 4
4Qwen-Image-Edit
Qwen-Image-Edit是什么
- Qwen-Image-Edit 是基于 200 亿参数的 Qwen-Image 架构构建的全能图像编辑模型。
- 模型兼具语义与外观的双重编辑能力,能进行低层次的视觉外观编辑(如添加、删除、修改元素)
- 高层次的视觉语义编辑(如 IP 创作、物体旋转、风格迁移等)
- 模型支持中英文双语文字的精准编辑,支持在保留原有字体、字号和风格的前提下修改图片中的文字
- Qwen-Image-Edit 在多个公开基准测试中表现出色,具备 SOTA 性能
镜像简介
- 图片编辑 支持中文和图片一致性更加好
- 特点: 预装了环境,模型全部离线了 开机自动运行
- 需要80gb显存的显卡运行 A800测试通过
镜像使用指南
1、在社区镜像区域,选择镜像:
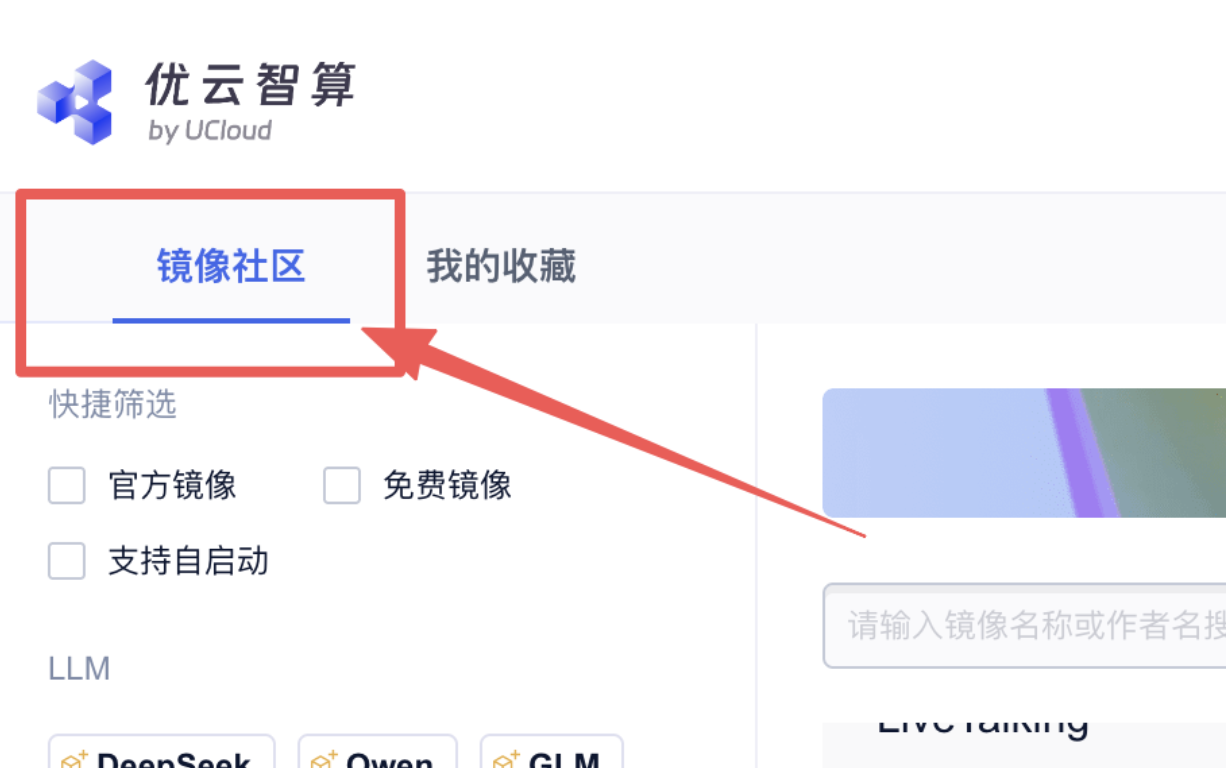
2、在打开的新页面 点击“使用该镜像创建实例”:
2、在打开的新页面 点击“使用该镜像创建实例”:
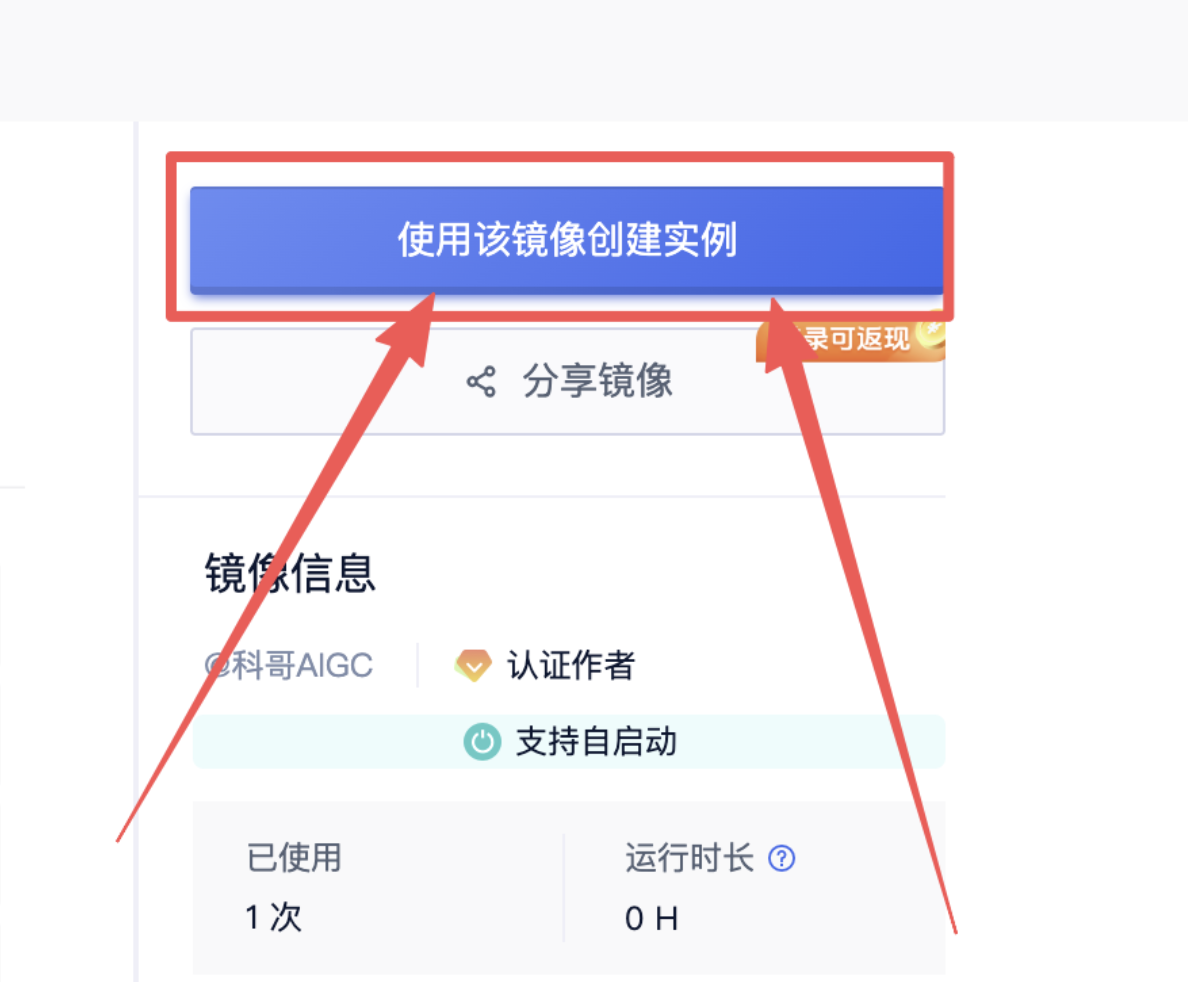
3、选择一个合适的显卡【GPU】根据情况选择,点击“开始部署”,然后等待部署完成:
3、选择一个合适的显卡【GPU】根据情况选择,点击“开始部署”,然后等待部署完成:
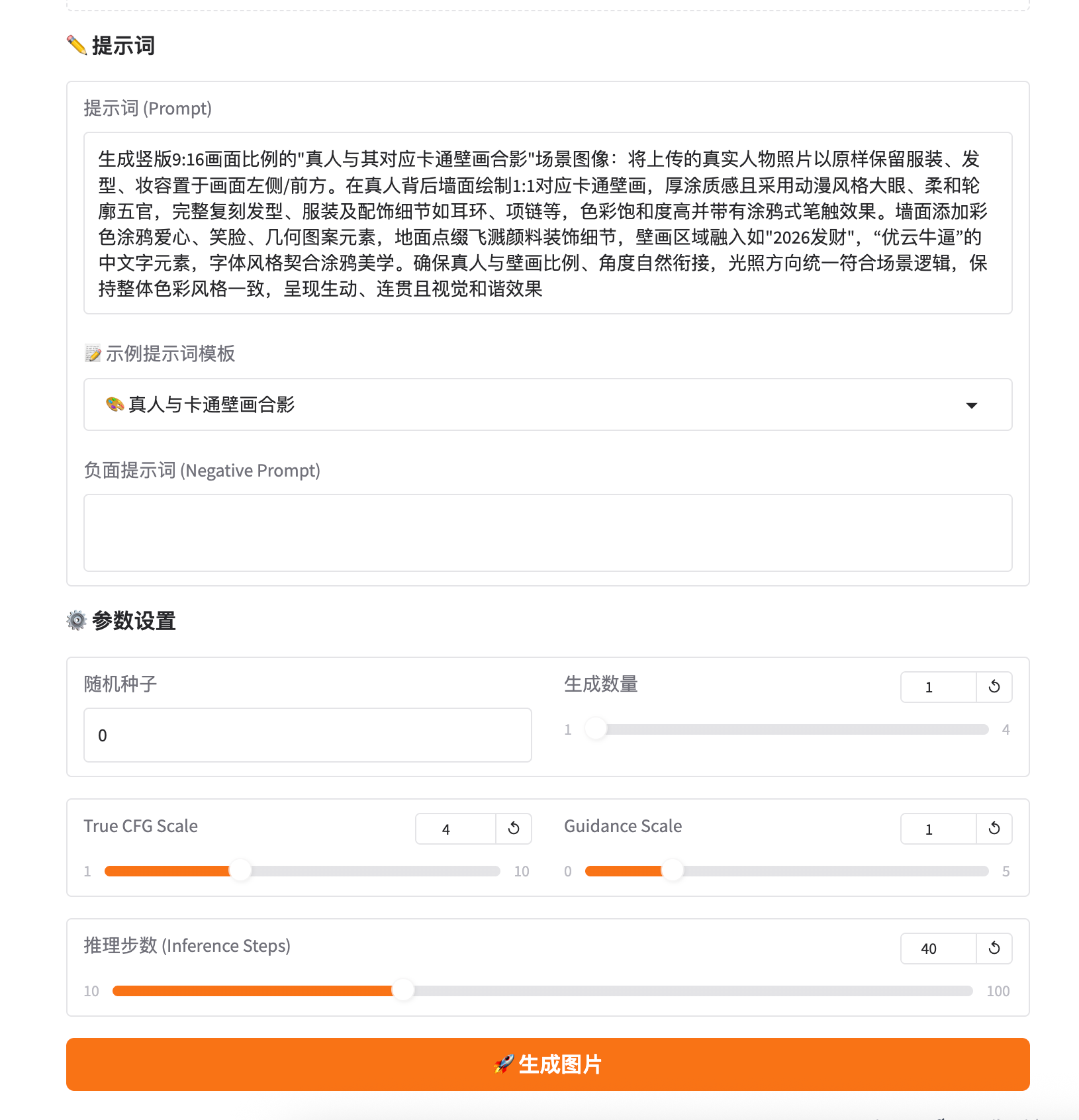
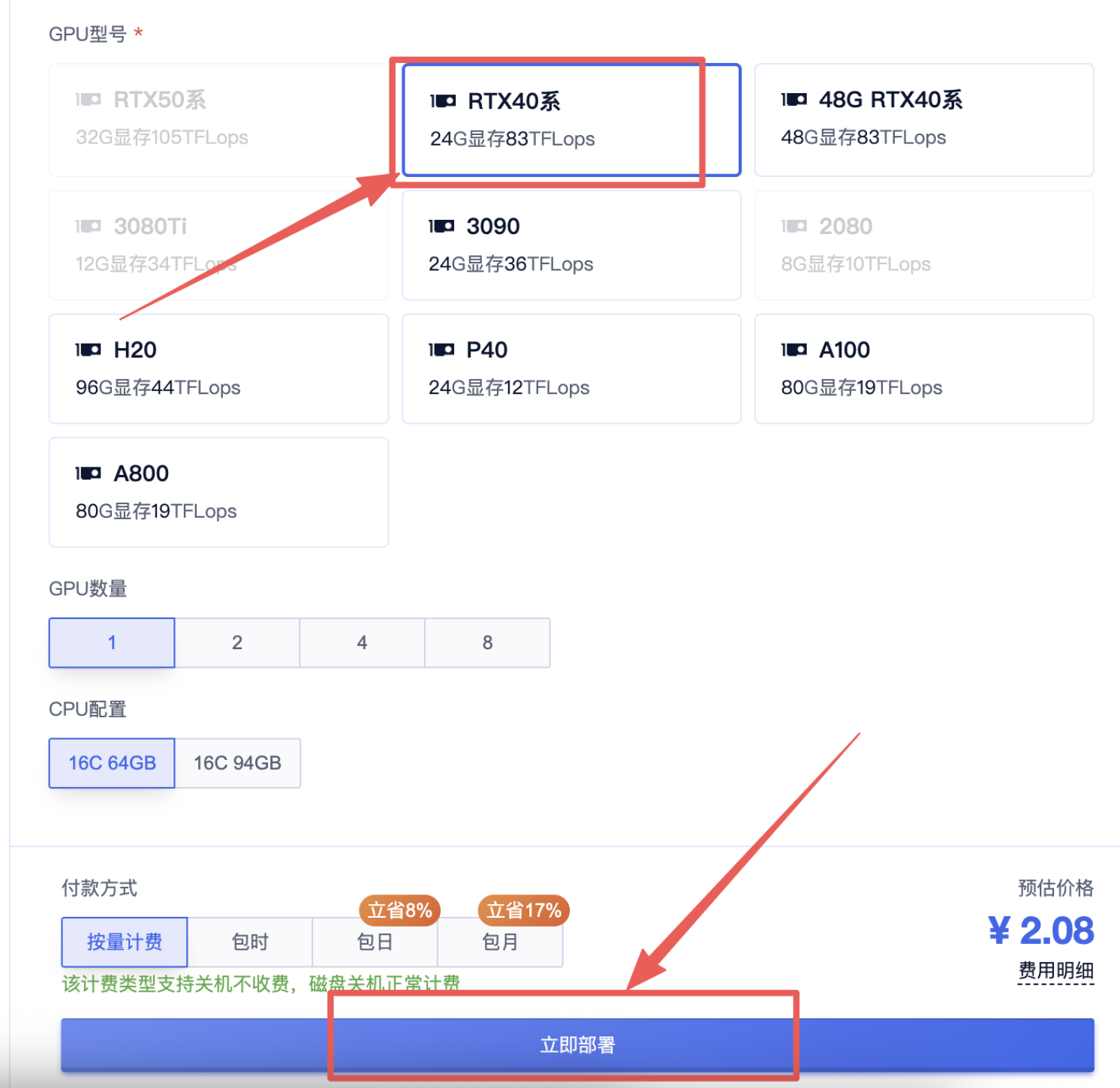 4、实例运行后打开SD-WebUI即可
4、实例运行后打开SD-WebUI即可
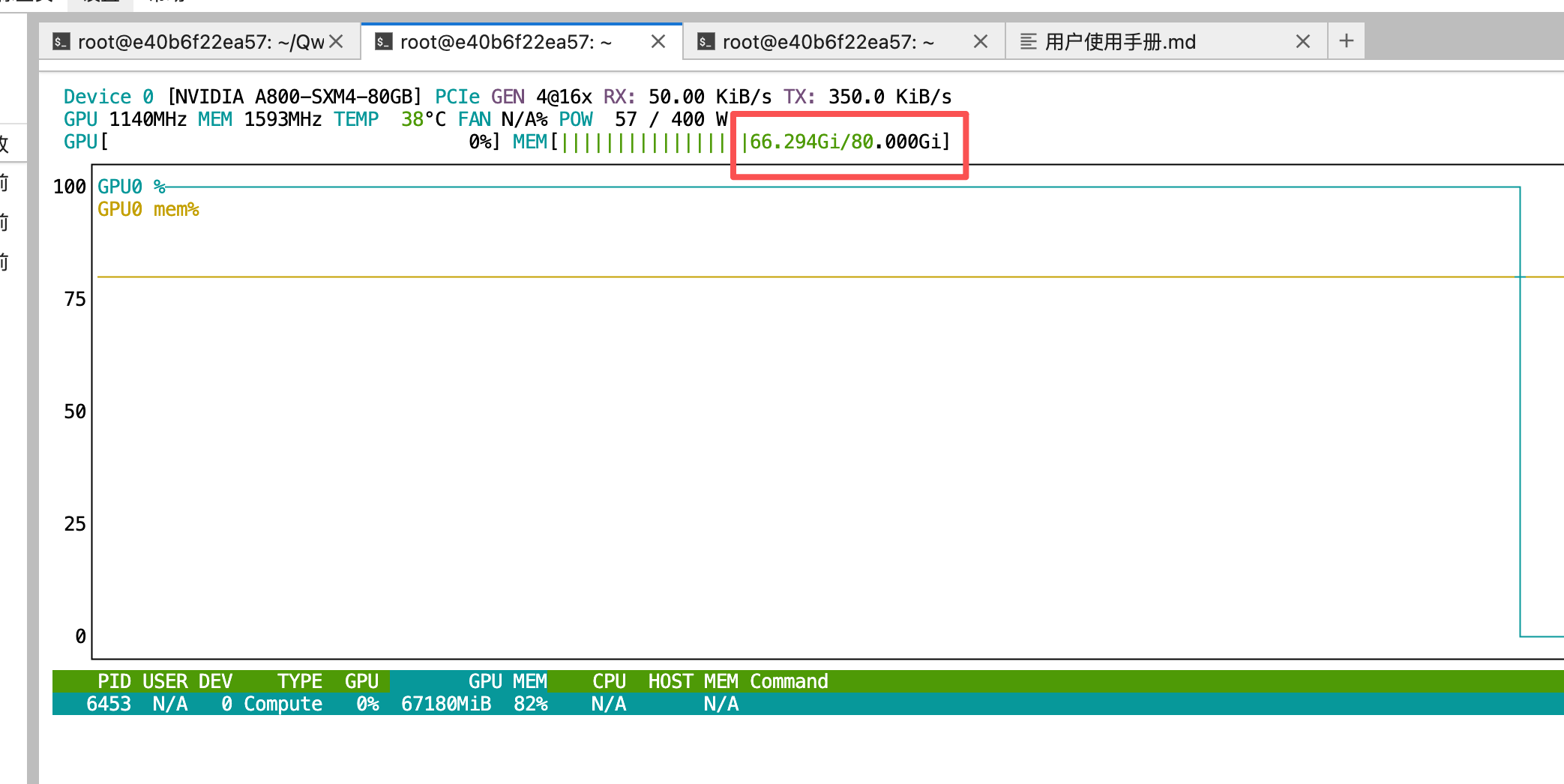
运行界面截图

Qwen Image Edit 2511 用户使用手册
基于Qwen-Image-Edit-2511模型的AI图像编辑工具 webUI二次开发by科哥 微信:312088415
快速开始
启动应用
./start_app.sh
启动后,浏览器访问:http://localhost:7860
系统特性
🚀 80GB显卡极致优化
针对80GB显存显卡(如A100 80GB、A800 80GB)的专属优化:
优化效果:
- 全部模型组件驻留GPU(Transformer + Text Encoder + VAE)
- 无CPU-GPU数据传输瓶颈
- 启用Flash Attention 2加速
- 预期速度:15-25秒/图(质量模式)
- 显存占用:~51GB
启动时显示:
🎯 自动选择策略: 至尊旗舰级极速模式(80GB+)
理由: 85GB显存充足,全部模型GPU驻存+Flash Attention 2(无CPU瓶颈)
预期速度: 15-25秒/图
显存占用: ~51GB
📁 图片自动保存
生成的图片会自动保存到项目 outputs/ 目录:
outputs/
├── out_1735223456789_1.png
├── out_1735223567890_1.png
├── out_1735223567890_2.png
└── ...
文件命名规则:out_{时间戳}_{序号}.png
📝 实时日志
运行日志实时输出到:/root/运行实时日志.log
查看实时日志:
tail -f /root/运行实时日志.log
性能参考
根据你的GPU配置,系统会自动选择最优策略:
| GPU类型 | 显存 | 预期速度 | 优化策略 |
|---|---|---|---|
| A100/A800 80GB | 80GB+ | 15-25秒/图 | 全部模型GPU驻存 + Flash Attention 2 |
| RTX 4090 48GB | 48GB | 20-30秒/图 | Trans:GPU, VAE/TE:CPU |
| RTX 4090 24GB | 24GB | 90-120秒/图 | Sequential Offload |
| RTX 4080 | 16GB | 120-180秒/图 | 激进优化 |
| RTX 4070Ti | 12GB | 200-300秒/图 | 极限优化 |
功能介绍
本工具提供4大核心功能,每个功能都有独立的标签页:
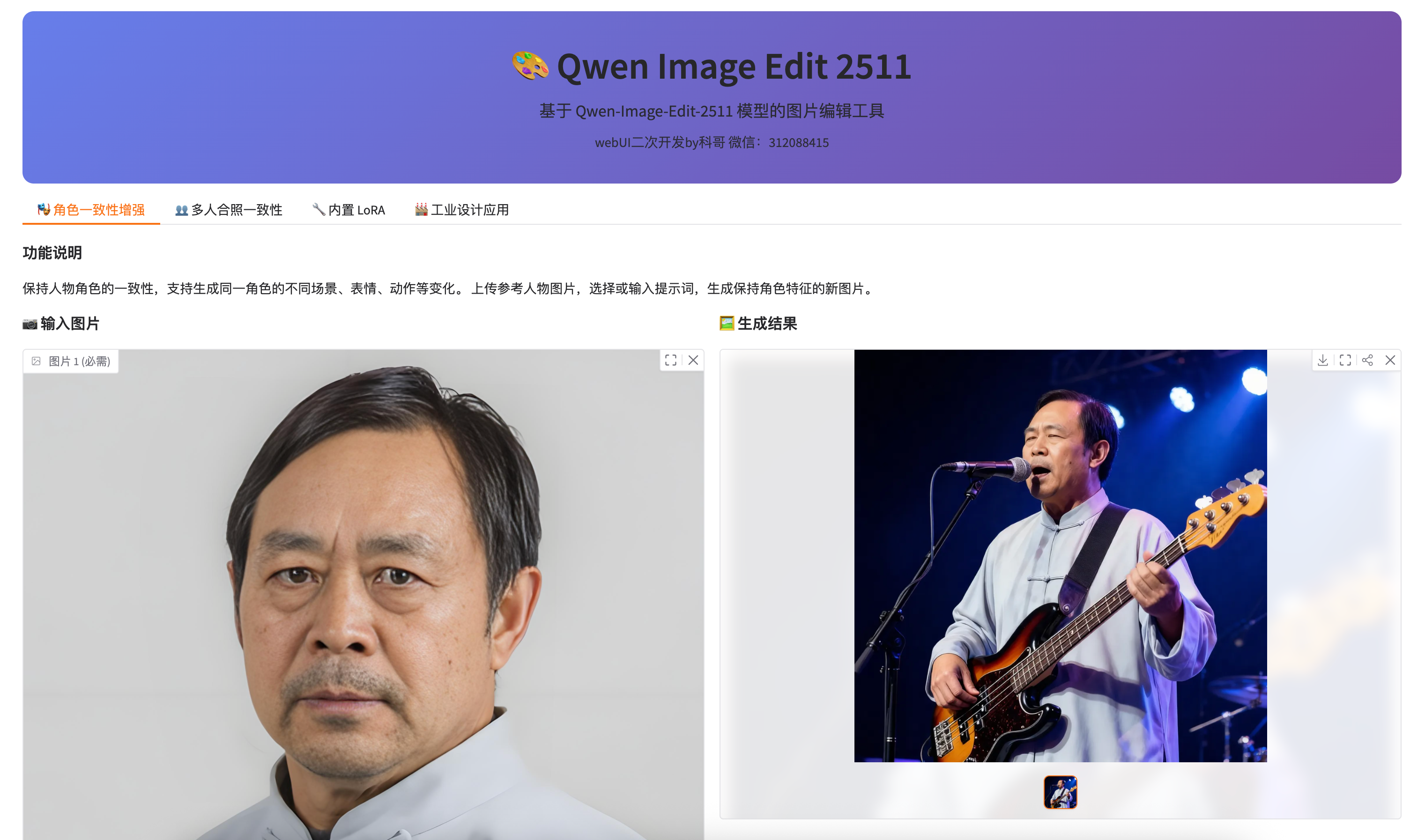
1. 角色一致性增强
功能说明:保持人物角色的一致性,生成同一角色的不同场景、表情、动作。
使用场景:
- 为小说/漫画角色生成不同场景的插图
- 制作角色设定图(不同表情、动作)
- 生成角色在不同环境下的效果图
操作步骤:
- 上传参考图片:点击"上传图片",选择包含目标人物的照片
- 输入提示词:描述你想要的场景/动作/表情
- 示例:
在海边散步,微笑,阳光明媚 - 示例:
穿着西装,在办公室,严肃表情
- 示例:
- 调整参数(可选):
- 推理步数:10-100步,越多质量越高但速度越慢(推荐40步)
- True CFG Scale:1.0-10.0,控制提示词影响力(推荐4.0)
- Guidance Scale:0.0-5.0,额外引导(推荐1.0)
- 随机种子:固定种子可复现结果
- 点击"生成图片":等待生成
- 查看结果:生成的图片显示在右侧,并自动保存到
outputs/目录
提示词技巧:
- ✅ 具体描述场景:
在咖啡厅,坐在窗边,喝咖啡 - ✅ 描述表情动作:
微笑,挥手,跳跃 - ✅ 描述环境光线:
阳光明媚,夕阳,夜晚灯光 - ❌ 避免过于抽象:
很美、好看
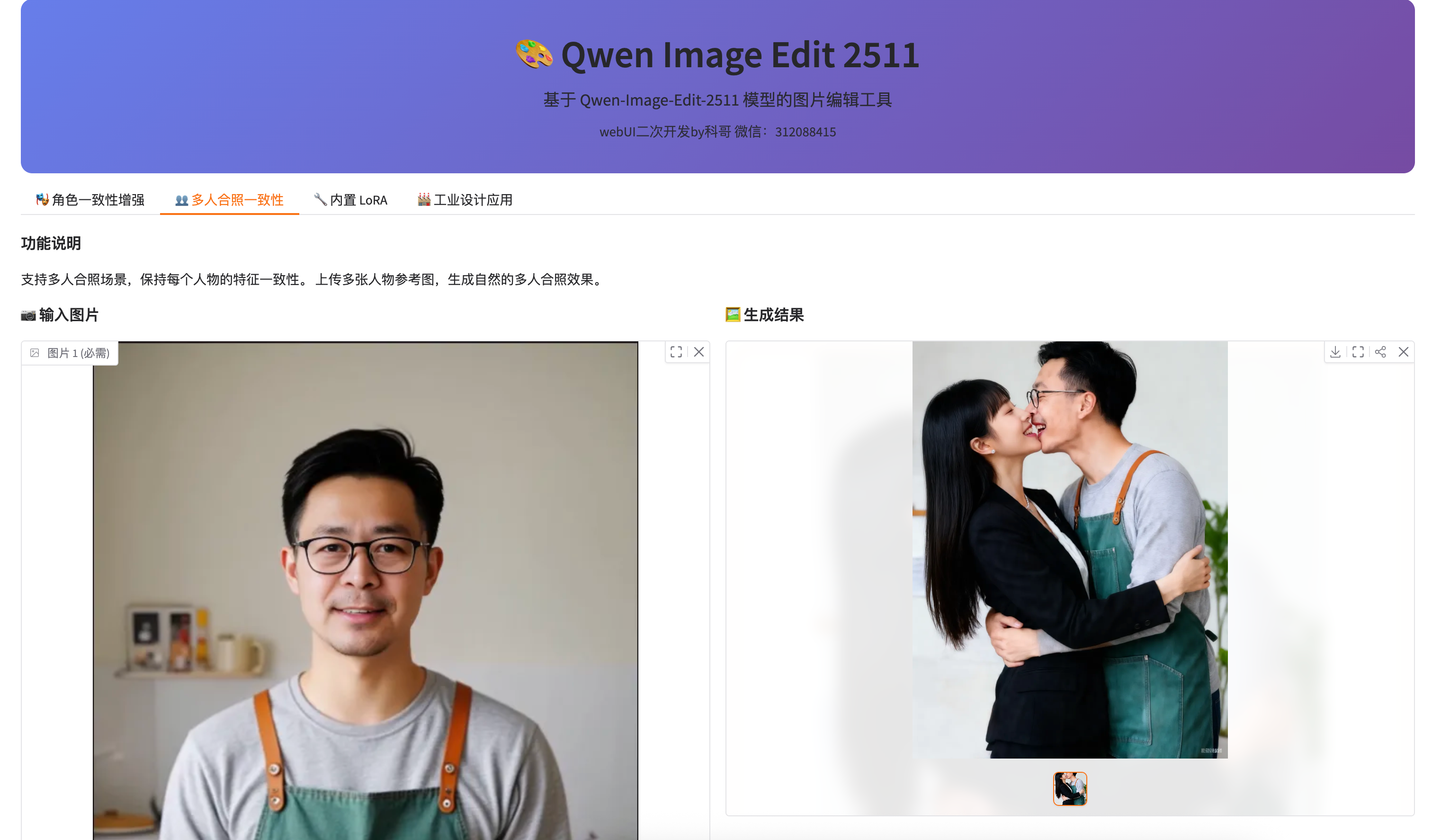
2. 多人合照一致性
功能说明:支持多人合照场景,保持每个人物的特征一致性。
使用场景:
- 生成家庭合照
- 制作团队照片
- 创建多角色场景图
操作步骤:
- 上传参考图片:上传包含多人的照片
- 输入提示词:描述合照场景
- 示例:
三个人在公园里,背景是樱花树 - 示例:
全家福,在客厅沙发上,温馨氛围
- 示例:
- 调整参数:同"角色一致性增强"
- 生成图片
3. 内置 LoRA
功能说明:模型已内置社区流行的LoRA能力,无需额外加载。
支持的LoRA:
- 光照增强:真实光照控制,调整图片光线效果
- 视角变换:生成新的视角/镜头角度(平移、旋转等)
使用方法:
光照增强
提示词示例:
增强光照,明亮,高光柔和光线,暖色调戏剧性光影,强对比
视角变换
提示词示例:
俯视角度,从上往下看仰视角度,从下往上看侧面视角,45度角广角镜头,全景
4. 工业设计应用
功能说明:适用于工业设计场景,支持产品渲染、材质变换、设计迭代。
使用场景:
- 产品效果图生成
- 材质/颜色变换
- 设计方案快速迭代
操作步骤:
- 上传产品设计图:草图、3D渲染图或实物照片
- 输入提示词:描述想要的材质、颜色、场景
- 示例:
金属材质,银色,工作室光照 - 示例:
把头盔变成银灰色 - 示例:
透明玻璃材质,蓝色,反光效果
- 示例:
- 生成图片
材质关键词:
- 金属:
金属材质,不锈钢,铝合金,铜质 - 木质:
木质纹理,橡木,胡桃木,竹子 - 塑料:
塑料材质,磨砂,光滑,透明 - 玻璃:
玻璃材质,透明,磨砂玻璃,彩色玻璃 - 布料:
布料材质,棉质,丝绸,皮革
参数说明
基础参数
| 参数 | 范围 | 默认值 | 说明 |
|---|---|---|---|
| 推理步数 | 10-100 | 40 | 生成质量,越高越好但越慢 |
| 生成数量 | 1-4 | 1 | 一次生成的图片数量 |
| True CFG Scale | 1.0-10.0 | 4.0 | 提示词影响力 |
| Guidance Scale | 0.0-5.0 | 1.0 | 额外引导强度 |
| 随机种子 | 0或正整数 | 0 | 固定值可复现结果 |
参数调优建议
追求质量:
- 推理步数:50
- True CFG Scale:5.0-7.0
追求速度:
- 推理步数:20-25
- True CFG Scale:3.0-4.0
平衡模式(推荐):
- 推理步数:40
- True CFG Scale:4.0
提示词编写技巧
1. 结构化描述
推荐格式:主体 + 动作/表情 + 场景 + 光线 + 风格
示例:
一个女孩,微笑,在咖啡厅,坐在窗边,阳光透过窗户,温暖色调
2. 使用具体词汇
| ❌ 模糊 | ✅ 具体 |
|---|---|
| 好看 | 精致五官,清晰细节 |
| 漂亮 | 柔和光线,自然妆容 |
| 很美 | 高清画质,专业摄影 |
3. 场景描述要点
环境:室内/室外、具体地点(咖啡厅、公园、办公室) 光线:阳光、夕阳、夜晚、工作室光照 氛围:温馨、严肃、活泼、宁静 细节:背景元素、道具、服装
4. 常用关键词
表情:
- 微笑、大笑、严肃、惊讶、思考、平静
动作:
- 站立、坐着、走路、跑步、跳跃、挥手
光线:
- 阳光明媚、柔和光线、戏剧性光影、逆光、侧光
风格:
- 写实风格、电影感、专业摄影、高清画质
示例提示词
角色一致性
圣诞节主题,一位纯欲气质的美少女,松散的双麻花辫,少女气质,无辜眼神,头戴圣诞树造型发饰,冷白皮,纯欲朦胧滤镜,双手拿着圣诞老人玩偶,庆祝感眼神和表情,轻轻歪头,穿毛绒红色上衣,暖白背景、棚拍柔光
四宫格表情包。左上:双手举过头顶比双"V",惊讶活泼。右上:双手托住脸颊,闭眼嘟嘴,可爱娇憨。左下:侧头wink,吐舌,单手比"V",俏皮搞怪。右下:双臂交叉,眉头微皱,嘟嘴小傲娇。卡通元素彩色背景,二次元动漫风格
真人与卡通壁画合影,竖版3:4。真人原样保留服装发型妆容在左侧,背后墙面绘制1:1对应卡通壁画,厚涂质感动漫风格大眼柔和轮廓,完整复刻发型服装配饰细节。墙面添加彩色涂鸦爱心笑脸,地面点缀飞溅颜料
工业设计
金属材质,银色,工作室光照,产品摄影
木质纹理,深棕色,自然光,简约设计
透明玻璃材质,蓝色,反光效果,科技感
常见问题
Q1: 生成速度慢怎么办?
A: 这是正常现象。系统已根据你的GPU自动选择最优策略:
- 80GB+ GPU:15-25秒/图
- 48GB GPU:20-30秒/图
- 24GB GPU:90-120秒/图
- 16GB GPU:120-180秒/图
Q2: 生成的图片不符合预期?
A: 尝试以下方法:
- 更详细的提示词描述
- 调整True CFG Scale(增加到5.0-7.0)
- 增加推理步数(提高到50)
- 更换参考图片(更清晰、光线更好)
Q3: 如何复现之前的结果?
A: 记录生成时使用的随机种子,下次使用相同的种子、提示词和参数即可复现。
Q4: 图片保存在哪里?
A: 自动保存到项目 outputs/ 目录,文件名格式为 out_{时间戳}_{序号}.png
Q5: 如何查看运行日志?
A: 实时日志保存在 /root/运行实时日志.log,使用 tail -f /root/运行实时日志.log 查看。
Q6: 可以同时生成多张图片吗?
A: 可以,将"生成数量"设置为2-4。但会增加生成时间和显存占用。
Q7: 支持哪些图片格式?
A: 支持常见格式:JPG、PNG、WEBP等。
Q8: 生成的图片分辨率是多少?
A: 由模型决定,通常为1024x1024。
Q9: 80GB显卡有什么特殊优化?
A: 至尊旗舰模式将全部模型组件驻留GPU,消除CPU-GPU传输瓶颈,速度提升40%+。
最佳实践
1. 准备高质量参考图
- ✅ 清晰、光线良好
- ✅ 主体明确、背景简洁
- ✅ 分辨率足够(建议512x512以上)
- ❌ 避免模糊、过暗、过曝的照片
2. 迭代优化
- 先用默认参数快速生成
- 根据结果调整提示词
- 微调参数(True CFG Scale、推理步数)
- 多次尝试找到最佳配置
3. 批量生成
- 固定种子,批量测试不同提示词
- 记录效果好的提示词模板
- 建立自己的提示词库
4. 性能测试
运行性能测试了解你的GPU实际表现:
python benchmark_test.py
测试会显示:
- 优化组件状态
- 当前使用的策略
- 不同模式的推理速度
- GPU利用率分析
技术支持
遇到问题?
- 微信:312088415(科哥)
反馈建议: 欢迎提供使用反馈和改进建议!
祝你使用愉快!
 认证作者
认证作者

 支持自启动
支持自启动