 187
187IndexTTS2.0版本VLLM加速版雨落版整合包V3版本使用说明
B站开源的IndexTTS2.0整合包说明,把开源模型转换为生产力工具的强力整合包,功能支持非常丰富。
支持创作类型
支持创作类型有:
1.单个语音条创作,对应到UI的"单条数据模式"。
2.有声书、读小说等创作,对应到"单角色批量文本模式“。
3.AI短剧、创意视频,对应到"多角色剧本模式"。
4.如果想更加复杂的定制,也可以使用"批量Excel模式"。
另外还支持了两个常见的创作诉求:
1.从视频中提取音频。
2.转换音频格式。
由于页面和功能较多,如果对部分使用细节不清楚的,到微信群内咨询:

下面会对主要环节进行说明,如果有不清楚的地方可以去群内追问,我会定期完善这个帮助文档~
使用教程
如何选择机器型号
这里仅对三款旗舰级显卡做了性能测试,具体请大家根据效果和费用自行选择。
这里仅以500字的小说作为测试用例,测试的性能数据如下:
RTX5090的RTF约为: 0.2534
RTX4090的RTF约为: 0.3531
RTX3090的RTF约为: 0.4098
更具体的数据评测参考(包含测试数据和详情内容):
https://wcnn68ei31q6.feishu.cn/wiki/MXBow7PGuiKaGykfgJWcFC2Ln8g
使用一: 如何启动
首先在镜像社区找到对应的镜像,并且选择合适的显卡,如下:
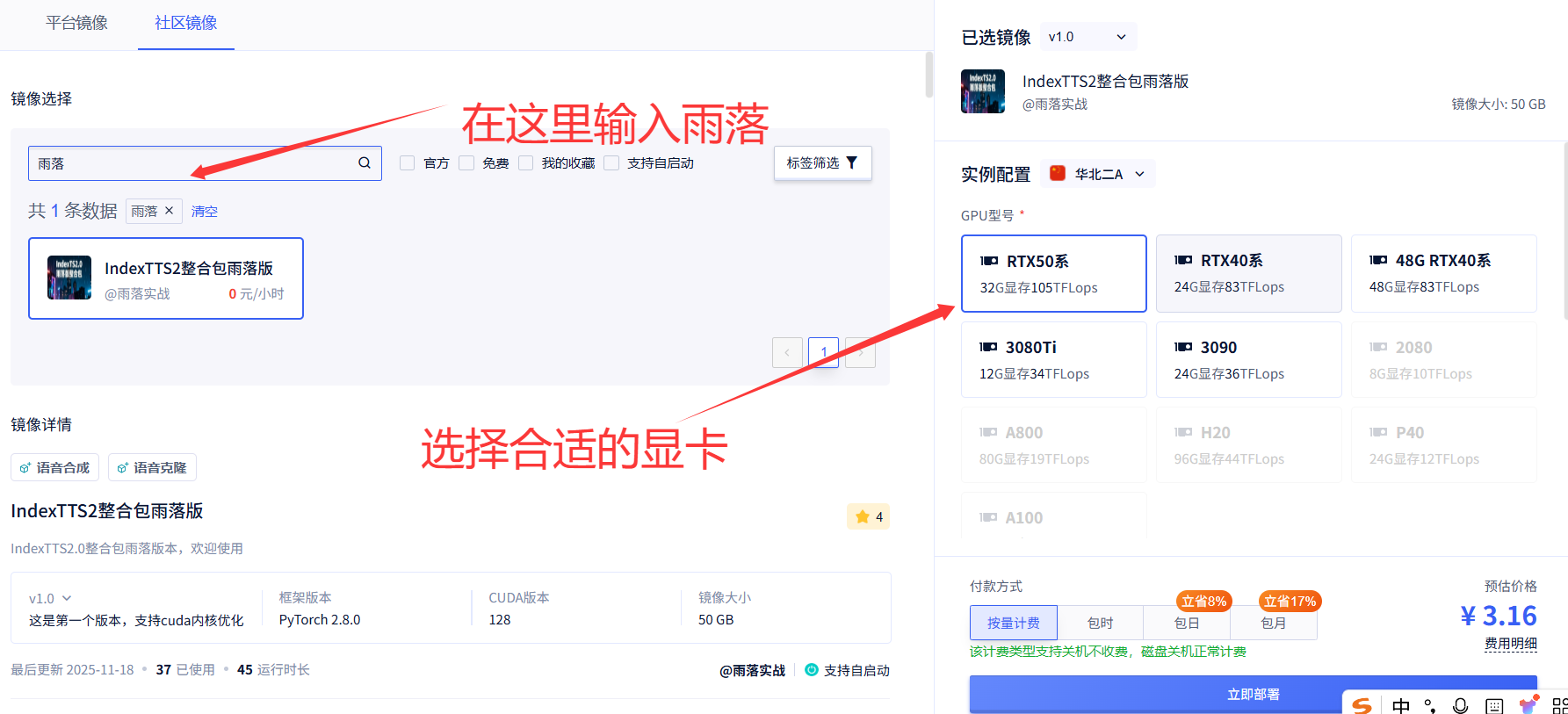
在配置好镜像之后,点击这里的"启动"就可以了。
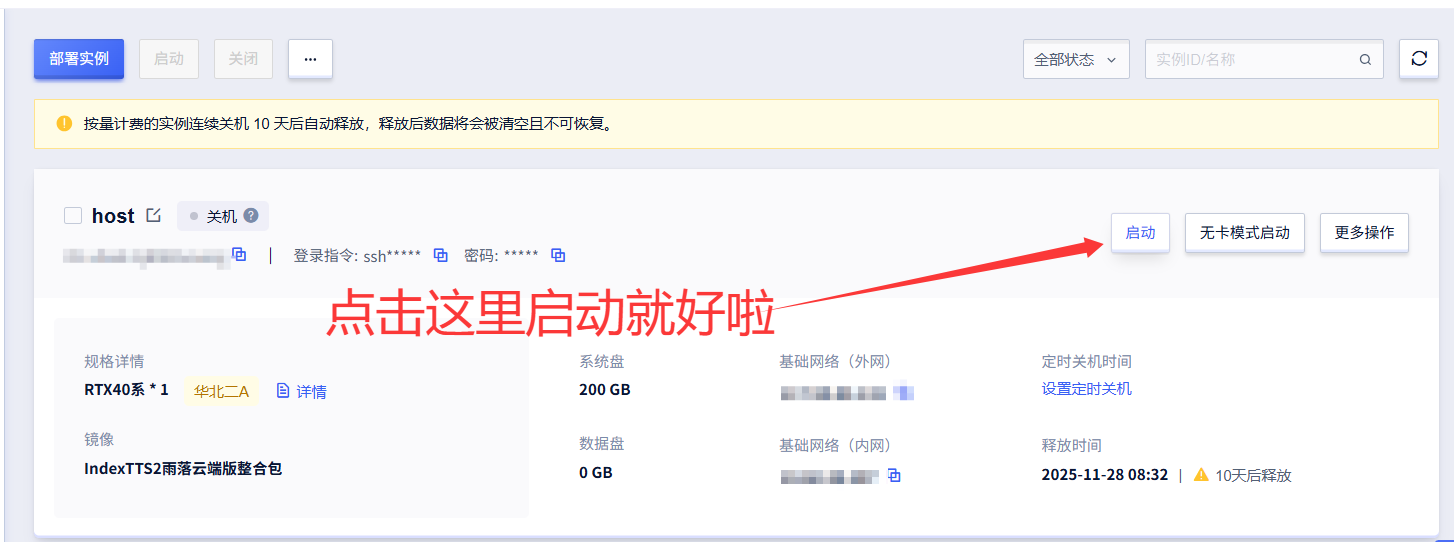
然后会进入到初始化的模式
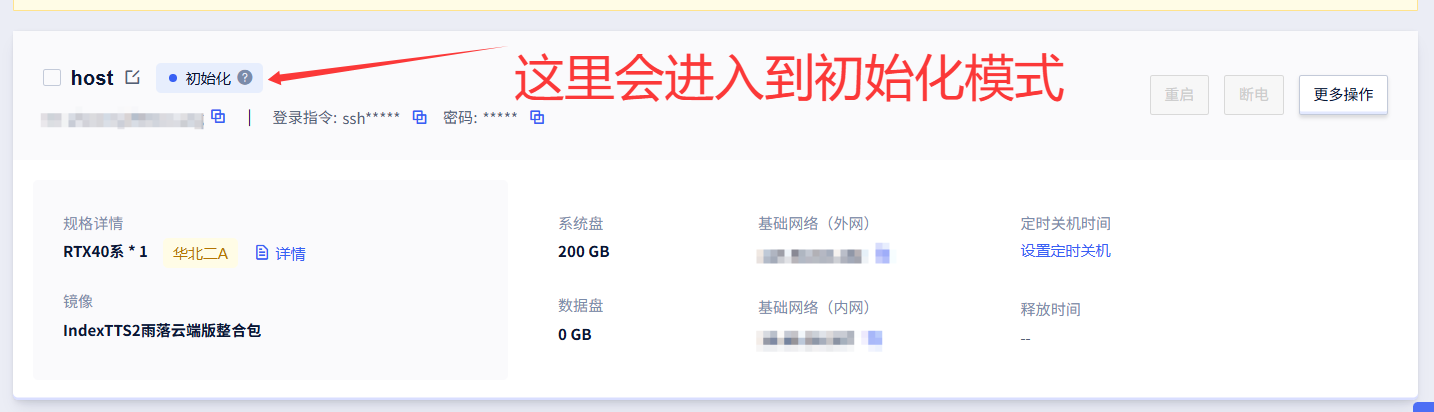
然后就可以点击下面的"IndexTTS2 WebUI"来进入对应界面了
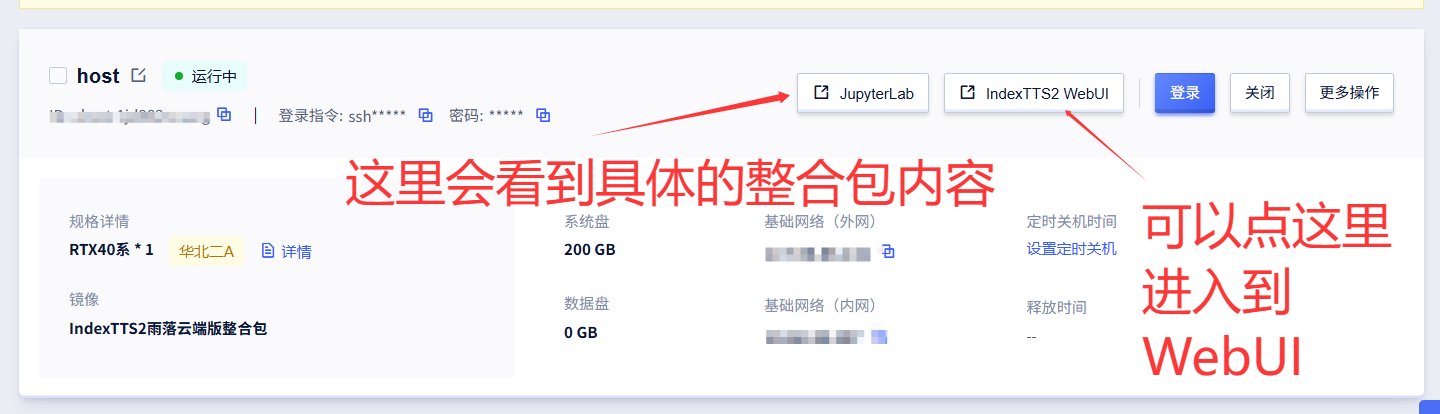
初始化过程会有一丢丢慢,但是最多五分钟肯定也够用了,如果还无法进入,请去最后一项问题排查页面。正常进入页面后会有如下效果:
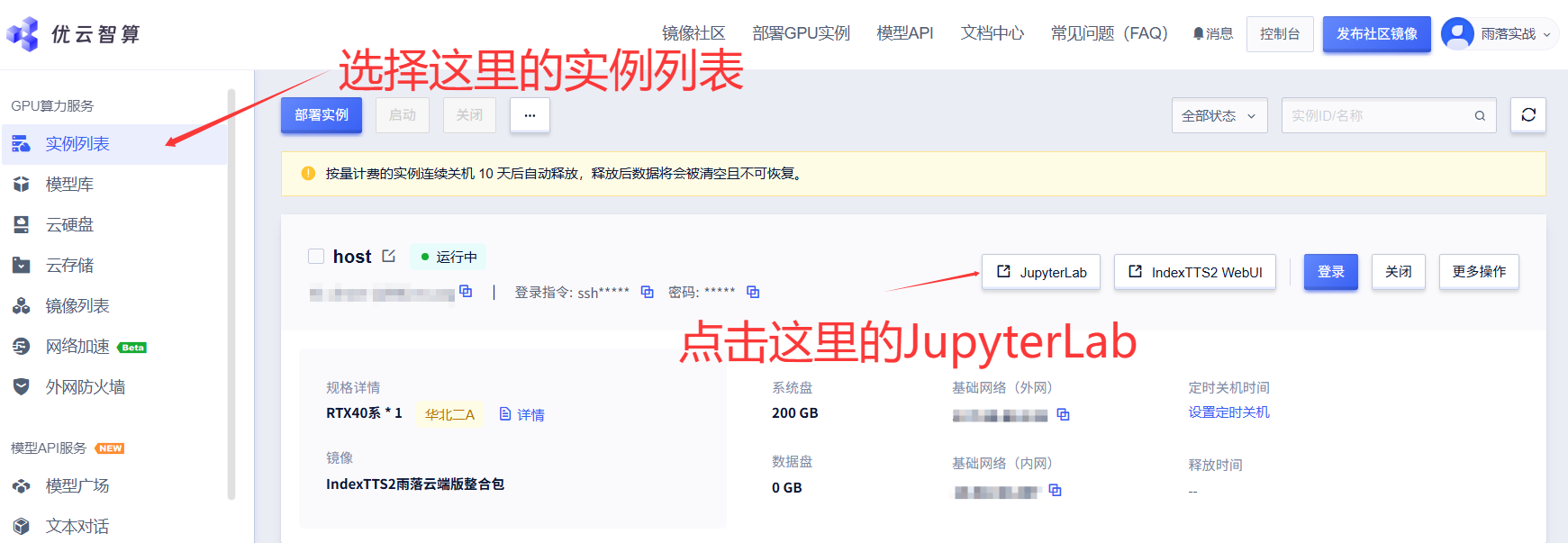
问题排查(一般用不到):
初次使用可能会遇到一些问题,所以这里把问题排查方式写出来,首先在实例列表页面选择对应的实例,然后点击"JupyterLab"进入,如下操作:
 进入之后可以双击log.txt查看运行日志,如下:
进入之后可以双击log.txt查看运行日志,如下:
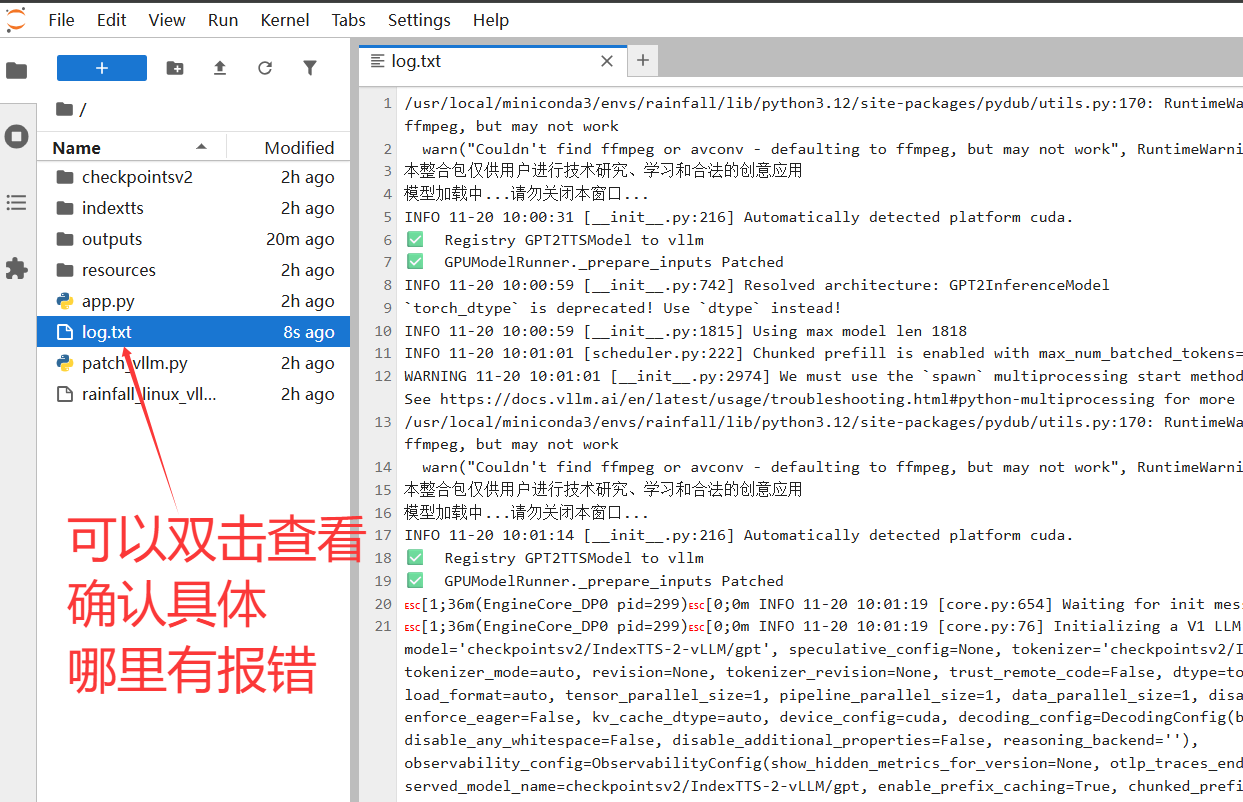
英文看不懂也没关系,可以去客服群里问下。
虽然这个页面是很简单易用的,但是为了避免使用上的问题,我还是要做一个具体的说明。
单条数据使用: 最佳实践
对于生成的语音文件的下载,这里为了保证万无一失,提供了两种方案,如下:
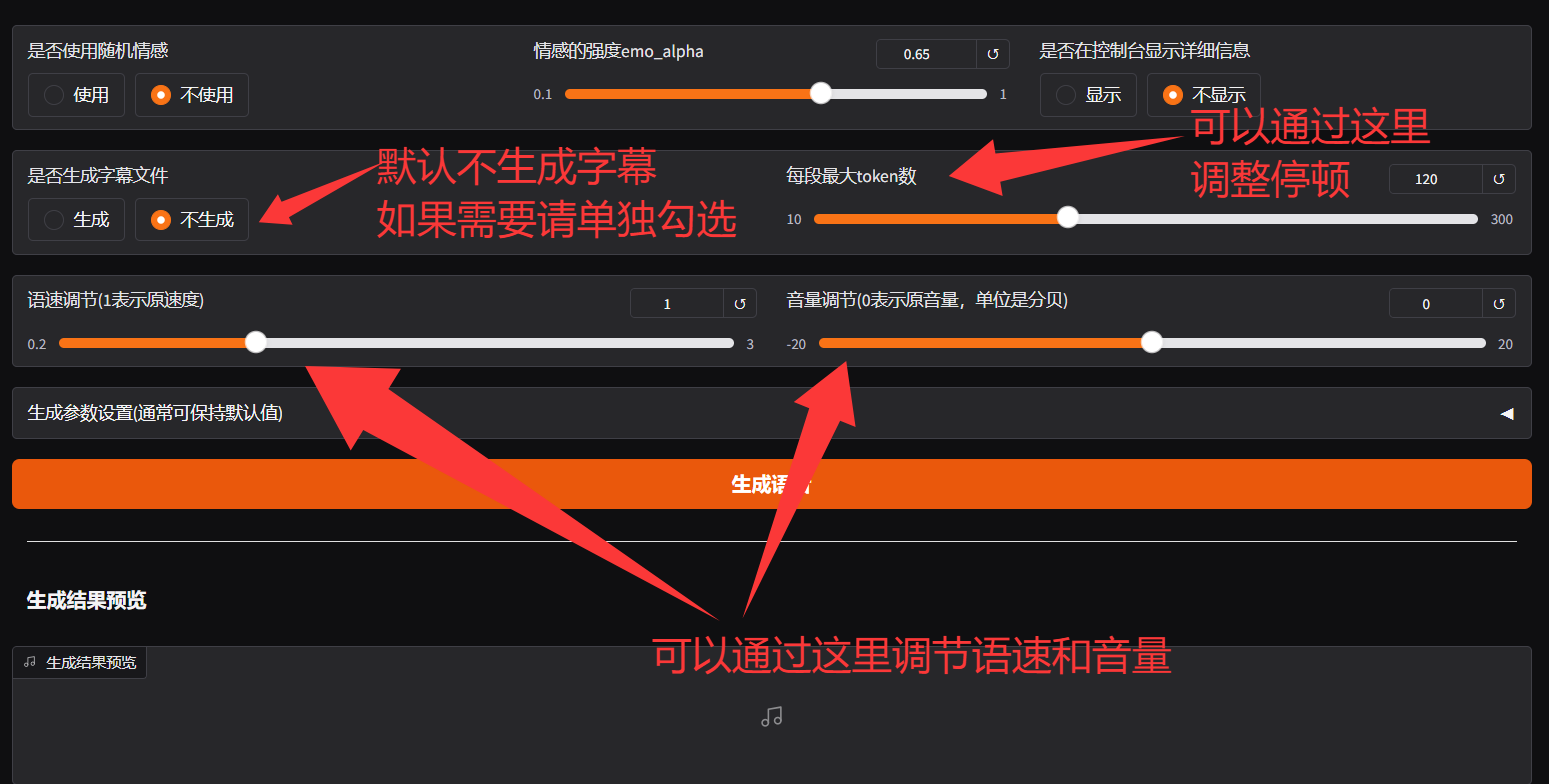
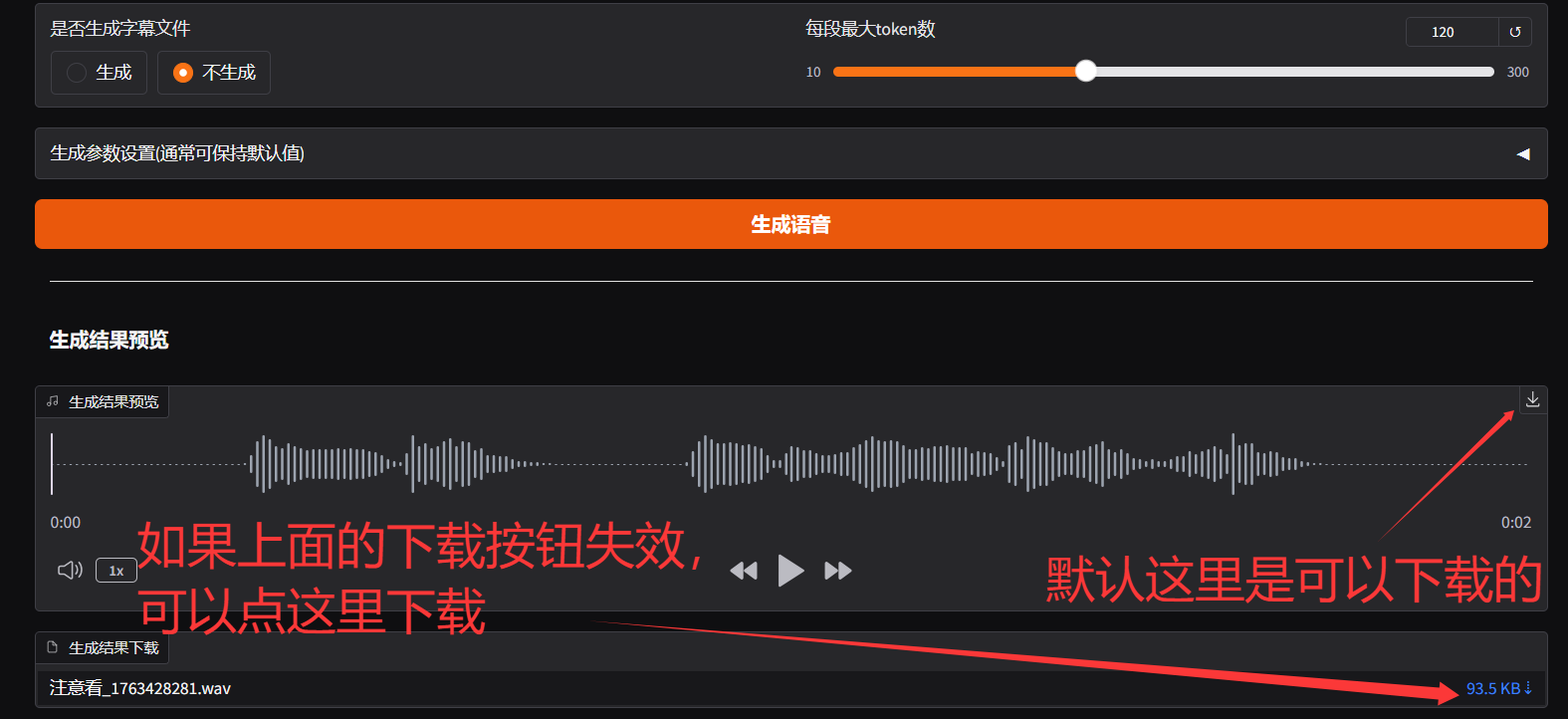 对于字幕、停顿、语速和音量,说明如下:
对于字幕、停顿、语速和音量,说明如下:
单音色克隆模式: 最佳实践
这里是支持多文件上传的,默认的生成结果里面每个txt文件对应到一个wav文件 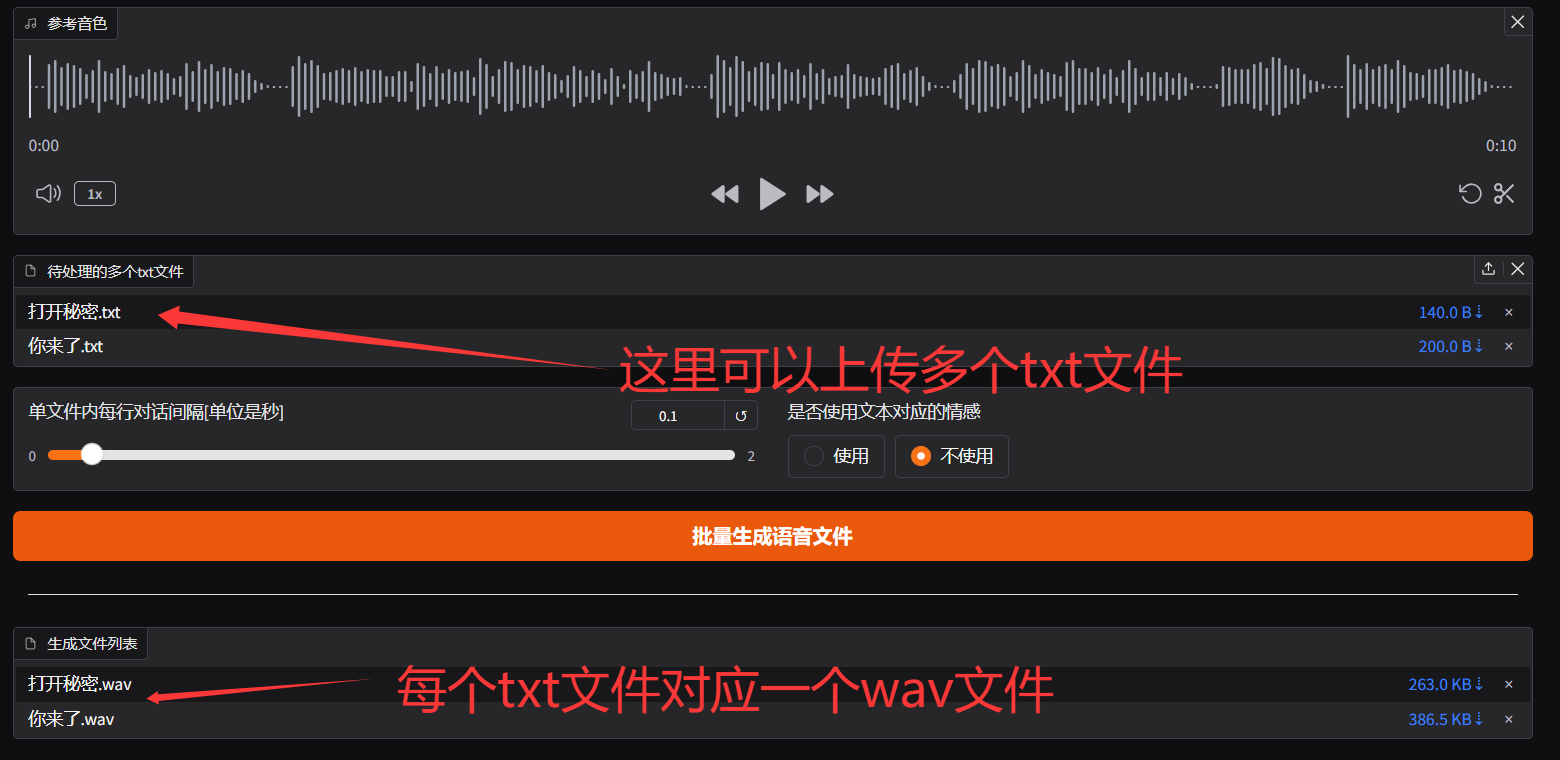
注意: 为了防止意外情况,txt文件默认应该使用utf-8编码。
如果出现了乱码识别不了的情况,可以使用像Notepad++、UltraEditor、Sublime Text等文本编辑器,可以调整字符集格式。
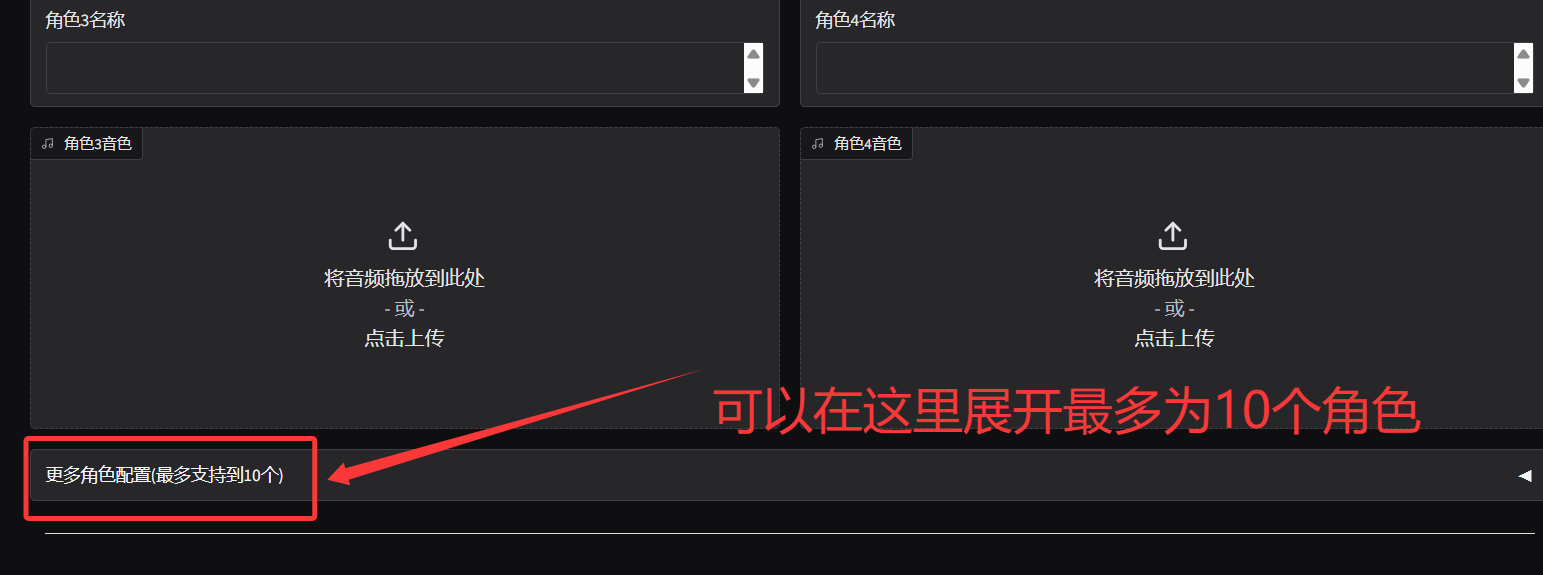
多音色剧本模式: 最佳实践
一般来说一个场景里面,设置4个角色是够用的,毕竟角色太多了观众也会乱。 但是为了兼容复杂场景,这里设置到最多支持10个角色。
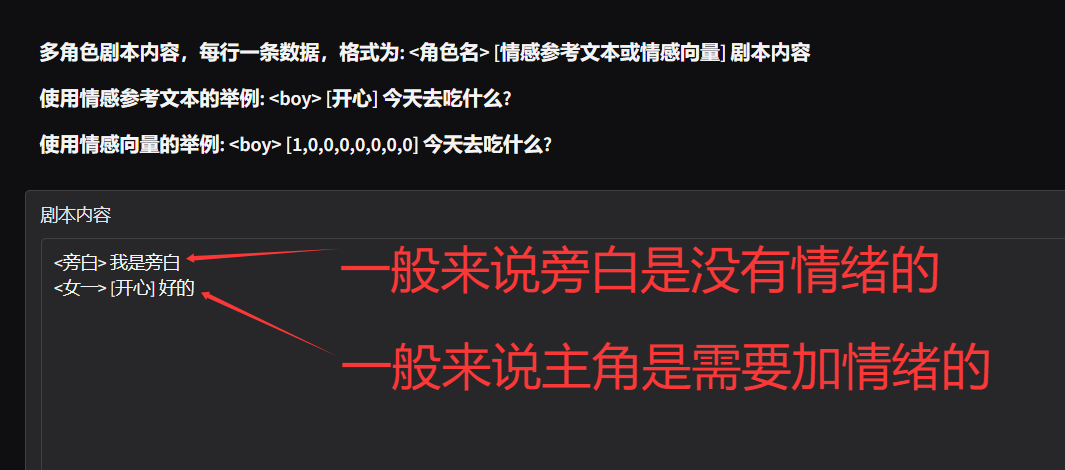
在文本内容里,情感(或者叫情绪)是可选的,如下:
Excel上传模式: 最佳实践
Excel的模板地址: https://pan.quark.cn/s/6584cfacc341 (注意跟之前版本有区别)
特别注意的是,Excel中需要指定音色文件默认是没有存储的,这个时候就需要在实例列表页面中通过JupyterLab进行音色文件的上传了。
第一步,在容器列表页面,点击JupyterLab然后进入,操作范例:
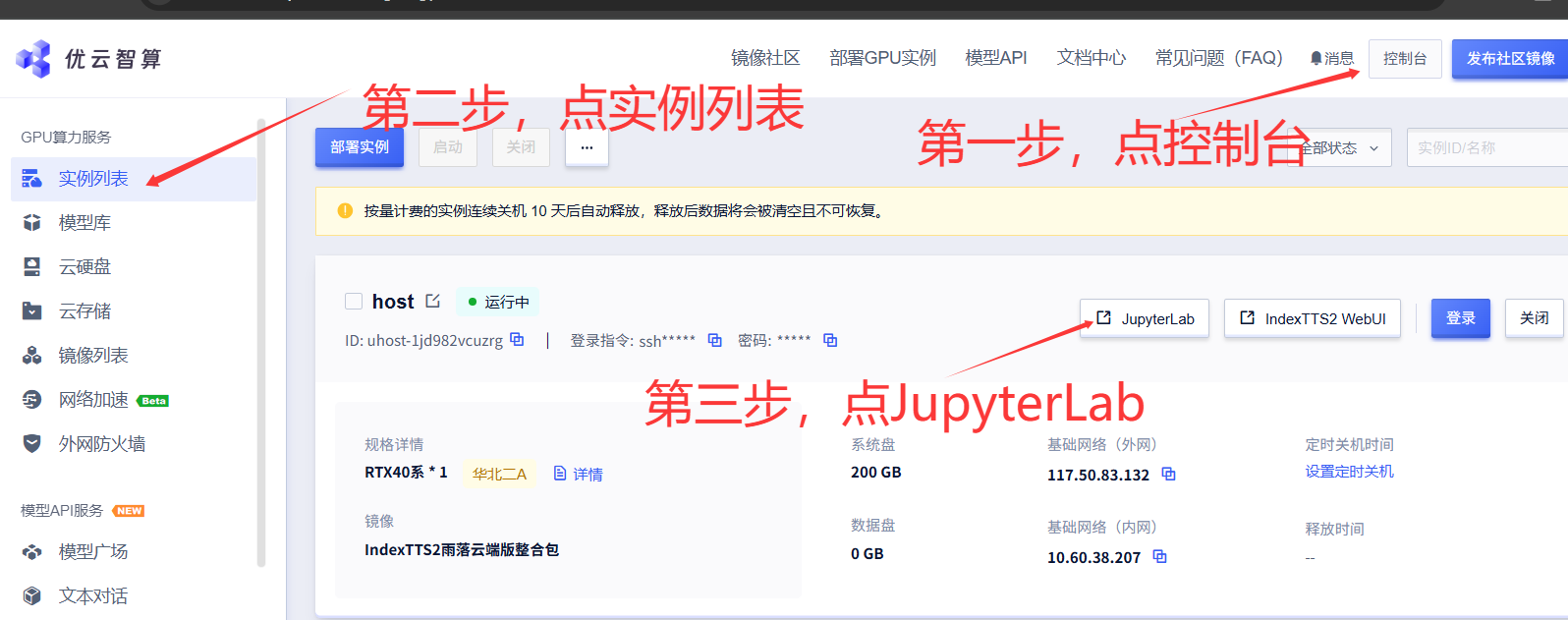
第二步,在JupyterLab中,进入到resources下面的prompt_audio中,操作范例:
首先点击进入到resources,如下:
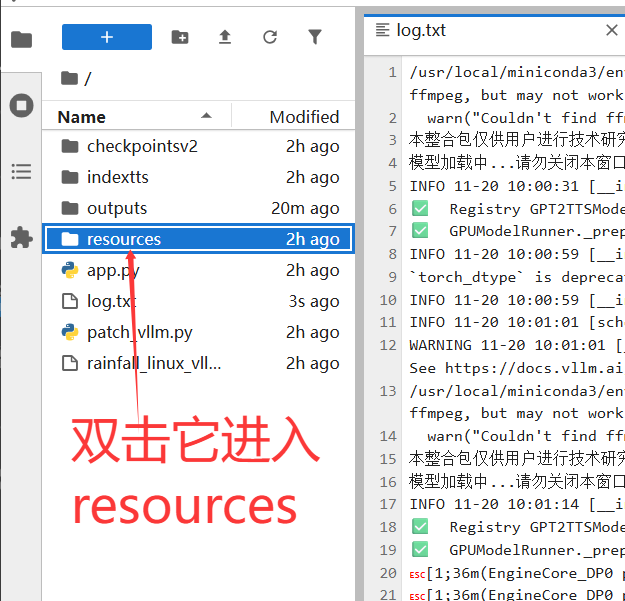
然后再点击进入到prompt_audio,如下:
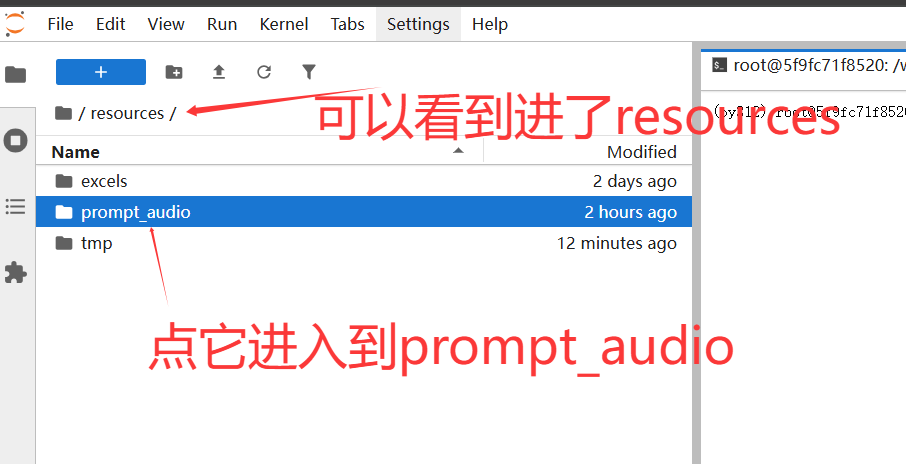
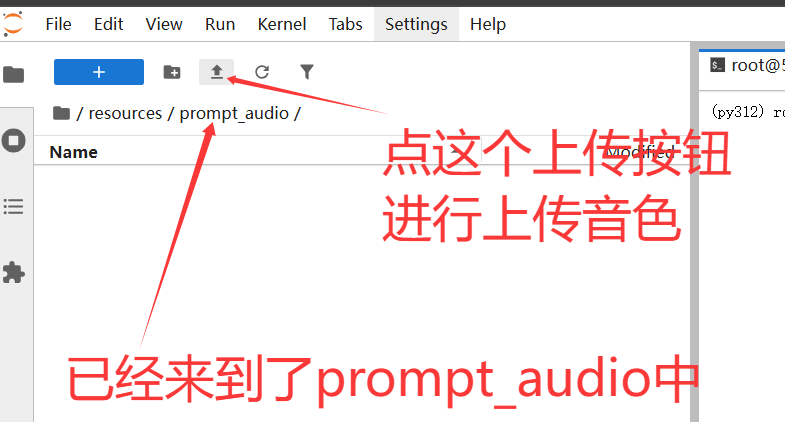
最后点击这个按钮开始上传wav文件,如下:
其他问题?
问题1: 如果当时没有来得及下载,就刷新页面了,内容还在吗?
答案: 是还在的,在JupyterLab里面的outputs里面。(前面已经讲过两次如何进入JupyterLab了,这里不再讲了)。
可以点击这里进入到outputs里面,如下:
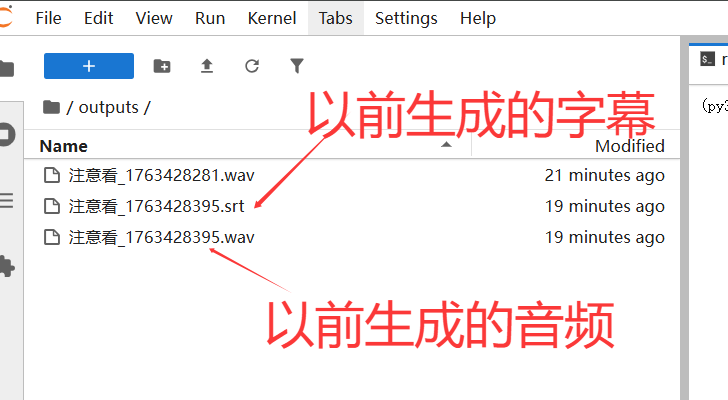
 然后就可以看到我们以前生成的文件了:
然后就可以看到我们以前生成的文件了:
问题2: 使用完怎么退出呢?
注意: 首先对于一般使用者来说,推荐按量计费。 使用完后一定要关机(不然可能会持续扣费),而且实例默认保持十天。
如果在使用的过程中遇到了其他问题,可以去UP的主页里面反馈,后续可能会继续优化。
 认证作者
认证作者

 支持自启动
支持自启动