 0
0video-subtitle-extractor视频字幕提取器 全智能加速优化版
镜像简介
本镜像提供video-subtitle-extractor视频字幕提取器的全智能加速优化版本,支持一键自动从视频中识别并提取高精度字幕文件。通过智能算法优化处理流程,大幅提升识别速度与准确率,适用于影视制作、在线教育、内容创作及多语言视频翻译等场景,为用户带来高效、便捷的字幕自动化生成体验。
一句指令开始使用说明:
1、打开jupyterlab,先打开终端;
2、输入如下指令: cd /root/video-subtitle-extractor && bash smart_run.sh
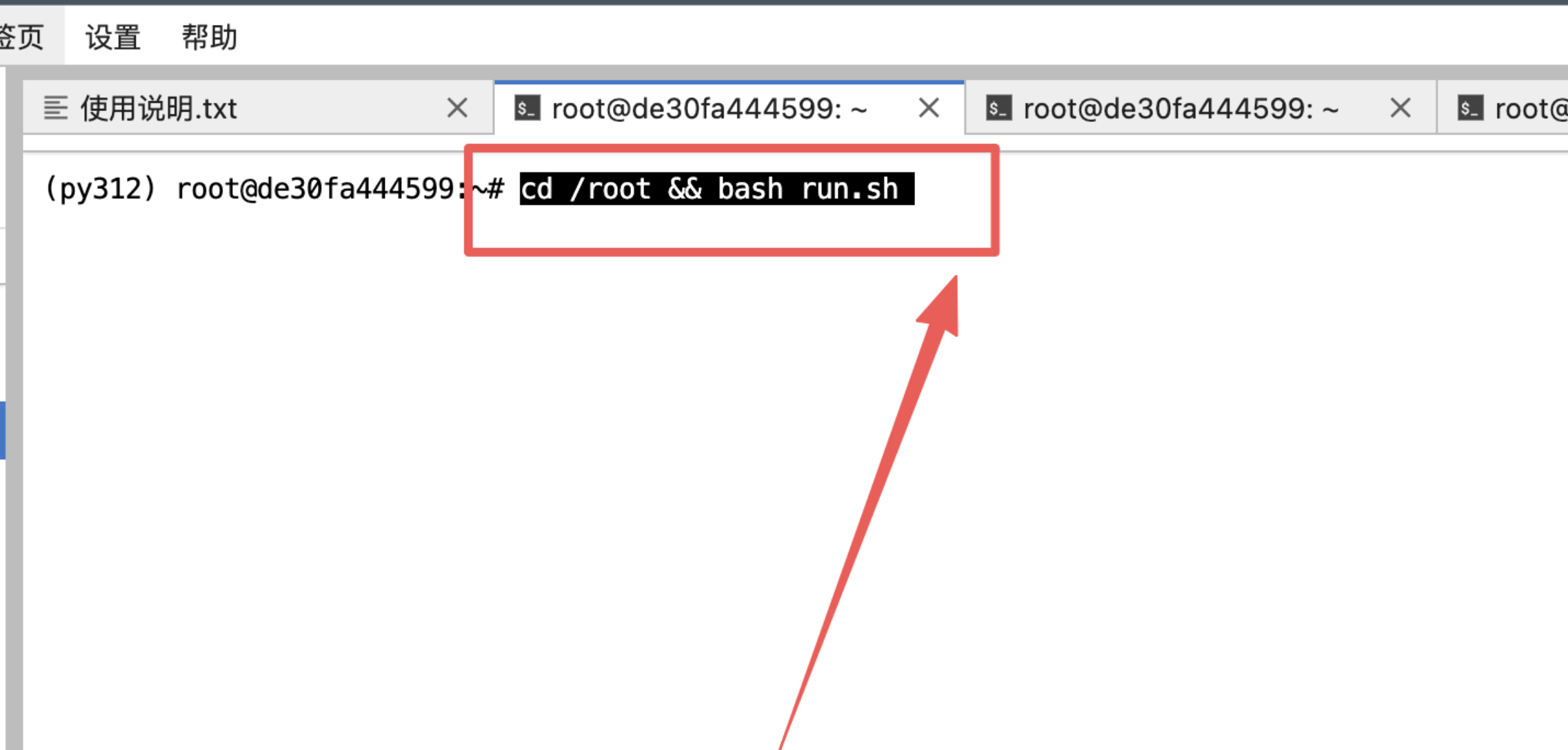
指令不是图片的,看下面👇!
test/test_cn.mp4(提取字幕的视频路径)
3、然后回车开始执行,等待。字幕txt,srt文件会在与视频路径一起同名输出。
cd /root/video-subtitle-extractor && bash smart_run.sh test/test_cn.mp4
视频字幕提取器 - 小白使用手册
🎯 一句话介绍:这是一个能把视频里"烧"进去的字幕提取出来,变成可编辑的文本文件的工具。
📖 目录
1. 这个工具是干什么的?
🤔 什么是"硬字幕"?
想象一下,你下载了一个视频,字幕是直接"印"在画面上的,就像照片上的水印一样,无法关闭或编辑。这种字幕就叫硬字幕(也叫内嵌字幕)。
┌─────────────────────────────────────┐
│ │
│ 视频画面 │
│ │
│ │
│ ┌───────────────────────────────┐ │
│ │ 这是硬字幕,无法关闭 │ │ ← 硬字幕(烧进画面)
│ └───────────────────────────────┘ │
└─────────────────────────────────────┘
✨ 这个工具能做什么?
本工具可以:
- 识别视频中的硬字幕 - 自动找到字幕在哪里
- 提取成文本文件 - 把字幕变成可编辑的文本
- 生成带时间轴的SRT文件 - 可以重新挂载到视频上
- 支持87种语言 - 中文、英文、日文、韩文...都能识别
💡 使用场景
- ✅ 提取外语视频字幕用于翻译
- ✅ 保存视频教程的文字笔记
- ✅ 提取电影台词用于学习
- ✅ 制作多语言字幕版本
- ✅ 字幕二次编辑和排版
Linux用户:
#### 步骤2:设置参数
界面说明:
┌────────────────────────────────────────────────────────────┐ │ Video Subtitle Extractor │ ├────────────────────────────────────────────────────────────┤ │ │ │ 视频路径:[___________________] [浏览...] ← 点这里选视频 │ │ │ │ 字幕语言:[中文 ▼] ← 选择字幕的语言 │ │ │ │ 提取模式: │ │ ○ 快速模式 (fast) - 速度最快,可能漏字幕 │ │ ● 自动模式 (auto) - 推荐,平衡速度和准确度 ← 推荐 │ │ ○ 精准模式 (accurate) - 最准确,速度最慢 │ │ │ │ 字幕区域: │ │ ○ 自动检测 ← 推荐新手 │ │ ○ 手动选择 │ │ │ │ [开始提取] [取消] │ │ │ └────────────────────────────────────────────────────────────┘
#### 步骤3:选择视频文件
1. 点击"浏览..."按钮
2. 找到你的视频文件(支持MP4、AVI、MKV等)
3. 选中后点击"打开"
#### 步骤4:选择字幕语言
从下拉菜单选择:
- 简体中文
- 繁体中文
- English
- 日本語
- 한국어
- 等等...(共87种语言)
#### 步骤5:开始提取
1. 点击"开始提取"按钮
2. 等待处理(会显示进度条)
3. 处理完成后,字幕文件会保存在 `outputs/` 目录下
---
### ⚡ 方法二:智能命令行(最快速度)
如果你有NVIDIA显卡,使用智能脚本可以获得**最快速度**!
#### Linux用户:
```bash
# 1. 激活环境
conda activate videoEnv
# 2. 运行智能脚本
./smart_run.sh /path/to/your/video.mp4
Windows用户:
抱歉,智能脚本目前只支持Linux。Windows用户请使用GUI或普通命令行。
智能脚本的优势:
- ✅ 自动检测字幕区域 - 无需手动选择
- ✅ 显存自适应优化 - 榨干GPU性能,防止爆显存
- ✅ 实时进度显示 - 清楚看到处理进度
- ✅ 速度提升2-5倍 - 相比默认配置
运行效果预览:
╔═══════════════════════════════════════════════════════════════╗
║ ║
║ 智能视频字幕提取器 - Smart Subtitle Extractor ║
║ ║
║ • 自动检测字幕区域 ║
║ • GPU显存自适应优化 ║
║ • 极致速度提取(防OOM) ║
║ ║
╚═══════════════════════════════════════════════════════════════╝
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
第一阶段:环境准备与验证
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
[INFO] 视频路径: /root/video-subtitle-extractor/test/test_cn.mp4
[SUCCESS] 视频文件验证通过
[INFO] 正在分析视频...
[SUCCESS] 视频信息获取成功
• 分辨率: 1920x1080
• 帧数: 434
• 帧率: 25.00 fps
• 时长: 17.4 秒
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
第二阶段:GPU显存智能分析与参数优化
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
[INFO] GPU型号: Tesla T4
[INFO] 总显存: 15109 MB
[INFO] 已用显存: 0 MB
[INFO] 可用显存: 15109 MB
[SUCCESS] 显存充足,开始计算最优参数...
╔════════════════════════════════════════════════════════╗
║ 智能优化参数(基于15109MB显存) ║
╠════════════════════════════════════════════════════════╣
║ REC_BATCH_NUM : 55 (原值: 40)
║ MAX_BATCH_SIZE : 68 (原值: 50)
║ GPU_MEM : 8476 MB (原值: 8000)
║ EXTRACT_FREQUENCY : 5 (原值: 5)
╠════════════════════════════════════════════════════════╣
║ 预估显存占用 : ~12400 MB
║ 安全边界 : 0.8x (预留20%)
║ 预期速度提升 : 1.4x (相比默认配置)
╚════════════════════════════════════════════════════════╝
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
第五阶段:极速字幕提取
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
[INFO] 开始提取字幕...
[INFO] 正在加载OCR模型和处理视频帧...
✓ 使用GPU模式
→ 提取帧数: 87
⟳ 识别中... 10%
⟳ 识别中... 25%
⟳ 识别中... 50%
⟳ 识别中... 75%
⟳ 识别中... 100%
✓ 识别完成
[SUCCESS] 字幕提取完成!
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
📁 字幕文件输出路径 (Output Files)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
[SRT字幕文件]
/root/video-subtitle-extractor/outputs/test_cn_20251114_123045/subtitle/raw_vsf.srt
大小: 1234 bytes
[TXT纯文本文件]
/root/video-subtitle-extractor/outputs/test_cn_20251114_123045/subtitle/raw.txt
大小: 567 bytes
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
╔═══════════════════════════════════════════════════════════════╗
║ 🎉 提取成功完成! ║
╚═══════════════════════════════════════════════════════════════╝
❓ 运行问题
Q4: 启动后没有识别到字幕
可能原因:
- ❌ 字幕区域选择不正确
- ❌ 字幕语言选择错误
- ❌ 字幕太小或模糊
解决方法:
- 使用GUI的"预览"功能,确认字幕区域
- 检查语言设置是否正确
- 提高视频清晰度或使用精准模式
Q5: 提示"CUDA out of memory"(显存不足)
解决方法:
- 关闭其他占用GPU的程序
- 降低batch size:
# 编辑 backend/config.py REC_BATCH_NUM = 10 # 改小这个值 - 或者使用CPU模式
Q6: 提取速度非常慢
可能原因:
- 使用了CPU模式
- batch size太小
- 视频分辨率太高
解决方法:
- 安装GPU版本(速度提升10倍+)
- 使用智能脚本(自动优化参数)
- 使用"快速模式"而非"精准模式"
Q7: 提取的字幕有错别字
这是正常的!OCR识别不可能100%准确。
解决方法:
- 使用精准模式提高识别率
- 手动编辑生成的字幕文件
- 添加自定义错词映射:
// 编辑 backend/configs/typoMap.json { "l'm": "I'm", "威筋": "威胁" }
❓ 其他问题
Q8: 支持哪些视频格式?
支持几乎所有常见格式:
- ✅ MP4
- ✅ AVI
- ✅ MKV
- ✅ MOV
- ✅ FLV
- ✅ WMV
- 等等...
Q9: 生成的字幕文件在哪里?
在项目目录的 outputs/ 文件夹下:
outputs/
└── 视频名称_时间戳/
├── frames/ ← 提取的视频帧
└── subtitle/ ← 字幕文件
├── raw.txt ← 纯文本字幕
└── raw_vsf.srt ← 带时间轴的SRT字幕
Q10: SRT字幕如何使用?
SRT字幕可以:
- 用PotPlayer等播放器挂载到视频上
- 导入到剪辑软件(剪映、PR等)
- 用字幕编辑器修改
- 上传到视频平台作为外挂字幕
7. 进阶使用
🔧 配置文件说明
配置文件位置:backend/config.py
重要参数:
# 每秒提取帧数(值越大越精确,但速度越慢)
EXTRACT_FREQUENCY = 5 # 推荐: 3-5
# 每批次OCR识别文本框数量(取决于GPU显存)
REC_BATCH_NUM = 40 # GPU 4GB: 20, 8GB: 40, 12GB+: 60
# 置信度阈值(低于此值的识别结果会被丢弃)
DROP_SCORE = 0.75 # 推荐: 0.7-0.8
# 文本相似度阈值(去重时判断是否为同一字幕)
THRESHOLD_TEXT_SIMILARITY = 0.8 # 推荐: 0.75-0.85
📝 自定义错词替换
编辑 backend/configs/typoMap.json:
{
"l'm": "I'm",
"威筋": "威胁",
"性感荷官在线发牌": ""
}
- 键:要替换的文本
- 值:替换后的文本(空字符串表示删除)
🐛 报告问题 微信群:
bug反馈可以加入科哥专属群交流➕ 广告勿进!

提Issue时请包含:
提Issue时请包含:
- 操作系统版本
- Python版本
- 错误截图或日志
- 复现步骤
使用智能脚本(自动检测)
智能脚本会自动分析视频,找到字幕区域,无需手动选择。
10. 常见使用场景案例
场景1:提取美剧字幕学英语
# 1. 准备高清视频(1080p最佳)
# 2. 使用智能脚本
./smart_run.sh /path/to/friends_s01e01.mp4
# 3. 得到SRT字幕文件
# 4. 用记事本打开,复制单词到Anki
场景2:提取B站视频字幕
# 1. 使用下载工具下载B站视频(如you-get)
you-get https://www.bilibili.com/video/BV1xx411c7mD/
# 2. 提取字幕
./smart_run.sh downloaded_video.mp4
# 3. 整理成笔记
场景3:制作双语字幕
# 1. 先提取原语言字幕
./smart_run.sh movie_cn.mp4 # 中文字幕
# 2. 翻译SRT文件(用字幕编辑器)
# 3. 合并成双语字幕
11. 常用命令速查表
智能脚本(Linux)
./smart_run.sh /path/to/video.mp4
查看GPU状态
nvidia-smi
13. 附录
A. 支持的语言列表
中文简体 (ch) 英语 (en) 日语 (japan)
中文繁体 (chinese_cht) 韩语 (korean) 法语 (french)
德语 (german) 俄语 (ru) 西班牙语 (es)
葡萄牙语 (pt) 阿拉伯语 (ar) 意大利语 (it)
荷兰语 (dutch) 泰语 (th) 越南语 (vi)
印地语 (hi) 土耳其语 (tr) 波兰语 (pl)
等等... 共87种语言
完整列表请查看 backend/config.py 中的 LANG_DICT
B. 提取模式对比
| 模式 | 速度 | 准确度 | 显存占用 | 适用场景 |
|---|---|---|---|---|
| 快速 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | 低 | 快速预览、低配置电脑 |
| 自动 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 中 | 日常使用(推荐) |
| 精准 | ⭐⭐ | ⭐⭐⭐⭐⭐ | 高 | 专业字幕制作 |
C. 性能参考数据
测试视频:1080p,17秒,434帧
| 配置 | 提取模式 | 耗时 | 速度 |
|---|---|---|---|
| Intel i7 (CPU) | 快速 | ~120秒 | 3.6帧/秒 |
| Intel i7 (CPU) | 精准 | ~300秒 | 1.4帧/秒 |
| GTX 1060 (GPU) | 自动 | ~40秒 | 10.9帧/秒 |
| RTX 3080 (GPU) | 自动 | ~15秒 | 28.9帧/秒 |
| Tesla T4 + 智能脚本 | 自动 | ~10秒 | 43.4帧/秒 |
🎉 结语
恭喜你!读到这里,你已经掌握了视频字幕提取器的所有使用方法。
如果这个工具帮到了你,请给项目点个⭐Star: https://github.com/YaoFANGUK/video-subtitle-extractor
祝使用愉快!🚀
 认证作者
认证作者