本语音 |
| 单人长文本声音克隆 | OmniVoice Longform TTS | 克隆声音后生成长篇文章、小说等 |
| 声音设计 | OmniVoice Voice Design TTS | 无需参考音频,用文字描述创建声音 |
| 多人对话 | OmniVoice Multi-Speaker TTS | 生成两人或多人对话、广播剧等 |
3. 功能一:单人声音克隆
工作流文件: 1.单人声音克隆.json
使用场景
用一段 3-15 秒的参考音频克隆某个人的声音,然后用这个声音朗读你输入的文本。
操作步骤
- 加载工作流 — 导入
1.单人声音克隆.json - 上传参考音频 — 在节点的
ref_audio输入端上传参考音频文件(3-15 秒效果最佳) - 填写参考文本(可选) — 如果知道参考音频的内容,填入
ref_text可提高克隆质量;留空则自动识别 - 输入要合成的文本 — 在
text参数中输入你想让克隆声音朗读的内容 - 调整参数 — 根据需要调整步数、语速等(见下方参数说明)
- 点击 Queue Prompt 执行
小贴士
- 参考音频越清晰、背景噪音越少,克隆效果越好
- 参考音频中最好只包含一个人的声音
- 短文本(几句话)使用此节点;长文本请使用"长文本声音克隆"
4. 功能二:单人长文本声音克隆
工作流文件: 2.单人长文本声音克隆.json
使用场景
克隆声音后,生成长篇文章、小说章节、播客脚本等长文本语音。
操作步骤
- 加载工作流 — 导入
2.单人长文本声音克隆.json - 上传参考音频 — 在
ref_audio输入端上传参考音频 - 填写参考文本(可选) — 同上
- 输入长文本 — 在
text参数中输入长篇文章 - 设置分块大小 — 调整
words_per_chunk参数(默认 100),控制每次处理的词数 - 点击 Queue Prompt 执行
小贴士
words_per_chunk = 0表示不分块,一次性处理(适合中等长度文本)- 长文本建议保持默认分块设置,避免显存不足
- 此节点会自动在块之间保持声音的一致性
5. 功能三:声音设计(捏一个声音)
工作流文件: 3.声音设计 捏一个声音.json
使用场景
不需要任何参考音频,直接用文字描述来"捏"一个声音。可以控制性别、年龄、音调、口音等属性。
操作步骤
- 加载工作流 — 导入
3.声音设计 捏一个声音.json - 描述声音 — 在
voice_instruct参数中用英文描述你想要的声音特征 - 输入要合成的文本 — 在
text参数中输入朗读内容 - 调整参数 — 根据需要调整
- 点击 Queue Prompt 执行
声音描述格式
用逗号分隔各个属性,例如:
female, young, high pitch, british accent
male, middle-aged, low pitch, whisper
可用属性
| 类别 | 可选值 |
|---|---|
| 性别 | male(男)、female(女) |
| 年龄 | child(儿童)、young(青年)、middle-aged(中年)、elderly(老年) |
| 音调 | very low pitch、low pitch、medium pitch、high pitch、very high pitch |
| 风格 | whisper(耳语) |
| 英语口音 | american accent、british accent、australian accent 等 |
| 汉语方言 | 四川话、陕西话、广东话、东北话、山东话、河南话、上海话、闽南话、客家话 等 |
小贴士
- 如果效果不满意,可以调整
seed(随机种子)重新生成 - 每次生成结果会有细微差异,多试几次找到最满意的效果
- 属性越多描述越精确,但也可能限制声音的自然度
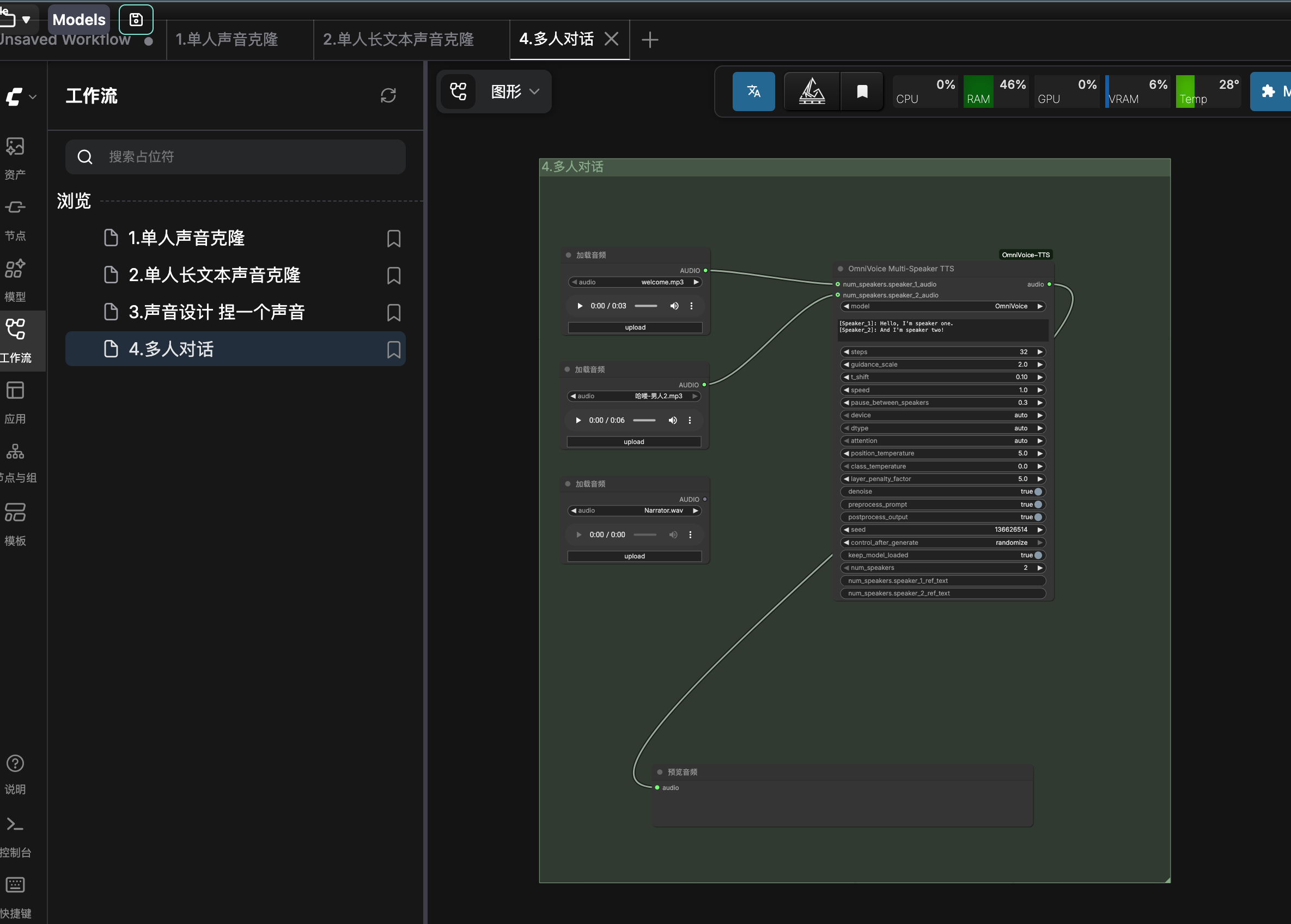
6. 功能四:多人对话
工作流文件: 4.多人对话.json
使用场景
生成两人或多人对话,适用于广播剧、有声漫画、客服对话等场景。
操作步骤
- 加载工作流 — 导入
4.多人对话.json - 设置说话人数量 — 调整
num_speakers参数(2-10 人) - 编写对话文本 — 使用
[Speaker_N]:标签标记每个说话人的台词,例如:
[Speaker_1]: 你好,我是小明。
[Speaker_2]: 你好小明,我是小红!
[Speaker_1]: 很高兴认识你!
[Speaker_2]: 我也是!
- 上传各说话人参考音频(可选) — 为每个说话人连接对应的
speaker_N_audio参考音频,可以为每个角色克隆不同的声音;不连接则使用随机生成的声音 - 调整说话人间暂停时间 —
pause_between_speakers参数控制说话人切换时的静音时长(默认 0.3 秒) - 点击 Queue Prompt 执行
小贴士
- 说话人编号从 1 开始:
[Speaker_1]、[Speaker_2]、[Speaker_3]... - 标签后的冒号
:是必须的 - 每个说话人上传不同的参考音频可以创建更丰富的角色区分
- 对话文本中可以混入非语言标签(见下方说明)
7. 参数详解
通用参数
| 参数 | 说明 | 推荐值 |
|---|---|---|
| model | 选择使用的模型 | OmniVoice-bf16(显存友好)或 OmniVoice(最高质量) |
| text | 要合成的文本内容 | 任意文本 |
| steps | 扩散步数,越高质量越好但越慢 | 16(快速)、32(平衡)、64(最佳质量) |
| guidance_scale | 文本对齐强度 | 默认 2.0,越高越严格按照文本生成 |
| speed | 语速 | 1.0 正常,>1.0 加快,<1.0 减慢 |
| duration | 固定输出时长(秒) | 0 表示自动,设定时会覆盖 speed |
| seed | 随机种子 | 0 为随机,固定数字可复现结果 |
| device | 运行设备 | auto(自动选择)、cuda(GPU)、cpu |
| dtype | 精度 | auto、bf16(推荐)、fp16、fp32 |
| attention | 注意力后端 | auto(默认)、eager、sage_attention(需 SM80+ GPU) |
高级参数
| 参数 | 说明 | 推荐值 |
|---|---|---|
| position_temperature | 掩码位置选择的随机性 | 0 为确定性,5.0 为默认平衡值 |
| class_temperature | 采样的随机性 | 0 为确定性,越高变化越多 |
| layer_penalty_factor | 深层码本惩罚因子 | 默认 5.0,通常不需要调整 |
| denoise | 添加去噪 token 以获得更干净输出 | 建议开启 True |
| preprocess_prompt | 预处理参考音频(去静音、加标点) | 建议开启 True |
| postprocess_output | 后处理输出音频(去除长静音) | 建议开启 True |
| keep_model_loaded | 保持模型在显存中 | True 可加快连续生成,显存不足时设为 False |
声音克隆专用参数
| 参数 | 说明 |
|---|---|
| ref_audio | 参考音频(3-15 秒),必填(长文本节点中可选) |
| ref_text | 参考音频的文本内容,留空自动识别 |
长文本专用参数
| 参数 | 说明 |
|---|---|
| words_per_chunk | 每块词数,0 表示不分块 |
多人对话专用参数
| 参数 | 说明 |
|---|---|
| num_speakers | 说话人数量(2-10) |
| pause_between_speakers | 说话人之间的静音秒数 |
| speaker_N_audio | 第 N 个说话人的参考音频(可选) |
| speaker_N_ref_text | 第 N 个说话人参考音频的文本(可选) |
8. 非语言标签(笑声、叹气等)
在文本中直接插入以下标签,可以生成丰富的非语言表达:
| 标签 | 效果 |
|---|---|
[laughter] | 笑声 |
[sigh] | 叹气 |
[sniff] | 吸鼻子 |
[question-en] / [question-ah] / [question-oh] | 疑问语气 |
[surprise-ah] / [surprise-oh] / [surprise-wa] / [surprise-yo] | 惊讶语气 |
[dissatisfaction-hnn] | 不满 |
[confirmation-en] | 确认 |
使用示例
[laughter] 你真是把我逗乐了![sigh] 我完全没想到会这样。
[Speaker_1]: [surprise-oh] 真的吗?我不敢相信!
[Speaker_2]: [confirmation-en] 是的,这是真的。
9. 声音设计属性参考
完整示例
female, young, high pitch, british accent, whisper
male, elderly, low pitch, american accent
female, middle-aged, medium pitch, 广东话
组合建议
- 温柔女声:
female, young, medium pitch - 成熟男声:
male, middle-aged, low pitch - 可爱童声:
female, child, high pitch - 神秘耳语:
female, young, whisper - 英伦绅士:
male, middle-aged, low pitch, british accent - 川渝方言:
male, middle-aged, 四川话
10. 常见问题 FAQ
Q1:首次运行卡住很久不动?
A: 首次运行会自动下载模型(约 2-4GB),请耐心等待。可以在 ComfyUI 的控制台查看下载进度。如果下载速度很慢,可以在启动 ComfyUI 前设置国内镜像:
export HF_ENDPOINT="https://hf-mirror.com"
Q2:提示显存不足(CUDA Out of Memory)?
A: 尝试以下方法:
- 将
dtype设置为bf16或fp16 - 将
keep_model_loaded设置为False - 减少
steps参数(如从 32 降到 16) - 使用
device = cpu(速度较慢但不占用显存) - 选择
OmniVoice-bf16模型而非OmniVoice
Q3:Whisper 每次都重新下载?
A: 使用 OmniVoice Whisper Loader 节点,并将其输出连接到 TTS 节点的 whisper_model 输入端,这样可以缓存模型避免重复下载。
Q4:克隆的声音不像?
A: 提高克隆质量的建议:
- 使用更清晰的参考音频(无背景噪音)
- 参考音频时长 5-15 秒效果最佳
- 手动填写
ref_text(参考音频的准确文本) - 增加
steps到 32 或 64 - 尝试不同的
seed值
Q5:生成的音频有杂音或断裂?
A:
- 确保
denoise参数为True - 确保
postprocess_output参数为True - 增加
steps参数提高质量 - 尝试调整
guidance_scale(默认 2.0)
Q6:支持哪些语言?
A: 支持 600+ 种语言,包括中文(普通话及各地方言)、英语、日语、韩语、法语、德语、西班牙语等绝大多数语言。直接在 text 中输入对应语言文本即可。
Q7:如何生成固定时长的音频?
A: 设置 duration 参数为需要的秒数(如 5.0 表示 5 秒)。注意:设定时长会覆盖 speed 参数。
Q8:安装后出现导入错误?
A: 完全重启 ComfyUI 以重新加载 Python 模块。如果仍然报错,检查控制台日志中是否有 omnivoice import failed 相关提示,可能需要手动运行:
pip install --no-deps omnivoice
Q9:Windows 保存音频时 FFmpeg 报错?
A: 在 ComfyUI 启动脚本中将 FFmpeg 的 bin/ 文件夹添加到系统 PATH,或使用 WAV 格式的音频保存节点。
Q10:如何复现上次生成的结果?
A: 设置固定的 seed 值(不使用 0),并保持所有其他参数不变,即可复现相同的结果。
Q11:长文本生成中断或不完整?
A:
- 使用
OmniVoice Longform TTS节点(而非 Voice Clone 节点) - 确保
words_per_chunk设置合理(默认 100) - 检查文本中是否有特殊字符或格式问题
Q12:多人对话中某个说话人的声音不对?
A:
- 检查文本中的
[Speaker_N]:标签是否正确(注意编号从 1 开始) - 确保
num_speakers设置正确 - 为每个说话人上传对应的参考音频
- 检查参考音频的
ref_text是否准确
Q13:SageAttention 是什么?需要开启吗?
A: SageAttention 是一种 GPU 优化的注意力实现,可以加速推理。但需要 Ampere 架构(RTX 30 系列)或更新的显卡。如果你的显卡支持,安装 sageattention 后在 attention 参数中选择即可。一般用户使用 auto 或 eager 即可。
Q14:模型文件存在哪里?
A: 模型自动下载到以下目录:
ComfyUI/models/omnivoice/
ComfyUI/models/audio_encoders/
如果需要手动管理或释放空间,可以在此处操作。
附录:模型显存需求参考
| 精度 | 显存需求 | 说明 |
|---|---|---|
| fp32(OmniVoice) | ~8-12 GB | 最高质量 |
| bf16/fp16(OmniVoice-bf16) | ~4-6 GB | 推荐,质量与显存平衡 |
| CPU 卸载 | ~2-4 GB | 显存不足时使用,速度较慢 |
本手册基于 OmniVoice TTS ComfyUI 节点 v0.2.7 编写。如有问题,请查阅项目文档或提交 Issue。
 认证作者
认证作者
 支持自启动
支持自启动