GLM-4.7-Flash
GLM-4.7-Flash
 2
20元/小时
v1.0
GLM-4.7-Flash
镜像简介
GLM-4.7-Flash 是一个 30B 参数(30B-A3B MoE)的模型,为了在本地高效运行,Unsloth 提供了专门优化的 GGUF 量化版本。
GLM-4.7-Flash 是 Z.ai 最新的旗舰模型,在编码和工具调用方面表现出色。Unsloth 的动态量化(Dynamic Quantization)版本可以在保持高精度的同时大幅降低显存需求。
镜像使用教程
创建实例后,点击【Jupyterlab】,进入终端
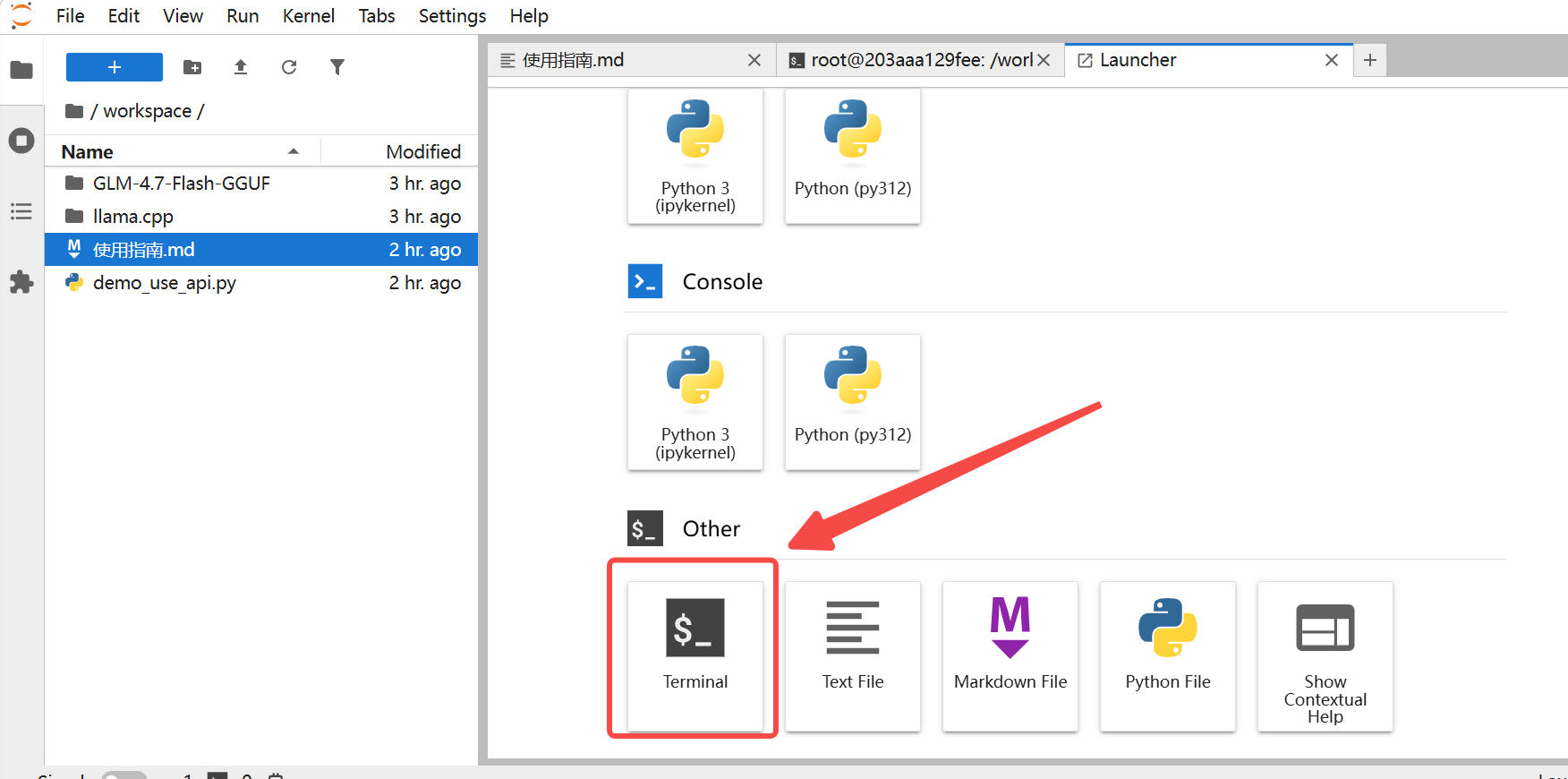
输入对话命令
通用对话命令
cd /workspace
./llama.cpp/llama-cli -m /workspace/GLM-4.7-Flash-GGUF/GLM-4.7-Flash-UD-Q4_K_XL.gguf \
--temp 1.0 \
--top-p 0.95 \
--min-p 0.01 \
--dry-multiplier 1.1 \
--ctx-size 32768 \
--cnv
网页对话命令
cd /workspace
./llama.cpp/llama-server -m /workspace/GLM-4.7-Flash-GGUF/GLM-4.7-Flash-UD-Q4_K_XL.gguf \
--port 8080 \
--host 0.0.0.0 \
--ctx-size 32768 \
--temp 1.0 \
--top-p 0.95 \
--min-p 0.01 \
--dry-multiplier 1.1 \
--n-gpu-layers 99
执行完成后,打开新的网页,如图:
http://您的实例IP:8080
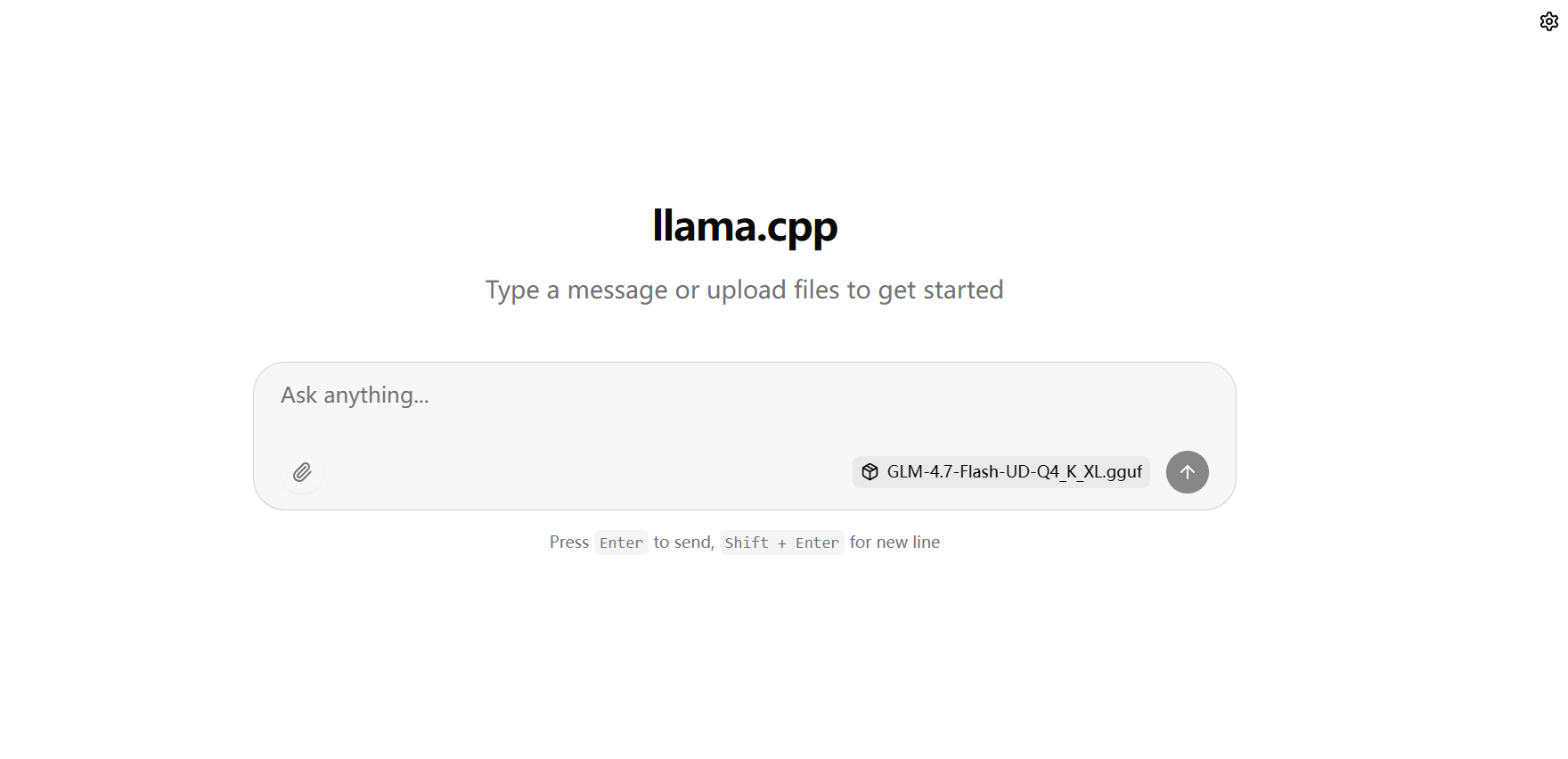 网页启动之后,也同时能 API 调用
网页启动之后,也同时能 API 调用
python demo_use_api.py
@苍耳阿猫 认证作者
认证作者
认证作者
镜像信息
已使用37 次
运行时长
180 H
镜像大小
50GB
最后更新时间
2026-01-22
支持卡型
RTX40系RTX50系48G RTX40系
+3
框架版本
CUDA版本
12.8
应用
JupyterLab: 8888
自定义开放端口
8080
+1
版本
v1.0
2026-01-22