 2
2基于SenseVoice多语言语音识别模型 WebUI 二次开发 构建by科哥
镜像简介
SenseVoice WebUI 是一个功能强大的多语言语音识别 Web 应用,支持语音识别(ASR)、情感识别(SER)和事件检测(AED)。本镜像基于 FunAudioLLM/SenseVoice 项目进行二次开发,提供现代化的用户界面和开箱即用的使用体验。
- 功能: 这个镜像主要用于多语言语音识别,支持中文、英文、粤语、日语、韩语等50+语言的自动识别,同时具备情感识别(6种情感)和事件检测(音乐、掌声、笑声等12种事件)功能。
- 特点: 预装了 PyTorch <=2.3、FunASR >=1.1.3、Gradio 6.2.0 环境,模型自动下载到本地,一键运行,紫蓝渐变现代简约UI设计。
镜像使用教程
开机自动启动webUI或者进入Jupyterlab后,终端输入下面指令重启应用:
/bin/bash /root/run.sh
访问地址
在浏览器中打开:
http://localhost:7860
界面说明
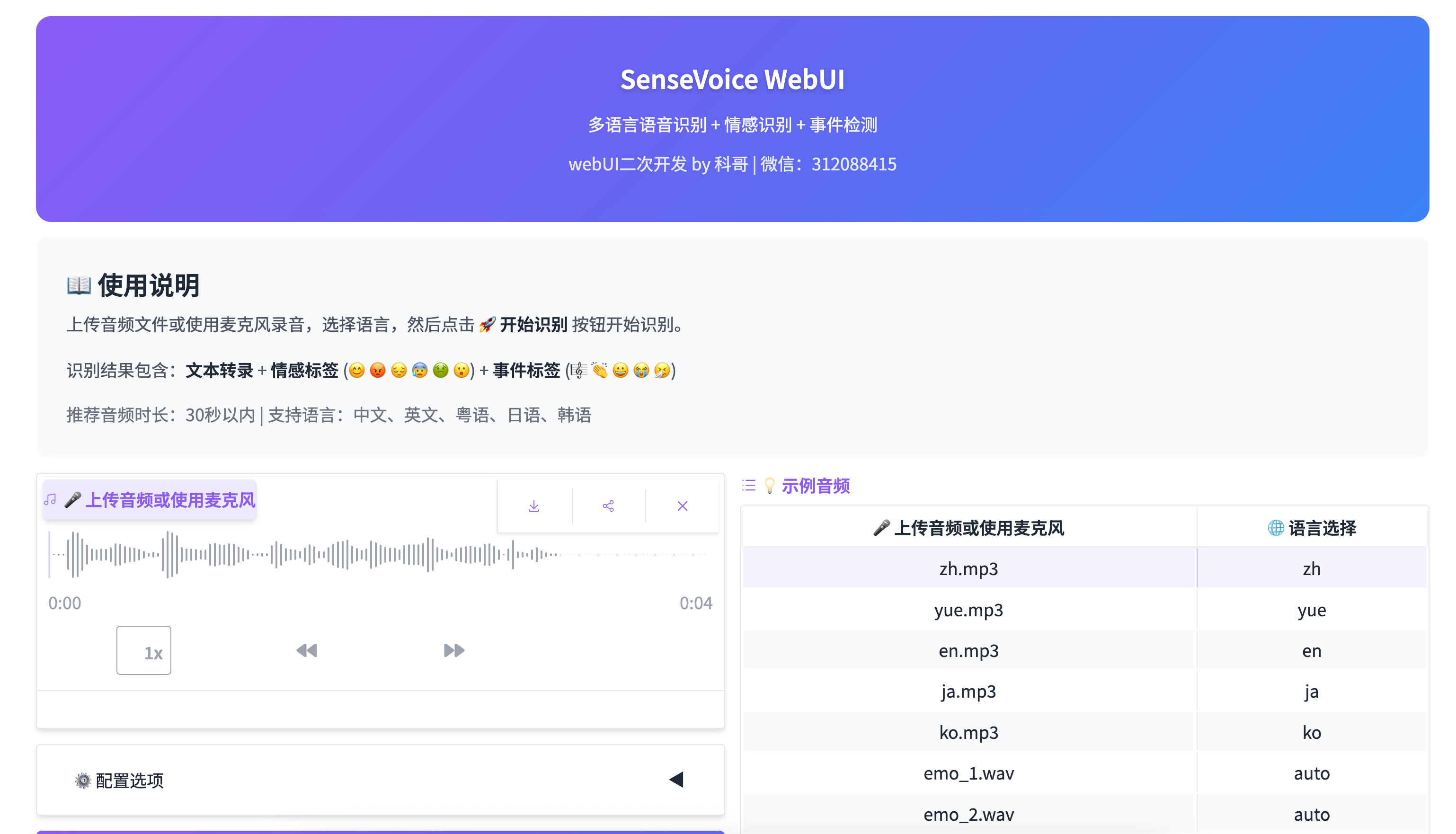
页面布局
┌─────────────────────────────────────────────────────────┐
│ [紫蓝渐变标题] SenseVoice WebUI │
│ webUI二次开发 by 科哥 | 微信:312088415 │
├─────────────────────────────────────────────────────────┤
│ 📖 使用说明 │
├──────────────────────┬──────────────────────────────────┤
│ 🎤 上传音频 │ 💡 示例音频 │
│ 🌐 语言选择 │ - zh.mp3 (中文) │
│ ⚙️ 配置选项 │ - en.mp3 (英文) │
│ 🚀 开始识别 │ - ja.mp3 (日语) │
│ 📝 识别结果 │ - ko.mp3 (韩语) │
└──────────────────────┴──────────────────────────────────┘
使用步骤
步骤 1: 上传音频
方式一:上传文件
- 点击 🎤 上传音频或使用麦克风 区域
- 选择音频文件(支持 MP3、WAV、M4A 等格式)
- 等待文件上传完成
方式二:麦克风录音
- 点击 🎤 上传音频或使用麦克风 右侧的麦克风图标
- 浏览器会请求麦克风权限,点击"允许"
- 点击红色录制按钮开始录音
- 再次点击停止录音
步骤 2: 选择语言
点击 🌐 语言选择 下拉菜单,选择识别语言:
| 语言 | 说明 |
|---|---|
| auto | 自动检测(推荐) |
| zh | 中文 |
| en | 英文 |
| yue | 粤语 |
| ja | 日语 |
| ko | 韩语 |
| nospeech | 无语音 |
步骤 3: 开始识别
点击 🚀 开始识别 按钮,等待识别完成。
识别时间:
- 10秒音频:约 0.5-1 秒
- 1分钟音频:约 3-5 秒
- 时长与 CPU/GPU 性能相关
步骤 4: 查看结果
识别结果会显示在 📝 识别结果 文本框中,包含:
-
文本内容:识别出的文字
-
情感标签(在文本末尾):
- 😊 开心 (HAPPY)
- 😡 生气/激动 (ANGRY)
- 😔 伤心 (SAD)
- 😰 恐惧 (FEARFUL)
- 🤢 厌恶 (DISGUSTED)
- 😮 惊讶 (SURPRISED)
- 无表情 = 中性 (NEUTRAL)
-
事件标签(在文本开头):
- 🎼 背景音乐 (BGM)
- 👏 掌声 (Applause)
- 😀 笑声 (Laughter)
- 😭 哭声 (Cry)
- 🤧 咳嗽/喷嚏 (Cough/Sneeze)
- 📞 电话铃声
- 🚗 引擎声
- 🚶 脚步声
- 🚪 开门声
- 🚨 警报声
- ⌨️ 键盘声
- 🖱️ 鼠标声
示例音频
点击右侧 💡 示例音频 列表中的任意音频,可以快速体验:
| 示例 | 语言 | 内容特点 |
|---|---|---|
| zh.mp3 | 中文 | 日常对话 |
| yue.mp3 | 粤语 | 粤语识别 |
| en.mp3 | 英文 | 英文朗读 |
| ja.mp3 | 日语 | 日文识别 |
| ko.mp3 | 韩语 | 韩文识别 |
| emo_1.wav | 自动 | 情感识别示例 |
| rich_1.wav | 自动 | 综合识别示例 |
配置选项
点击 ⚙️ 配置选项 展开高级设置(通常无需修改):
| 选项 | 说明 | 默认值 |
|---|---|---|
| 语言 | 识别语言 | auto |
| use_itn | 逆文本正则化 | True |
| merge_vad | 合并 VAD 分段 | True |
| batch_size_s | 动态批处理 | 60秒 |
识别结果示例
中文示例
开放时间早上9点至下午5点。😊
- 文本:开放时间早上9点至下午5点。
- 情感:😊 开心
英文示例
The tribal chieftain called for the boy and presented him with 50 pieces of gold.
- 文本:部落首领叫来了男孩,并给了他50块金币。
带事件标签示例
🎼😀欢迎收听本期节目,我是主持人小明。😊
- 事件:🎼 背景音乐 + 😀 笑声
- 文本:欢迎收听本期节目,我是主持人小明。
- 情感:😊 开心
使用技巧
1. 最佳音频质量
- 采样率:推荐 16kHz 或更高
- 格式:WAV(无损)> MP3 > M4A
- 时长:推荐 30 秒以内(最长无限制)
- 环境:安静环境,减少背景噪音
2. 语言选择建议
- 明确语言:如果确定是某种语言,直接选择对应语言,识别更准确
- 混合语言:选择 "auto" 自动检测
- 方言/口音:使用 "auto" 获得更好效果
3. 提高识别准确率
- 确保音频清晰,无回声
- 减少背景噪音
- 使用高质量麦克风
- 语速适中,不要过快
常见问题
Q: 上传音频后没有反应?
A: 检查音频文件是否损坏,尝试重新上传。
Q: 识别结果不准确?
A:
- 检查音频质量
- 确认语言选择是否正确
- 尝试使用 "auto" 自动检测
Q: 识别速度慢?
A:
- 音频时长过长会导致处理时间增加
- 检查服务器 CPU/GPU 占用情况
- 尝试使用更短的音频片段
Q: 如何复制识别结果?
A: 点击识别结果文本框右侧的复制按钮。
版权信息
开发: 科哥 联系方式: 微信 312088415 开源承诺: 承诺永远开源使用,保留本人版权信息
技术支持: FunAudioLLM/SenseVoice
最后更新: 2026-01-04
环境与依赖
本镜像构建和运行所需的基础环境。
-
框架及版本:
- PyTorch <= 2.3
- FunASR >= 1.1.3
- Gradio >= 6.2.0(实际安装6.2.0)
- ModelScope(模型下载)
- FastAPI >= 0.111.1
- Uvicorn
-
Python版本: Python 3.12 (conda py312 虚拟环境)
-
CUDA版本: CUDA 11.8 / cuDNN 8(支持GPU加速,自动检测)
-
其他依赖:
- librosa(音频处理)
- soundfile(音频读写)
- numpy <= 1.26.4(科学计算)
- pyyaml(配置管理)
配置方法
1. 启动 WebUI 服务
bash scripts/start_app.sh
启动脚本会自动:
- 检测并释放 7860 端口(如果有占用)
- 激活 py312 conda 环境
- 下载模型到
./models/目录(首次运行) - 启动 WebUI 服务
2. 访问 WebUI
浏览器访问:http://localhost:7860
3. 模型配置
模型配置文件位于 config/settings.yaml,可修改:
- 模型路径
- 推理参数
- UI 主题和颜色
- 输出路径
4. 端口配置
默认端口 7860,可通过环境变量修改:
export PORT=8080
bash scripts/start_app.sh
环境验证代码
Python 环境验证
from funasr import AutoModel
import torch
print("=== SenseVoice 环境验证 ===")
print(f"PyTorch 版本: {torch.__version__}")
print(f"CUDA 可用: {torch.cuda.is_available()}")
if torch.cuda.is_available():
print(f"CUDA 版本: {torch.version.cuda}")
print(f"GPU 设备: {torch.cuda.get_device_name(0)}")
# 测试模型加载
try:
model = AutoModel(
model="./models/SenseVoiceSmall",
vad_model="./models/vad_model",
trust_remote_code=True,
)
print("✅ 模型加载成功!")
except Exception as e:
print(f"❌ 模型加载失败: {e}")
快速验证命令
# 检查 conda 环境
conda activate py312 && python --version
# 检查依赖
pip list | grep -E "torch|funasr|gradio"
# 检查模型文件
ls -lh ./models/SenseVoiceSmall/model.pt
ls -lh ./models/vad_model/model.pt
# 检查端口
lsof -i:7860
相关链接
- 项目源码: FunAudioLLM/SenseVoice
- FunASR框架: modelscope/FunASR
- 模型卡片: SenseVoiceSmall - ModelScope
- Gradio文档: Gradio Official Docs
- 二次开发作者: 科哥 | 微信:312088415
常见问题
Q1:首次启动模型下载很慢怎么办?
A1: 模型约 900MB,下载时间取决于网络速度。如果下载中断,重新运行启动脚本会自动断点续传。也可以手动从 ModelScope 下载模型到 ./models/ 目录。
Q2:识别结果是乱码?
A2: 检查模型权重文件 model.pt 是否存在。确保符号链接指向正确的模型目录:
ls -la ./models/SenseVoiceSmall/model.pt # 应该显示约 893MB
Q3:GPU 内存不足怎么办?
A3: 在 config/settings.yaml 中设置 device: "cpu" 使用 CPU 推理,或者减小 batch_size_s 参数。
Q4:如何更改页面主题颜色?
A4: 编辑 webui.py 中的 custom_theme 部分,修改 primary_hue 和 secondary_hue 颜色值。
Q5:支持批量处理吗? A5: 当前版本支持单文件识别。批量处理功能可在 WebUI 上连续上传多个音频文件进行识别。
Q6:如何导出识别结果?
A6: 识别结果会显示在页面上,可以复制文本。结果也会保存到 ./outputs/outputs_YYYYMMDDHHMMSS/ 目录。
Q7:端口被占用无法启动? A7: 启动脚本会自动检测并终止占用 7860 端口的进程。如果仍然失败,手动检查:
lsof -ti:7860 | xargs kill -9
运行截图
bug反馈可以加入科哥专属群交流➕ 广告勿进!

科哥在UCloud镜像列表【不断更新中】:
本手册指导用户如何使用 SenseVoice WebUI 进行语音识别
 认证作者
认证作者
 支持自启动
支持自启动