LightOnOCR-2高效的1B参数视觉语言模型用于OCR识别pdf转文本jpg转文本图片转文本 二次开发构建by科哥
LightOnOCR-2高效的1B参数视觉语言模型用于OCR识别pdf转文本jpg转文本图片转文本 二次开发构建by科哥
 1
10元/小时
v2.0
LightOnOCR-2高效的1B参数视觉语言模型用于OCR识别pdf转文本jpg转文本图片转文本 二次开发构建by科哥
镜像简介
本镜像基于轻量高效的1B参数视觉语言模型LightOnOCR-2,专注于高精度OCR文字识别。支持PDF、JPG等多种格式的文档与图像快速转换为可编辑文本,适用于文档数字化、资料归档、信息提取与无障碍阅读等场景,提供即开即用、准确高效的文字识别解决方案。
镜像使用教程
创建实例后点击【SD-WebUI】即可进入操作页面
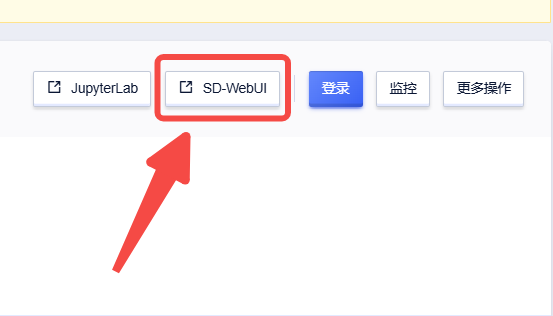
运行界面
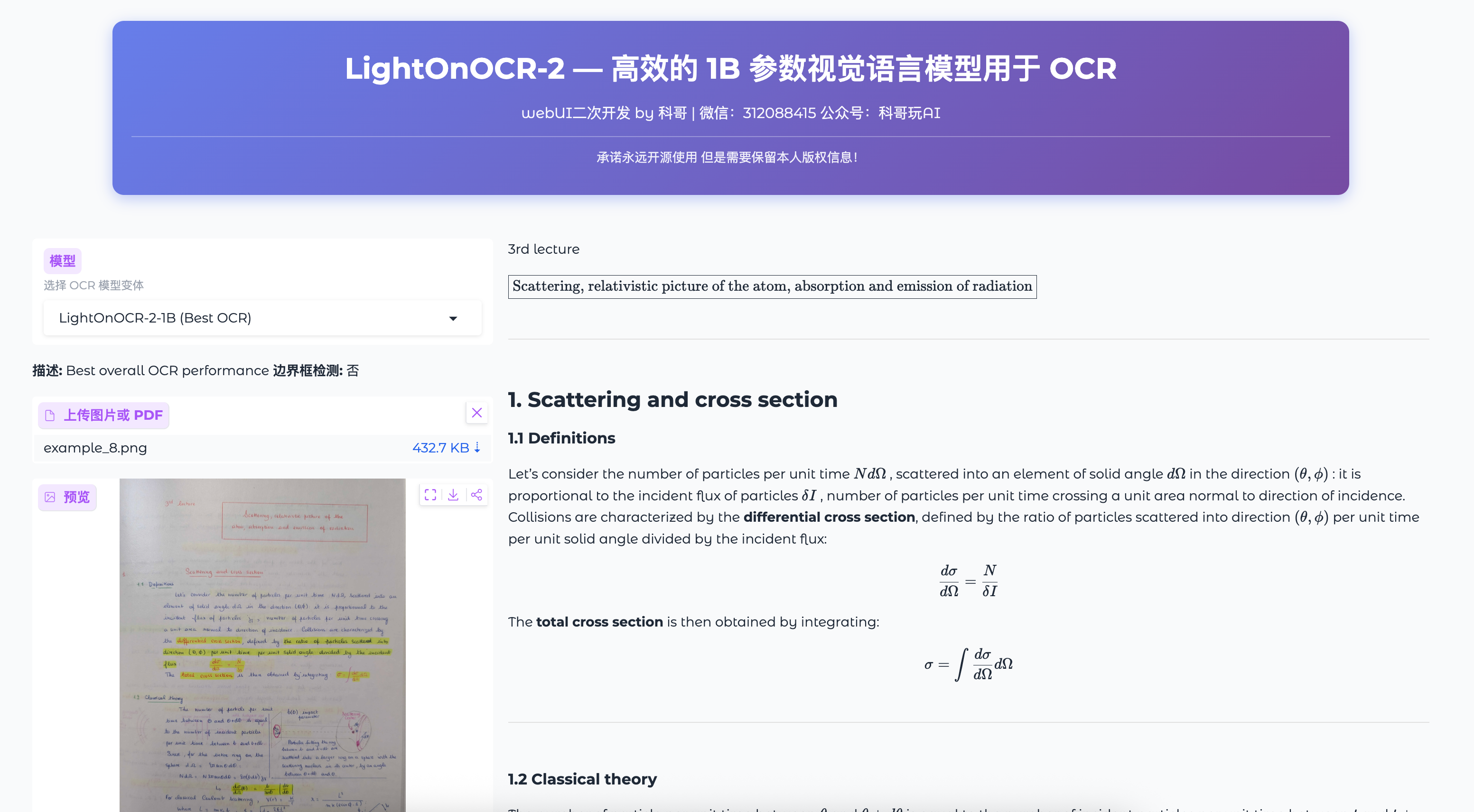
LightOnOCR-2 用户使用手册
本手册指导用户如何使用 LightOnOCR-2 Web 界面进行 OCR 文本提取。
一、访问地址
本地访问: http://localhost:7860
局域网访问: http://[服务器IP]:7860
外网访问: http://[域名或公网IP]:7860
二、界面介绍
2.1 标题区域
显示项目名称和开发信息:
- LightOnOCR-2 — 高效的 1B 参数视觉语言模型用于 OCR
- 开发者:科哥(微信:312088415 | 公众号:科哥玩AI)
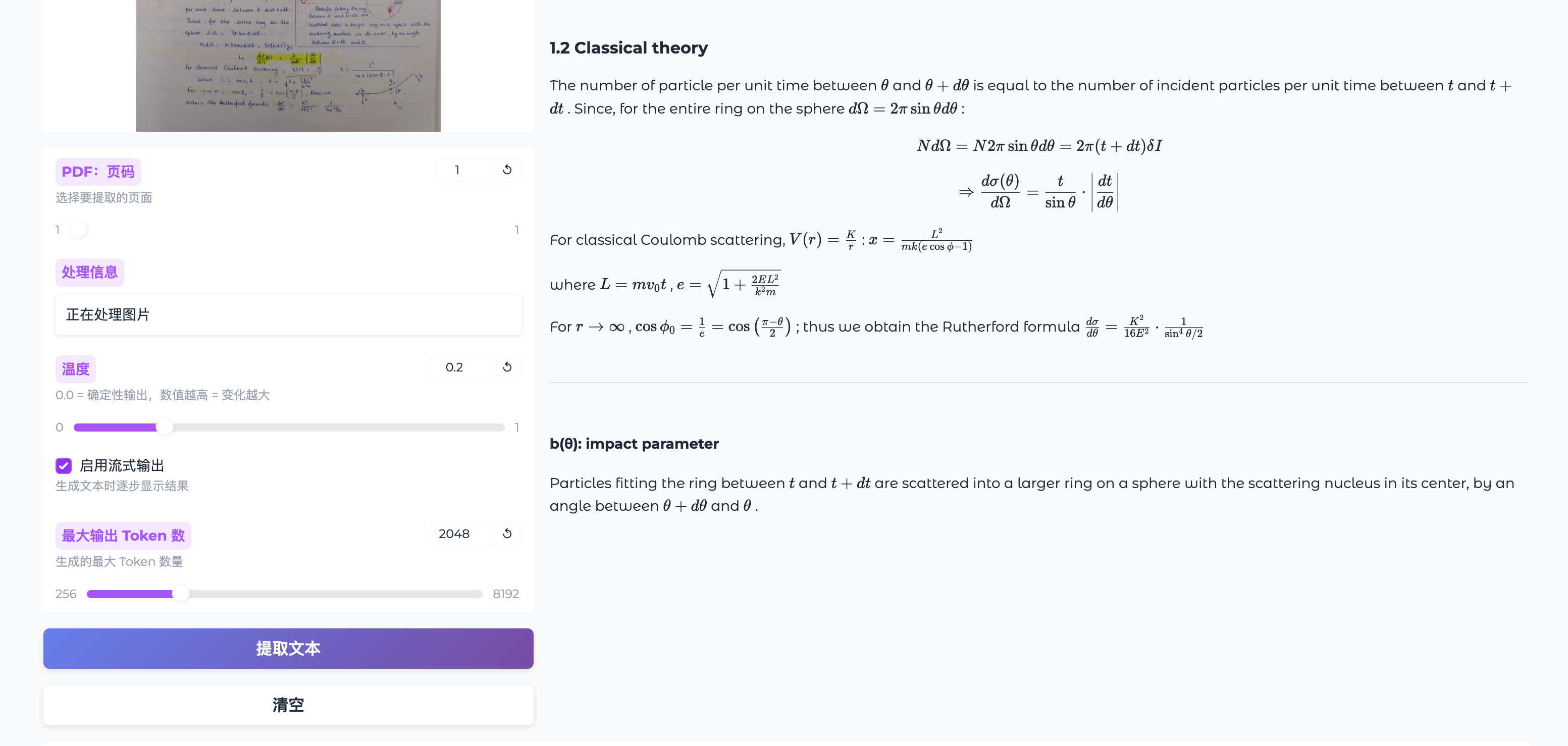
2.2 左侧控制面板
| 控件 | 功能说明 |
|---|---|
| 模型 | 下拉选择 6 种不同的 OCR 模型 |
| 模型信息 | 显示当前模型的描述和是否支持边界框检测 |
| 上传图片或 PDF | 点击上传或拖拽图片/PDF 文件 |
| 预览 | 显示上传图片的预览效果 |
| PDF:页码 | 选择 PDF 中要提取的页面(仅 PDF 文件) |
| 处理信息 | 显示当前处理状态 |
| 温度 | 控制输出随机性,0.0 = 确定性,数值越高 = 变化越大 |
| 启用流式输出 | 勾选后文本会逐步显示 |
| 最大输出 Token 数 | 设置生成文本的最大长度 |
| 提取文本 | 开始 OCR 文本提取 |
| 清空 | 清空所有输入和输出 |
2.3 右侧输出区域
| 区域 | 功能说明 |
|---|---|
| 提取文本(渲染) | 显示格式化后的提取结果,支持 Markdown 渲染 |
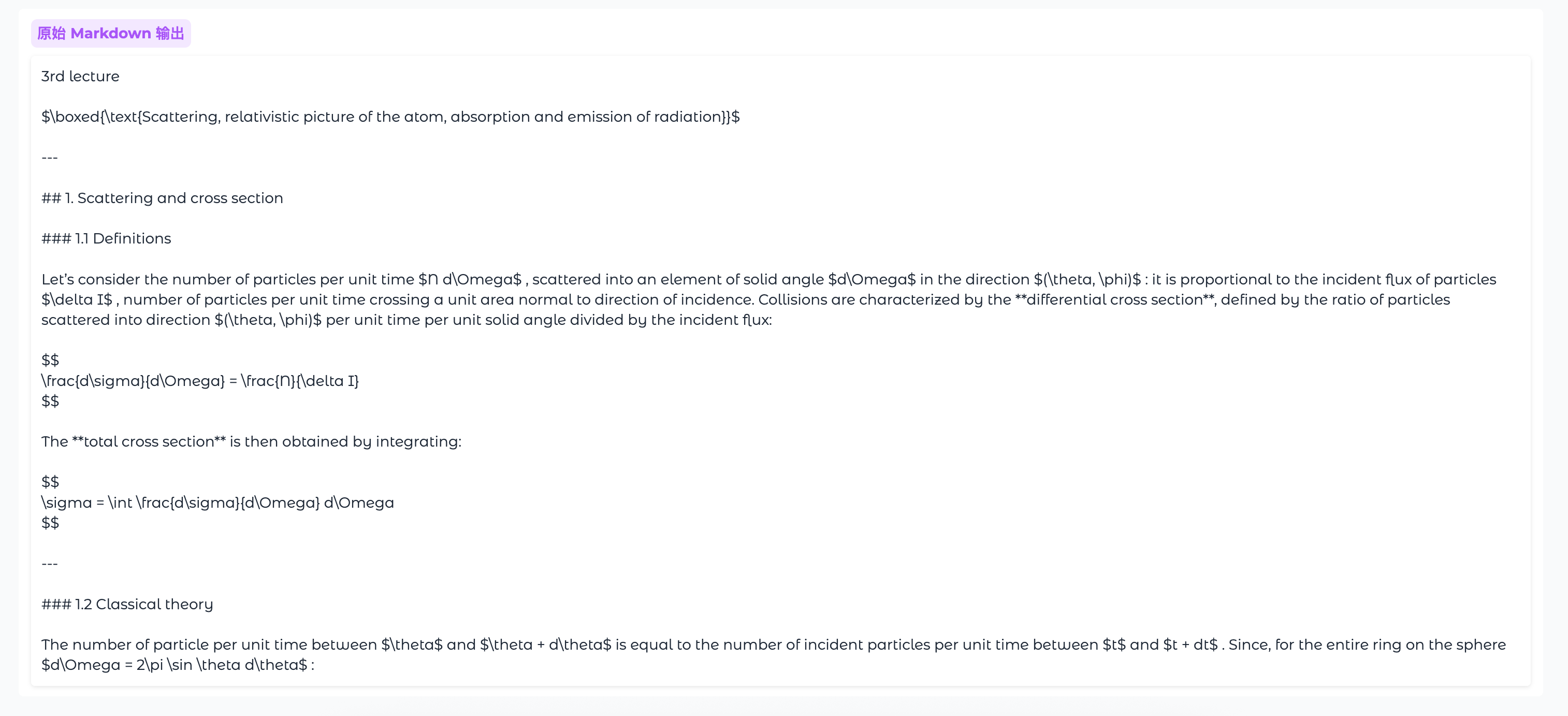
| 原始 Markdown 输出 | 显示原始 Markdown 格式的文本 |
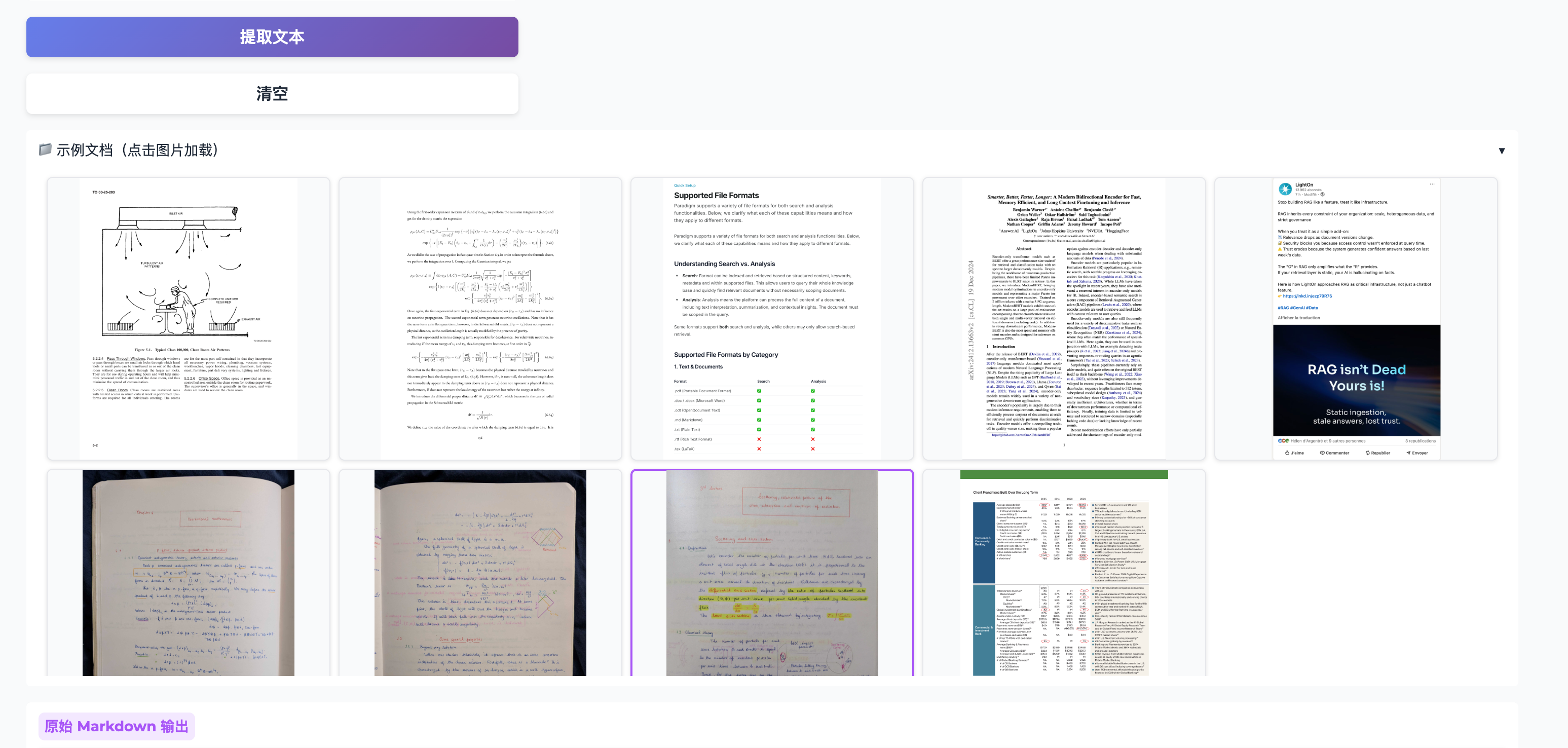
2.4 示例文档
点击任意示例图片可自动加载到输入框,方便快速体验。
三、模型选择说明
LightOnOCR-2 提供以下 6 种模型:
| 模型名称 | 描述 | 边界框检测 | 适用场景 |
|---|---|---|---|
| LightOnOCR-2-1B (Best OCR) | 最佳综合 OCR 性能 | 否 | 通用 OCR 任务,追求最高准确率 |
| LightOnOCR-2-1B-bbox (Best Bbox) | 最佳边界框检测 | 是 | 需要定位文本区域或需要裁剪功能 |
| LightOnOCR-2-1B-base | 基础 OCR 模型 | 否 | 快速 OCR,对准确率要求不高的场景 |
| LightOnOCR-2-1B-bbox-base | 基础边界框模型 | 是 | 快速边界框检测 |
| LightOnOCR-2-1B-ocr-soup | OCR soup 变体 | 否 | 特殊格式文档处理 |
| LightOnOCR-2-1B-bbox-soup | 边界框 soup 变体 | 是 | 复杂版面布局文档处理 |
推荐选择:
- 首次使用推荐:LightOnOCR-2-1B (Best OCR)
- 处理表格、表单:选择带 bbox 的模型
- 需要快速处理:选择 base 系列
四、使用步骤
4.1 提取图片文本
- 选择模型:从下拉菜单选择适合的模型(默认为最佳 OCR 模型)
- 上传图片:点击「上传图片或 PDF」或直接拖拽图片文件
- 调整参数(可选):
- 调整「温度」控制输出稳定性
- 设置「最大输出 Token 数」控制输出长度
- 开始提取:点击「提取文本」按钮
- 查看结果:右侧显示提取的文本
4.2 提取 PDF 文本
- 上传 PDF:选择 PDF 文件上传
- 选择页码:使用「PDF:页码」滑块选择要提取的页面
- 预览页面:可在「预览」区域查看当前页
- 开始提取:点击「提取文本」
- 多页处理:重复步骤 2-4 处理其他页面
4.3 使用示例图片
- 点击「示例文档」折叠栏中的任意图片
- 图片自动加载到输入框
- 点击「提取文本」查看效果
五、参数说明
温度 (Temperature)
| 值 | 效果 | 适用场景 |
|---|---|---|
| 0.0 | 完全确定性,结果稳定 | 表单、票据等结构化文本 |
| 0.2-0.4 | 较少变化,推荐默认值 | 大多数 OCR 场景 |
| 0.5-0.7 | 中等变化 | 手写文本、模糊图片 |
| 0.8-1.0 | 高变化,结果可能不稳定 | 创意性文本处理 |
最大输出 Token 数
| 值 | 适用场景 |
|---|---|
| 256 | 短文本、标题提取 |
| 1024 | 单段文本提取 |
| 2048(默认) | 完整文档提取 |
| 4096+ | 超长文档、多页内容 |
流式输出
- 启用:文本逐步显示,可实时查看提取进度
- 禁用:等待完整提取后一次性显示
六、支持文件格式
| 类型 | 支持格式 |
|---|---|
| 图片 | .png, .jpg, .jpeg |
| 文档 |
推荐格式:
- 图片:PNG(无损)、JPG(较小文件)
- 扫描件:建议先进行图片增强和去噪处理
七、常见问题
Q1: 提取的文本不准确怎么办?
解决方案:
- 尝试切换不同的模型
- 降低「温度」参数(设置为 0.1-0.2)
- 增加图片分辨率或清晰度
- 选择带边界框的模型进行区域识别
Q2: 处理速度很慢?
解决方案:
- 选择 base 系列模型(速度更快)
- 减小「最大输出 Token 数」
- 检查服务器 GPU 资源占用情况
Q3: PDF 多页如何处理?
解决方案:
- 使用「PDF:页码」滑块逐页处理
- 选择带边界框的模型,可裁剪识别区域
- 后续可考虑 PDF 批量处理工具
Q4: 如何处理表格或表单?
解决方案:
- 选择 bbox 系列模型
- 模型会自动识别表格结构
- 边界框模型支持区域裁剪,可分别处理不同区域
Q5: 提示"请先上传图片或 PDF 文件"?
原因:未上传文件就点击了「提取文本」
解决:先上传图片或 PDF 文件
八、使用技巧
1. 图片预处理
- 提高图片分辨率和清晰度可显著提升准确率
- 对扫描件建议先进行倾斜校正
- 去除图片噪点和阴影
2. 模型选择策略
- 正式文档:使用 LightOnOCR-2-1B (Best OCR)
- 表格表单:使用 LightOnOCR-2-1B-bbox
- 快速验证:使用 base 系列模型
- 复杂版面:使用 soup 系列模型
3. 参数调优
- 首次使用保持默认参数
- 结构化文本降低温度值
- 模糊或手写文本可适当提高温度值
九、功能特色
- 多模型支持:6 种模型满足不同场景需求
- 边界框检测:精确识别文本区域,支持裁剪
- 流式输出:实时显示提取进度
- PDF 支持:可直接处理 PDF 文件
- 示例文档:提供 9 张示例图片快速体验
- 中英文界面:完全本地化,使用更便捷
十、技术支持
- 开发者:科哥
- 微信:312088415
- 公众号:科哥玩AI
最后更新: 2026-01-24
bug反馈可以加入科哥专属群交流➕ 广告勿进!

科哥在UCloud镜像列表【不断更新中】:
@鸡你太美 认证作者
认证作者
认证作者
镜像信息
已使用3 次
运行时长
2 H
 支持自启动
支持自启动镜像大小
40GB
最后更新时间
2026-04-27
支持卡型
3090RTX50系RTX40系48G RTX40系3080Ti2080Ti2080A800H20P40V100SA100
+12
框架版本
CUDA版本
12.8
应用
JupyterLab: 8888
版本
v2.0
2026-04-27