 1
1X-Dub-WebUI
- 官方源码地址:
- https://github.com/KlingAIResearch/X-Dub
- X-Dub 是一款无掩码视觉口型同步项目,可实现音频驱动的视频唇形生成,支持任意尺寸单人物视频的在线自动裁剪与还原,对卡通、动物等非人类角色泛化性更佳;
- 支持调节外观保真与口型运动平衡,推理参数可灵活配置,为学术研究与技术演示的视觉配音工具。
bug反馈可以加入科哥专属群交流➕ 广告勿进!

科哥在UCloud镜像列表【不断更新中】:
项目运行截图:
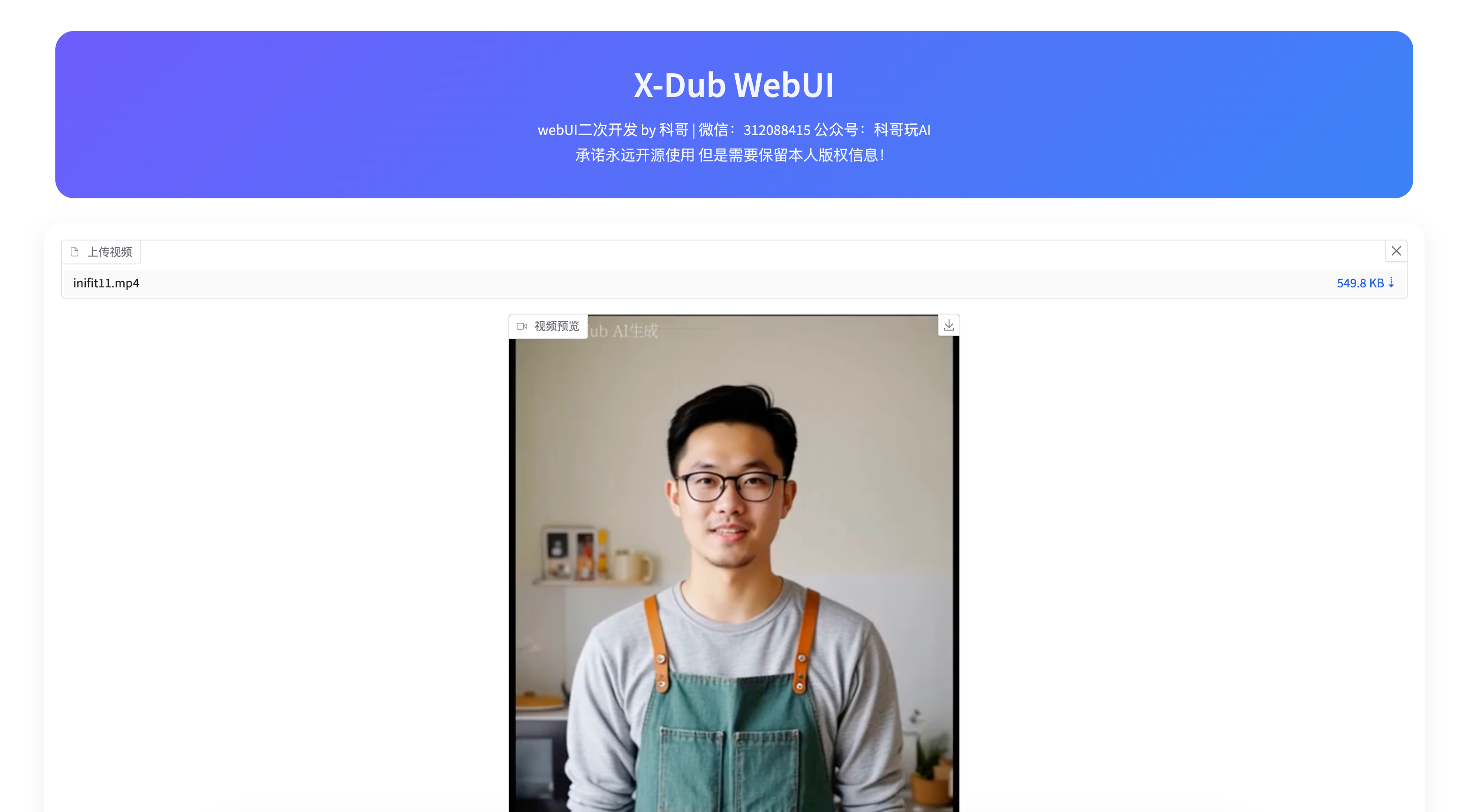
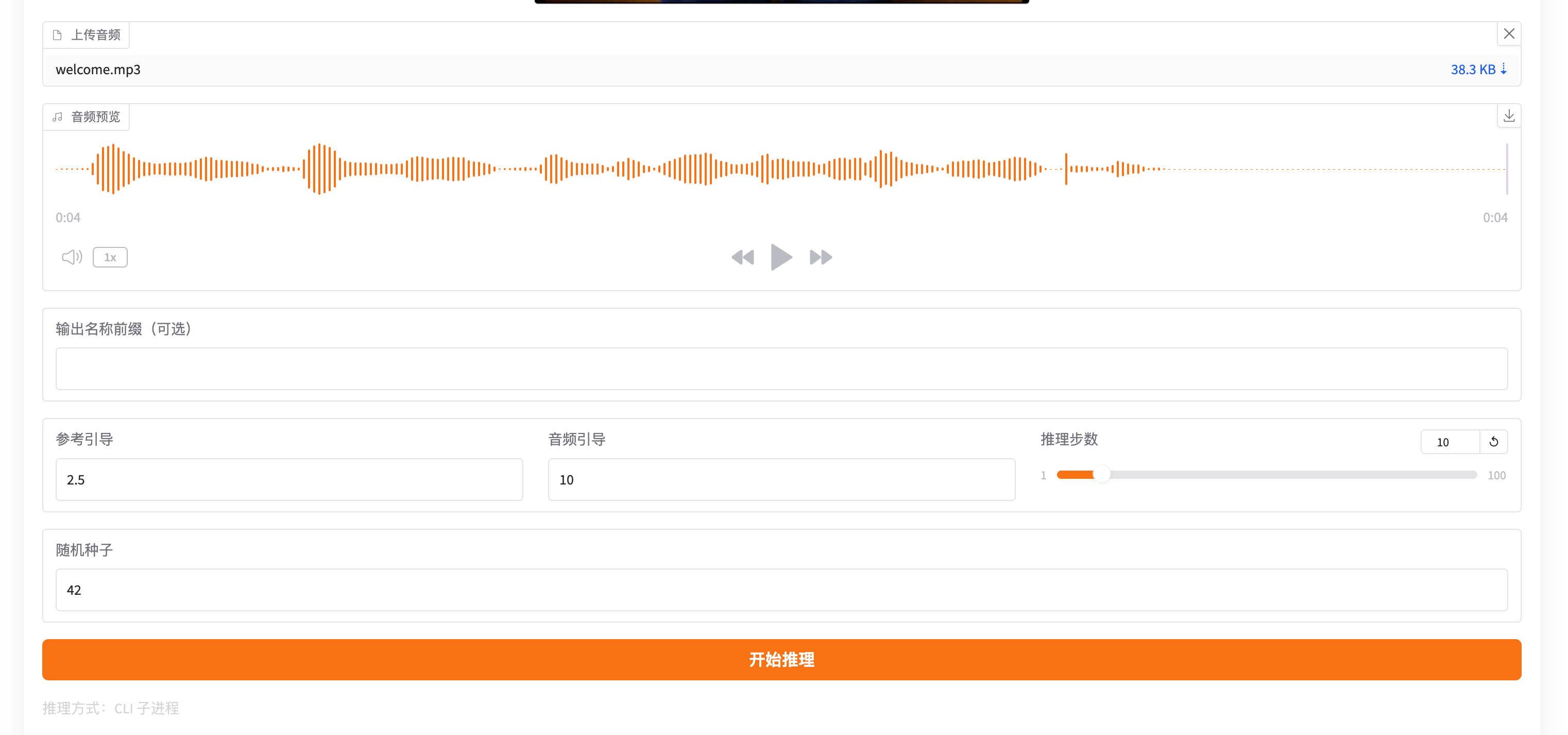
用户使用手册
1. 项目用途
X-Dub 用于根据一段输入视频和一段输入音频,生成口型同步结果。当前代码同时提供两种使用方式:
- WebUI:适合交互式上传素材、查看日志和直接预览结果。
- CLI:适合单次命令行推理或脚本化调用。
当前版本会先对输入视频做人脸区域自动裁剪,再进行 512×512 口型同步生成,最后再贴回原视频画面:README.md:180-186、infer_lip_sync_pipeline.py:59-175。
2. 启动方式
本手册不展开安装部署,只说明如何启动已有环境中的项目。
2.1 启动 WebUI
在项目根目录执行:
bash start_app.sh
当前脚本会做这几件事:
- 激活
py312环境:start_app.sh:14-15 - 释放 7860 端口已有进程:
start_app.sh:17-23 - 启动 WebUI:
start_app.sh:25-27
默认监听:
- 端口:
7860:start_app.sh:6、app.py:111 - 地址:
0.0.0.0:app.py:112,119
2.2 启动后状态说明
页面初始会显示:
模型状态:未加载(懒加载):app.py:78
这表示启动时不会预加载大模型,首次点击推理时才会真正加载;后续请求会复用已加载模型:webui_service.py:37-65。
3. WebUI 使用步骤
当前页面真实组件如下:app.py:68-81
- 上传视频
- 上传音频
- 输出名称前缀(可选)
- 参考引导
- 音频引导
- 推理步数
- 随机种子
- 开始推理
- 模型状态
- 输出目录
- 日志
- 生成结果
3.1 准备输入
- 在“上传视频”中选择一个视频文件。
- 支持:
.mp4、.mov、.mkv:app.py:69
- 支持:
- 在“上传音频”中选择一个音频文件。
- 支持:
.wav、.mp3、.m4a:app.py:70
- 支持:
3.2 填写可选参数
- 可在“输出名称前缀(可选)”中填写结果名前缀。
- 若不填,WebUI 最终展示的视频路径会按
sample_paste_compare.mp4兜底:app.py:96。
3.3 设置推理参数
可直接使用默认值,也可按需要微调:
- 参考引导:默认
2.5:app.py:73、webui_service.py:28 - 音频引导:默认
10.0:app.py:74、webui_service.py:29 - 推理步数:默认
50,范围1-100:app.py:75 - 随机种子:默认
42:app.py:76、webui_service.py:32
3.4 开始推理
点击“开始推理”。
当前实际流程为:app.py:83-104、webui_service.py:68-78
- 先检查是否已上传视频和音频。
- 为本次运行创建独立输出目录。
- 预处理视频并裁剪脸部区域。
- 若模型尚未加载,则首次加载模型。
- 执行推理。
- 回填输出目录、日志与生成结果视频。
3.5 查看结果
推理完成后,无需切换页面,当前页即可直接看到:
- 输出目录:本次运行结果所在目录
- 日志:预处理与推理打印信息
- 生成结果:最终合成视频
这三项都与“开始推理”同页展示:app.py:77-81,100-105。
4. 参数说明
4.1 输出名称前缀(可选)
用于控制输出文件前缀。
- WebUI 填写后,结果视频名会以该前缀命名。
- WebUI 不填时,页面返回的最终视频路径使用
sample_paste_compare.mp4:app.py:96。 - CLI 不填时,则默认取输入视频文件名作为
sample_name:infer_lip_sync_pipeline.py:60,197。
4.2 参考引导 ref_cfg_scale
控制对参考画面外观的保持程度。默认 2.5:infer_lip_sync_pipeline.py:131,183。
4.3 音频引导 audio_cfg_scale
控制口型受输入音频驱动的强度。默认 10.0:infer_lip_sync_pipeline.py:132,184。
4.4 推理步数 num_inference_steps
控制采样步数。默认 50:infer_lip_sync_pipeline.py:133,186。
README 给出的实践建议是 25-50 区间:README.md:199-201。
4.5 随机种子 seed
控制本次推理随机性。默认 42:infer_lip_sync_pipeline.py:134,187。
5. 输出结果怎么看
5.1 输出目录规则
若未手动指定输出目录,每次运行都会在项目根目录下自动创建:
outputs/outputs_YYYYmmddHHMMSS
若同一秒已存在同名目录,会自动追加 _1、_2 等后缀:project_paths.py:24-33。
5.2 结果文件
当前推理链路会至少输出两类对比视频:infer_lip_sync_pipeline.py:171-175
*_crop_compare.mp4:裁剪区域对比视频*_paste_compare.mp4:贴回原视频后的对比视频
WebUI 页面中的“生成结果”显示的是:
*_paste_compare.mp4:app.py:95-98
5.3 日志信息
“日志”文本框展示的是本次运行的标准输出与错误输出汇总,包括但不限于:
- 预处理帧数
- 首个 bbox
- 音频对应总长度
- clip 分段进度
这些日志由服务层重定向后回填:webui_service.py:73-78。
6. CLI 用法
如果你不想使用 WebUI,也可以直接命令行推理。
6.1 最小示例
python infer_lip_sync_pipeline.py \
--video_path <输入视频> \
--audio_path <输入音频>
6.2 常用示例
python infer_lip_sync_pipeline.py \
--video_path assets/examples/video.mp4 \
--audio_path assets/examples/audio.wav \
--sample_name demo \
--ref_cfg_scale 2.5 \
--audio_cfg_scale 10.0 \
--num_inference_steps 50 \
--seed 42 \
--output_dir ./outputs/manual_run
6.3 CLI 核心参数
当前脚本支持的主要参数如下:infer_lip_sync_pipeline.py:178-190
--video_path:输入视频,必填--audio_path:输入音频,必填--sample_name:输出文件名前缀,可选--ref_cfg_scale:参考引导,默认2.5--audio_cfg_scale:音频引导,默认10.0--audio_feat_window_size:默认0--num_inference_steps:推理步数,默认50--seed:随机种子,默认42--ckpt_path:主模型权重路径--output_dir:输出目录;不填时自动创建运行目录:infer_lip_sync_pipeline.py:195-196
7. 常见 FAQ
Q1:为什么刚打开 WebUI 很快,但第一次推理比较慢?
因为当前实现是懒加载。启动时不加载模型,首次推理才会真正构建 LipSyncPipeline,后续请求复用同一实例:app.py:78、webui_service.py:44-62。
Q2:没上传文件就点开始推理会怎样?
会直接报错:请先上传视频和音频文件:app.py:84-85。
Q3:结果文件保存到哪里?
默认保存在项目根目录 outputs/ 下的新建运行目录中,例如:
outputs/outputs_20260329153000
规则见:project_paths.py:24-33。
Q4:WebUI 里看到的是哪个结果视频?
是本次输出目录中的 *_paste_compare.mp4,也就是贴回原始视频后的对比结果:app.py:95-98。
Q5:支持多人视频吗?
当前版本仅支持单人视频。README 已明确当前版本不支持多人场景下的目标跟踪:README.md:180-196。
Q6:需要多少显存?
README 中说明推理通常需要约 21 GB VRAM:README.md:94。
Q7:为什么结果有时会抖动、漂移,或者偶尔出现噪声帧?
这是公开版当前已知现象。README 已说明:
- 可能有时序抖动
- 可能有身份漂移或颜色漂移
- 小部分案例会出现严重噪声帧
对应说明见:README.md:71-79,190-193。
Q8:推理步数设多少比较合适?
README 当前给出的实践建议是 25-50:README.md:199-201。默认值是 50:app.py:75、infer_lip_sync_pipeline.py:186。
8. 注意事项
- 当前流程依赖自动裁剪,核心生成分辨率为
512×512:README.md:184-185、infer_lip_sync_pipeline.py:127-128。 - WebUI 当前并发限制为
1,更适合单任务顺序执行:app.py:105。 - 如果你希望保留原始画面上下文进行查看,应重点查看
*_paste_compare.mp4;若想看裁剪区域生成效果,可查看*_crop_compare.mp4:infer_lip_sync_pipeline.py:171-175。 - 当前项目根目录中的模型约定位置是
models/,输出约定位置是outputs/:project_paths.py:5-8。
 认证作者
认证作者
 支持自启动
支持自启动