TurboDiffusion清华大学等推出的视频生成加速框架 webUI二次修改构建by科哥
ai视频生成速度提升百倍!基于wan2.1,wan2.2加速ai优化推理速度
 5
50元/小时
v1.3
v1.2
v1.1
TurboDiffusion清华大学等推出的视频生成加速框架
- 支持图生视频增加批量生成功能
- 本镜像适合 40系列 48gb显存机器测试通过使用
- 其他机器待测试 推荐 40系列 48gb显存机器使用
- 基于wan2.1,wan2.2加速ai优化推理速度
镜像简介
- TurboDiffusion 是清华大学、生数科技和加州大学伯克利分校联合推出的视频生成加速框架。
- 框架通过 SageAttention、SLA(稀疏线性注意力)和 rCM(时间步蒸馏)等技术
- 将视频生成速度提升 100~200 倍,能在单张 RTX 5090 显卡上将原本 184 秒的生成任务缩短到 1.9 秒
- 框架降低了视频生成的门槛,推动行业变革,让创意成为核心竞争力。
镜像使用教程
创建实例后点击【SD-WebUI】即可进入操作页面
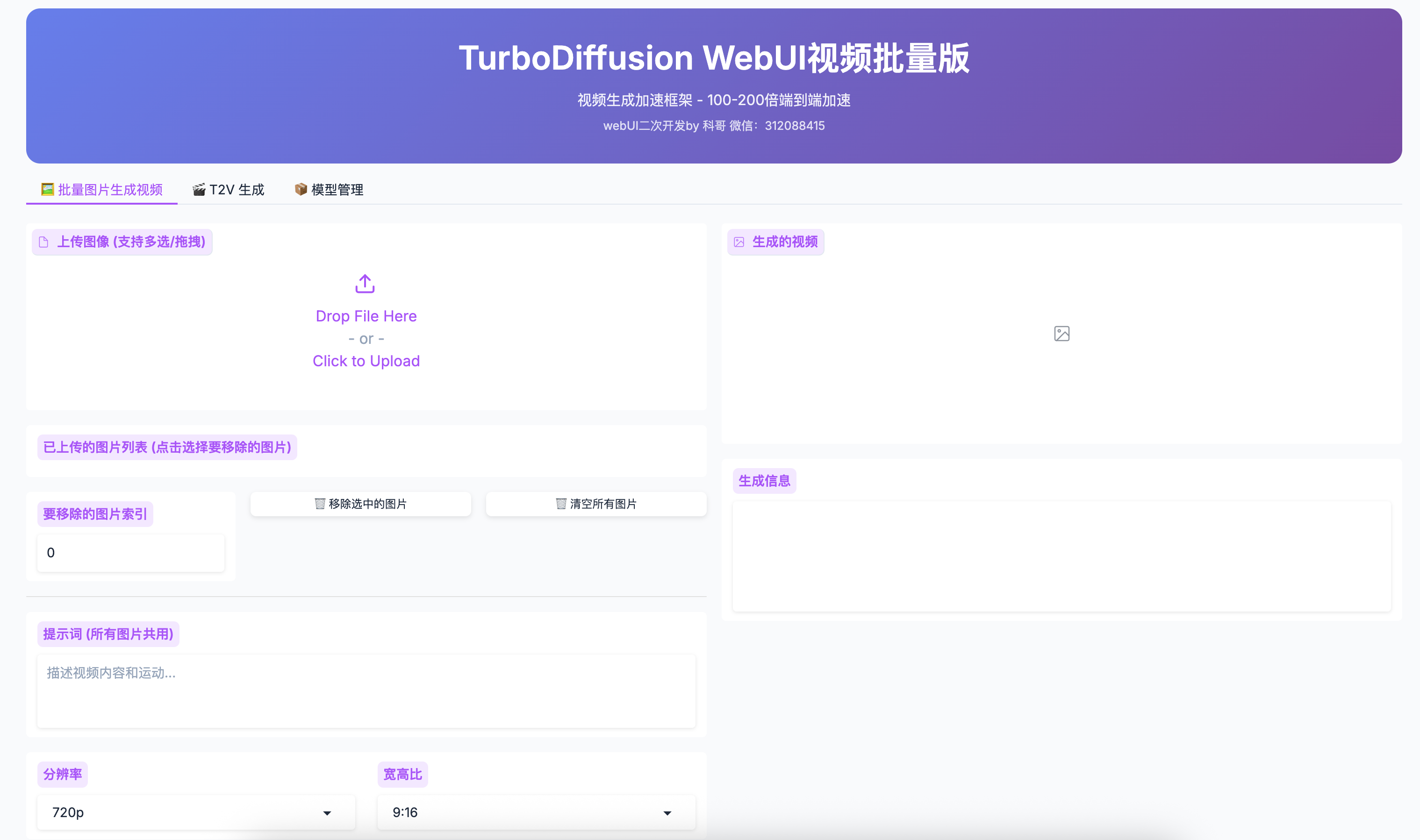
webUI使用界面
使用界面;
相关链接
- 项目源码:
TurboDiffusion 用户使用手册
目录
快速开始
启动 WebUI
cd /root/TurboDiffusion
export PYTHONPATH=turbodiffusion
python webui/app.py
访问浏览器打开 WebUI 界面(默认端口会在终端显示)。
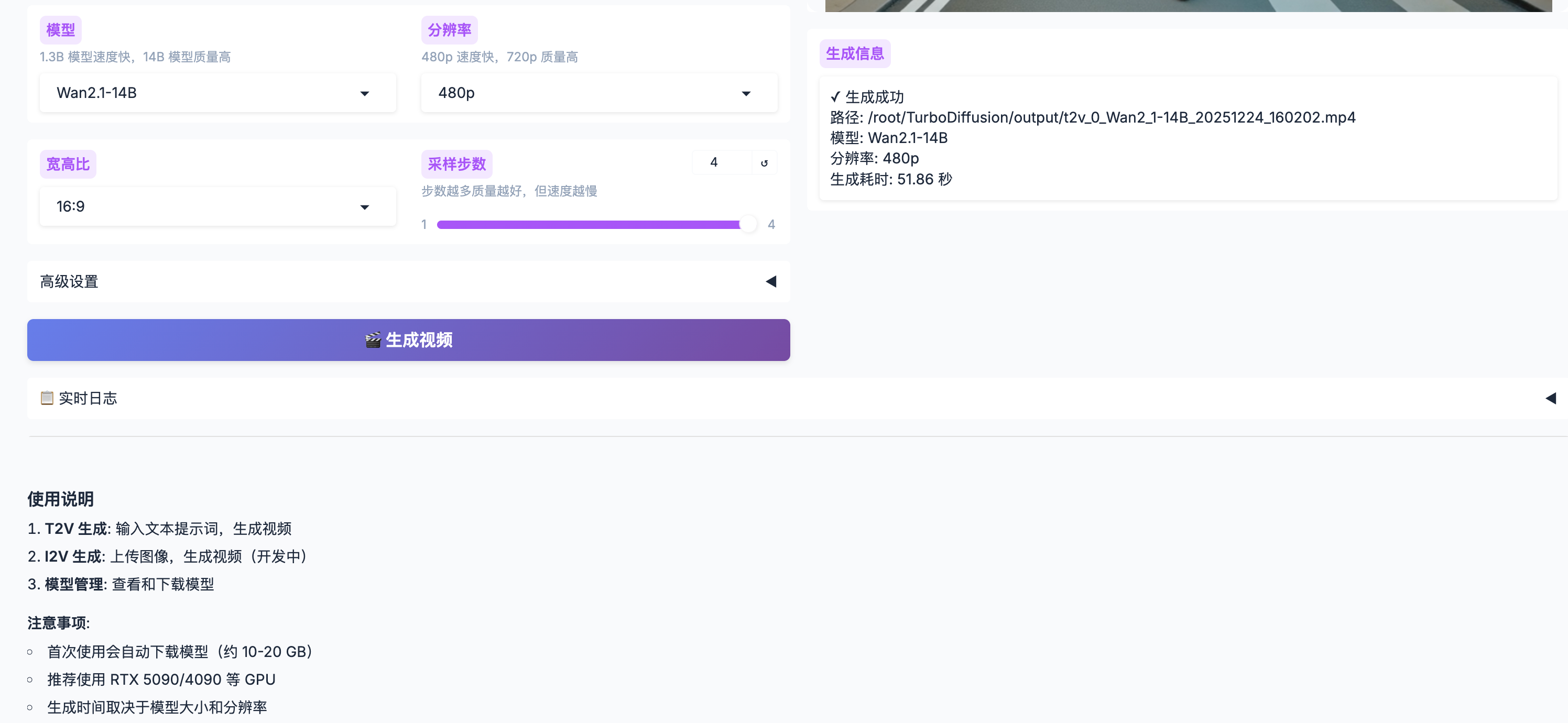
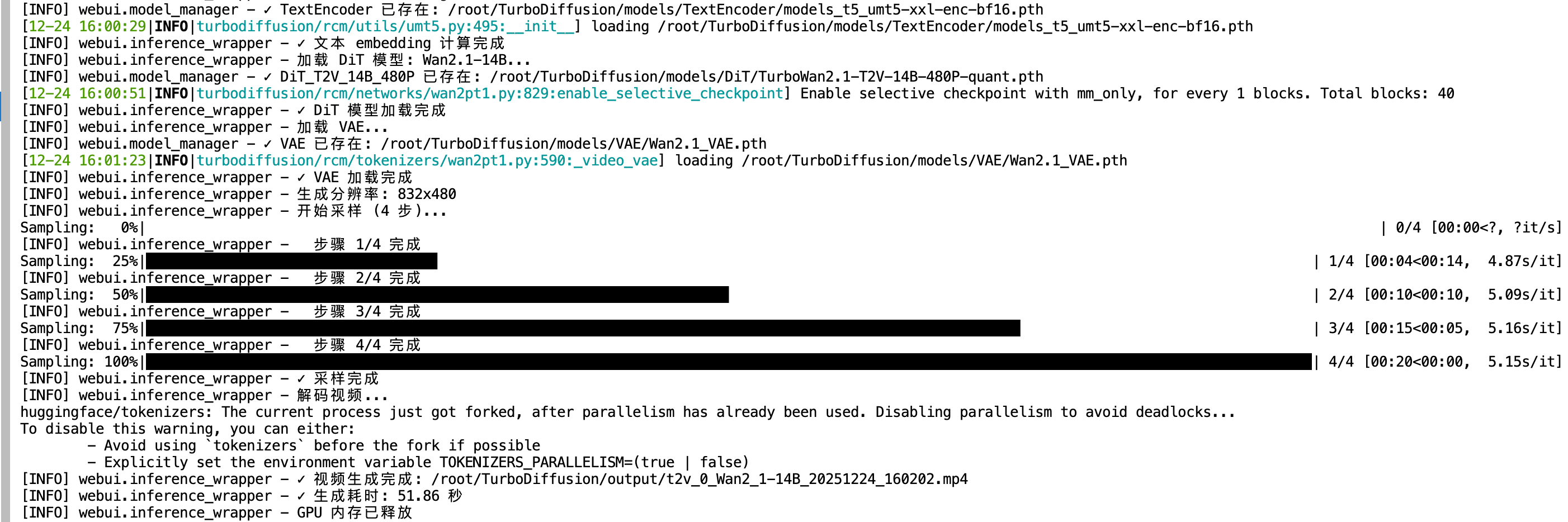
T2V 文本生成视频
基础使用
-
选择模型
Wan2.1-1.3B: 轻量级模型,适合快速生成Wan2.1-14B: 大型模型,质量更高(需要更多显存)
-
输入提示词
示例: 一位时尚的女性走在东京街头,街道两旁是温暖发光的霓虹灯和动画城市标牌 -
设置参数
- 分辨率: 480p (推荐) 或 720p
- 宽高比: 16:9, 9:16, 1:1, 4:3, 3:4
- 采样步数: 1-4 步(推荐 4 步)
- 随机种子: 0 为随机,固定数字可复现结果
-
点击生成
- 等待生成完成
- 视频保存在
outputs/目录
提示词技巧
好的提示词特征:
- 具体描述场景、人物、动作
- 包含视觉细节(颜色、光线、风格)
- 使用动态词汇(走、跑、飞、旋转)
示例提示词:
✓ 好: 一只橙色的猫在阳光明媚的花园里追逐蝴蝶,花朵随风摇曳
✗ 差: 猫和蝴蝶
✓ 好: 未来城市的空中交通,飞行汽车在摩天大楼间穿梭,霓虹灯闪烁
✗ 差: 未来城市
✓ 好: 海浪拍打着岩石海岸,日落时分,金色的光芒洒在水面上
✗ 差: 海边日落
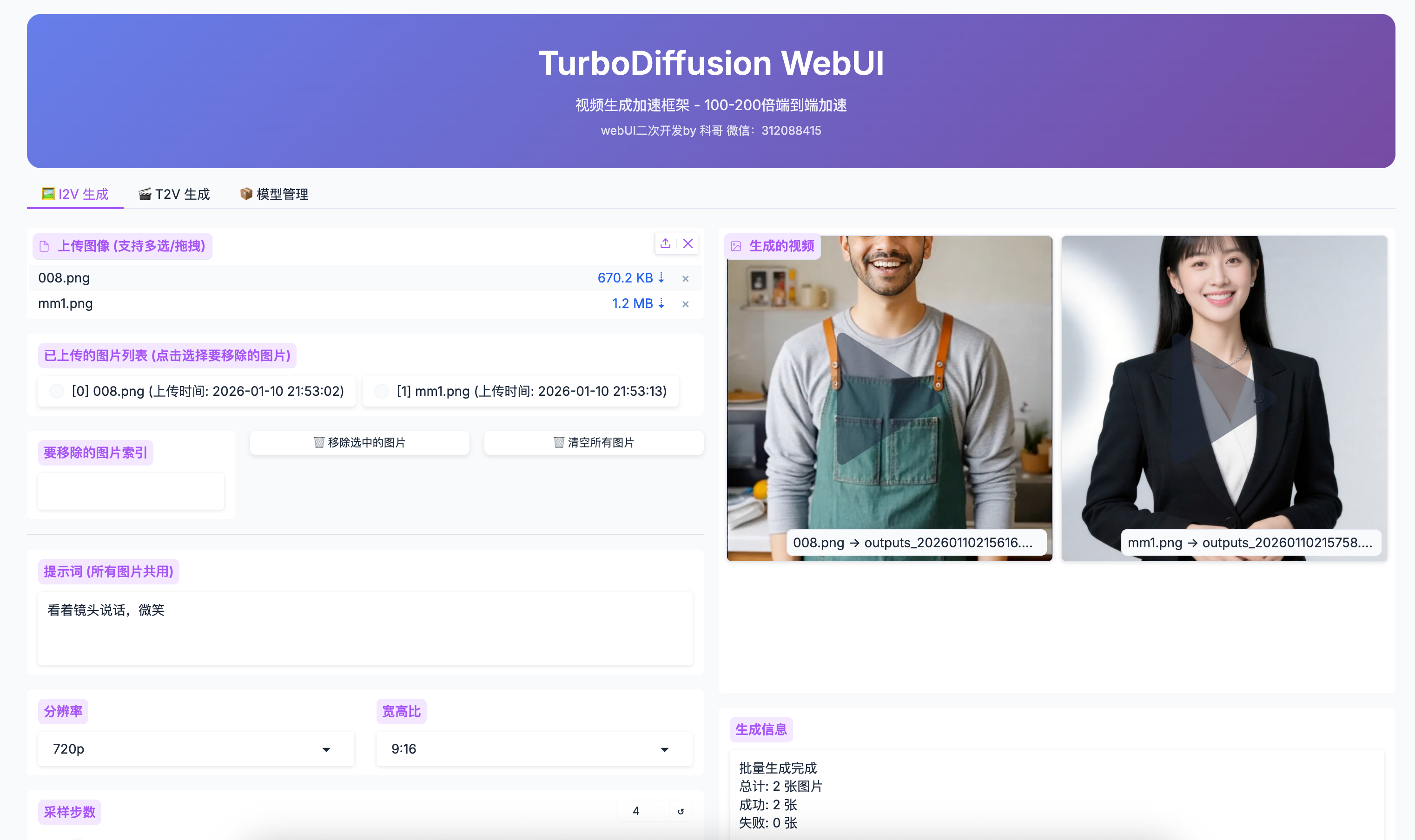
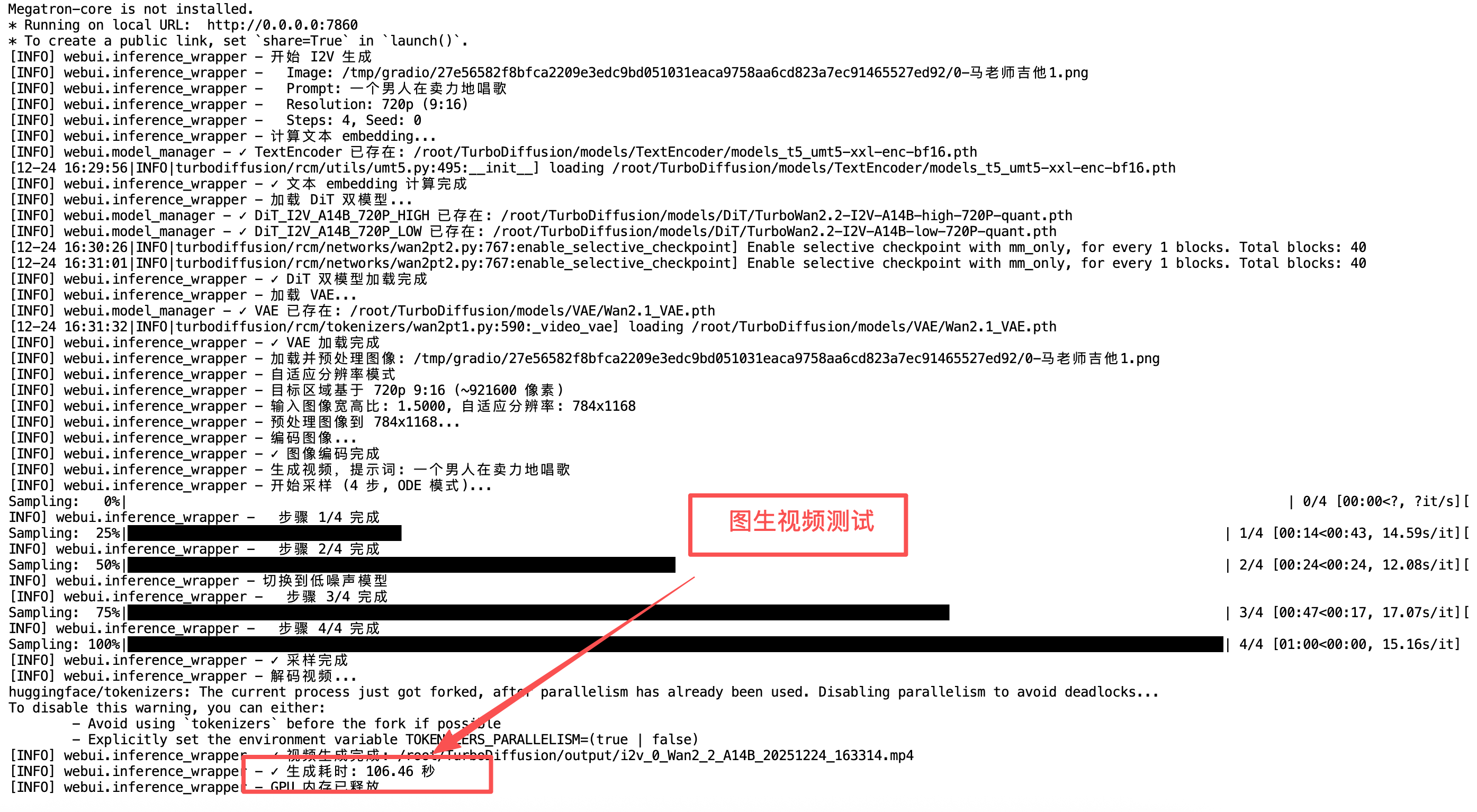
I2V 图像生成视频
功能说明
✅ I2V 功能已完整实现并可用!
I2V (Image-to-Video) 可以将静态图像转换为动态视频,支持:
- 双模型架构(高噪声和低噪声模型自动切换)
- 自适应分辨率(根据输入图像宽高比自动调整)
- ODE/SDE 采样模式选择
- 完整的参数控制
基础使用
-
上传图像
- 支持格式: JPG, PNG
- 推荐分辨率: 720p 或更高
- 任意宽高比(自适应模式会自动调整)
-
输入提示词
- 描述图像中物体的运动和变化
- 描述相机运动(推进、拉远、环绕等)
- 描述环境变化(光影、天气等)
-
设置参数
- 分辨率: 720p(当前仅支持)
- 宽高比: 16:9, 9:16, 1:1, 4:3, 3:4
- 采样步数: 1-4 步(推荐 4 步)
- 随机种子: 0 为随机,固定数字可复现结果
-
高级设置(可选)
- 模型切换边界: 0.5-1.0(默认 0.9)
- ODE 采样: 启用(推荐)或禁用
- 自适应分辨率: 启用(推荐)或禁用
- 初始噪声强度: 100-300(默认 200)
-
点击生成
- 等待生成完成(约 1-2 分钟)
- 视频保存在
output/目录
提示词示例
相机运动:
相机缓慢向前推进,树叶随风摇摆
相机环绕拍摄,展示建筑的全貌
镜头从远处拉近,聚焦到人物面部
物体运动:
她抬头看向天空,然后回头看向镜头
云层快速移动,光影变化
海浪拍打着岩石,水花四溅
环境变化:
日落时分,天空颜色从蓝色渐变到橙红色
雨滴开始落下,地面逐渐湿润
风吹动窗帘,阳光透过窗户洒进房间
I2V 特有参数
Boundary (模型切换边界)
- 范围: 0.5 - 1.0
- 0.9 (默认): 在 90% 时间步切换到低噪声模型
- 0.7: 更早切换,可能提高细节
- 1.0: 不切换,仅使用高噪声模型
ODE Sampling (ODE 采样)
- 启用 (推荐): 确定性采样,结果更锐利
- 禁用: 随机性采样(SDE),结果更鲁棒但稍软
Adaptive Resolution (自适应分辨率)
- 启用 (推荐): 根据输入图像宽高比自动计算输出分辨率
- 禁用: 使用固定分辨率(可能导致图像变形)
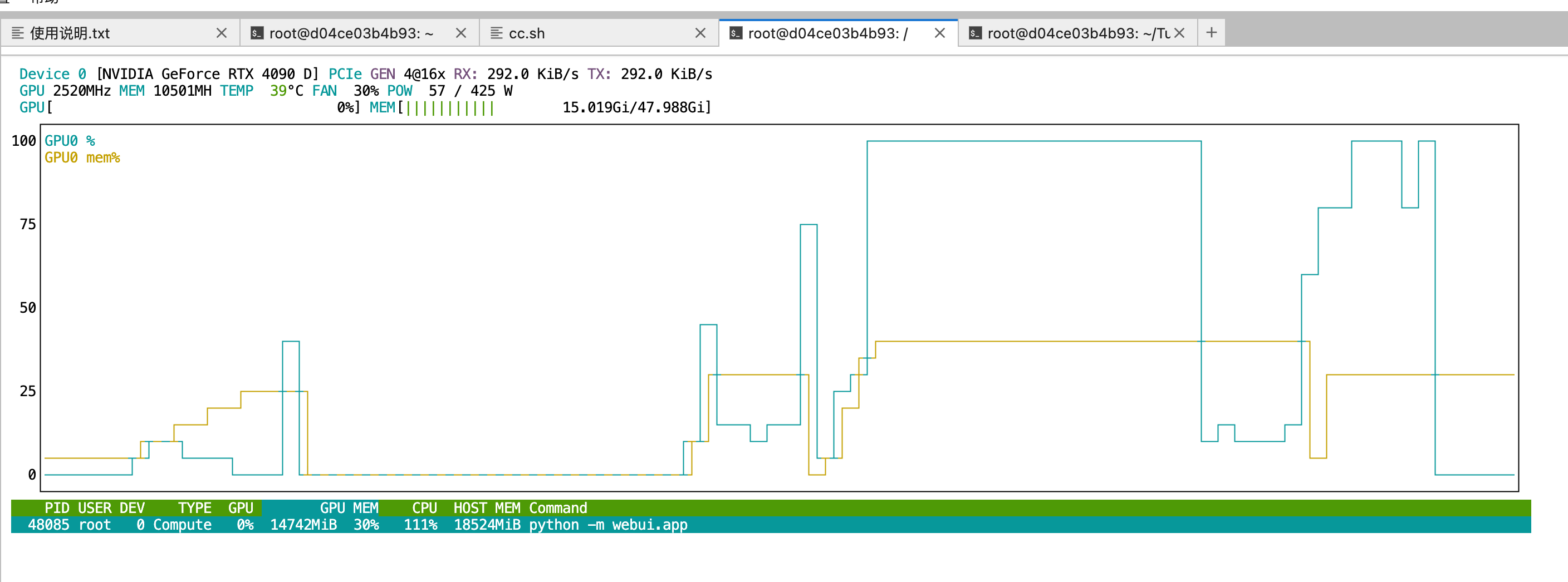
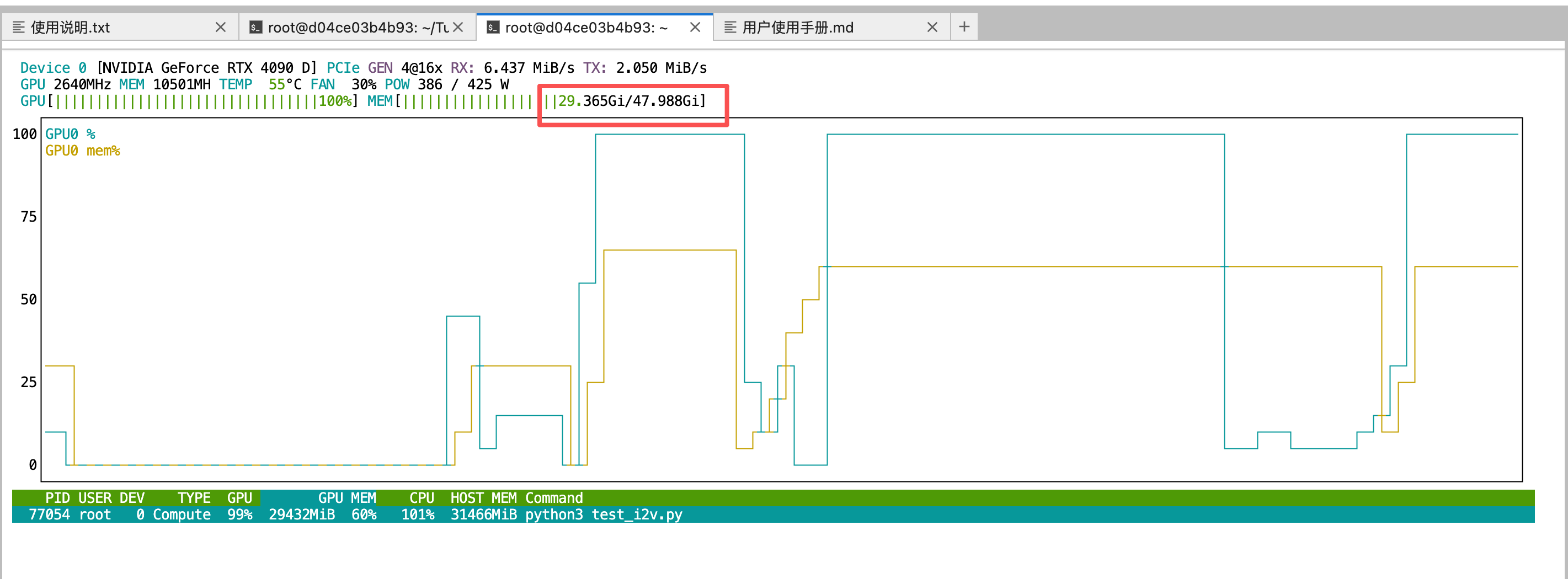
显存需求
I2V 使用双模型架构(高噪声 + 低噪声),显存需求:
- 最小: ~24GB(启用量化)
- 推荐: ~40GB(完整精度)
- 适用 GPU: RTX 5090, RTX 4090, H100, A100
性能优化
加速技巧:
- 启用量化(
quant_linear=True) - 使用 SageSLA 注意力
- 减少采样步数到 2 步(快速预览)
- 使用较小的帧数(如 49 帧)
质量优化:
- 使用 4 步采样
- 提高 SLA TopK 到 0.15
- 使用 ODE 采样模式
- 启用自适应分辨率
参数详解
核心参数
1. Model (模型)
T2V 模型:
-
Wan2.1-1.3B:
- 显存需求: ~12GB
- 生成速度: 快
- 适用场景: 快速预览、测试提示词
-
Wan2.1-14B:
- 显存需求: ~40GB
- 生成速度: 较慢
- 适用场景: 高质量最终输出
I2V 模型:
- Wan2.2-A14B (双模型):
- 显存需求: ~24GB(量化)/ ~40GB(完整)
- 生成速度: 较慢(需加载两个模型)
- 适用场景: 图像转视频
- 特点: 高噪声和低噪声模型自动切换
2. Resolution (分辨率)
-
480p: 854×480 像素
- 速度快,显存占用低
- 适合快速迭代
-
720p: 1280×720 像素
- 质量更高,细节更丰富
- 需要更多显存和时间
3. Aspect Ratio (宽高比)
- 16:9: 标准横屏(电影、视频)
- 9:16: 竖屏(手机、短视频)
- 1:1: 正方形(社交媒体)
- 4:3: 传统电视比例
- 3:4: 竖版传统比例
4. Steps (采样步数)
- 1 步: 最快,质量较低
- 2 步: 平衡速度和质量
- 4 步: 推荐,质量最佳
5. Seed (随机种子)
- 0: 每次生成不同结果
- 固定数字: 相同提示词生成相同视频(可复现)
高级参数
Attention Type (注意力机制)
- sagesla (推荐): 最快,需要 SpargeAttn
- sla: 较快,内置实现
- original: 最慢,完整注意力
SLA TopK
- 范围: 0.05 - 0.2
- 0.1 (默认): 平衡速度和质量
- 0.15: 质量更高,速度稍慢
- 0.05: 速度最快,质量可能下降
Quant Linear (量化)
- True: RTX 5090/4090 必须启用
- False: H100/A100 推荐禁用
Num Frames (帧数)
- 默认: 81 帧 (~5 秒 @ 16fps)
- 可调整范围: 33-161 帧
Sigma Max (初始噪声)
- T2V 默认: 80
- I2V 默认: 200
- 更高值 = 更多随机性
最佳实践
1. 快速迭代工作流
第一轮: 测试提示词
├─ Model: Wan2.1-1.3B
├─ Resolution: 480p
├─ Steps: 2
└─ 快速验证创意
第二轮: 精细调整
├─ Model: Wan2.1-1.3B
├─ Resolution: 480p
├─ Steps: 4
└─ 调整提示词细节
第三轮: 最终输出
├─ Model: Wan2.1-14B (可选)
├─ Resolution: 720p
├─ Steps: 4
└─ 生成高质量成品
2. 显存优化
低显存 GPU (12-16GB):
- 使用 Wan2.1-1.3B
- 分辨率限制在 480p
- 启用
quant_linear - 关闭其他 GPU 程序
中等显存 GPU (24GB):
- 可使用 Wan2.1-1.3B @ 720p
- 或 Wan2.1-14B @ 480p
- 启用
quant_linear
高显存 GPU (40GB+):
- 可使用 Wan2.1-14B @ 720p
- 可禁用
quant_linear获得更好质量
3. 提示词优化
结构化提示词模板:
[主体] + [动作] + [环境] + [光线/氛围] + [风格]
示例:
一位宇航员 + 在月球表面漫步 + 地球在背景中升起 +
柔和的蓝色光芒 + 电影级画质
动态元素:
- 使用动词: 走、跑、飞、旋转、摇摆、流动
- 描述相机运动: 推进、拉远、环绕、俯视
- 添加环境动态: 风吹、水流、光影变化
4. 种子管理
保存好的种子:
提示词: 樱花树下的武士
种子: 42
结果: 优秀 ⭐⭐⭐⭐⭐
提示词: 赛博朋克城市夜景
种子: 1337
结果: 优秀 ⭐⭐⭐⭐⭐
常见问题
Q1: 生成速度慢怎么办?
A:
- 使用
sagesla注意力(确保已安装 SpargeAttn) - 降低分辨率到 480p
- 使用 1.3B 模型而非 14B
- 减少采样步数到 2 步
Q2: 显存不足 (OOM) 怎么办?
A:
- 启用
quant_linear=True - 使用更小的模型 (1.3B)
- 降低分辨率
- 减少帧数
- 确保使用 PyTorch 2.8.0(更高版本可能 OOM)
Q3: 生成结果不理想?
A:
- 增加采样步数到 4
- 使用更详细的提示词
- 尝试不同的随机种子
- 调整
sla_topk到 0.15 提升质量 - 使用更大的模型 (14B)
Q4: 如何复现之前的结果?
A:
- 记录使用的随机种子
- 使用相同的提示词
- 使用相同的模型和参数
- 种子为 0 时每次结果都不同
Q5: 视频保存在哪里?
A:
- 默认路径:
/root/TurboDiffusion/outputs/ - 文件名格式:
t2v_{seed}_{model}_{timestamp}.mp4 - 例:
t2v_42_Wan2_1_1_3B_20251224_153000.mp4
Q6: 可以生成多长的视频?
A:
- 默认: 81 帧 (~5 秒 @ 16fps)
- 可调整
num_frames参数 - 范围: 33-161 帧 (2-10 秒)
- 更长视频需要更多显存
Q7: 支持中文提示词吗?
A:
- 是的,完全支持中文
- 也支持英文和中英混合
- 模型使用 UMT5 文本编码器,多语言支持良好
Q8: 如何提高生成质量?
A:
- 使用 4 步采样
- 提高
sla_topk到 0.15 - 使用 720p 分辨率
- 使用 14B 模型(T2V)
- 编写详细的提示词
- 尝试多个种子选择最佳结果
Q9: I2V 和 T2V 有什么区别?
A:
- T2V: 从文本生成视频,适合创意内容
- I2V: 从图像生成视频,适合让静态图像动起来
- I2V 使用双模型架构,需要更多显存
- I2V 支持自适应分辨率,可根据输入图像调整
Q10: I2V 生成时间为什么比 T2V 长?
A:
- I2V 需要加载两个 14B 模型(高噪声 + 低噪声)
- 模型切换需要额外时间
- 图像编码和预处理需要时间
- 典型生成时间: ~110 秒(4 步采样)
Q11: 如何选择 ODE 还是 SDE 采样?
A:
- ODE(推荐): 确定性,结果更锐利,相同种子可复现
- SDE: 随机性,结果更鲁棒但稍软,每次略有不同
- 建议先用 ODE,如果结果不理想再尝试 SDE
Q12: 自适应分辨率是什么?
A:
- 根据输入图像的宽高比自动计算输出分辨率
- 保持目标区域面积不变(如 720p = 921600 像素)
- 避免图像变形和拉伸
- 推荐启用,除非需要固定尺寸输出
输出文件说明
视频文件
- 格式: MP4
- 编码: H.264
- 帧率: 16 fps
- 时长: ~5 秒 (81 帧)
文件命名
T2V:
t2v_{seed}_{model}_{timestamp}.mp4
I2V:
i2v_{seed}_Wan2_2_A14B_{timestamp}.mp4
示例:
t2v_0_Wan2_1_1_3B_20251224_153045.mp4
i2v_42_Wan2_2_A14B_20251224_162722.mp4
│ │ │ └─ 时间戳
│ │ └─ 模型名称
│ └─ 随机种子
└─ 生成类型 (t2v/i2v)
技术支持
日志查看
# 查看 WebUI 日志
tail -f webui_startup_latest.log
# 查看详细错误
cat webui_test.log
性能监控
# 监控 GPU 使用
nvidia-smi -l 1
# 查看显存占用
watch -n 1 nvidia-smi
问题反馈
- 查看 todo.md 了解已知问题
- 查看 CLAUDE.md 了解技术细节
- 查看 SAGESLA_INSTALL.md 了解安装问题
- 查看 I2V_IMPLEMENTATION.md 了解 I2V 技术细节
更新日志
2025-12-24
- ✓ 修复 SageSLA 安装问题
- ✓ 优化默认参数配置
- ✓ 添加用户使用手册
- ✓ 完整实现 I2V 功能
- 双模型架构(高噪声 + 低噪声)
- 自适应分辨率支持
- ODE/SDE 采样模式
- 完整的 WebUI 界面
- ✓ 添加启动脚本日志功能
祝您使用愉快!🎬
@鸡你太美 认证作者
认证作者
认证作者

镜像信息
已使用39 次
运行时长
20 H
 支持自启动
支持自启动镜像大小
40GB
最后更新时间
2026-05-08
支持卡型
48G RTX40系RTX40系RTX50系A800H20A10030903080Ti2080Ti2080P40V100S
+12
框架版本
CUDA版本
12.8
应用
JupyterLab: 8888
版本
v1.3
2026-05-08
v1.2
2026-04-27
v1.1
2026-04-27