Qwen3-TTS语音模型, | 声音克隆 | 语音定制 | 语音预设 |
阿里千问开源的最新语音类模型,显存占用小,生成速度快,支持10种主流语言。
 10
100元/小时
v2.0
v1.0
Qwen3-TTS 语音模型 ComfyUI版
镜像简介
本镜像为Qwen3-TTS语音模型第二版,新的插件支持单人上传语音克隆,语音个性设计生成,多人语音自定义生成等
使用教程
B站详细教程视频: https://www.bilibili.com/video/BV1eF63BWETh/
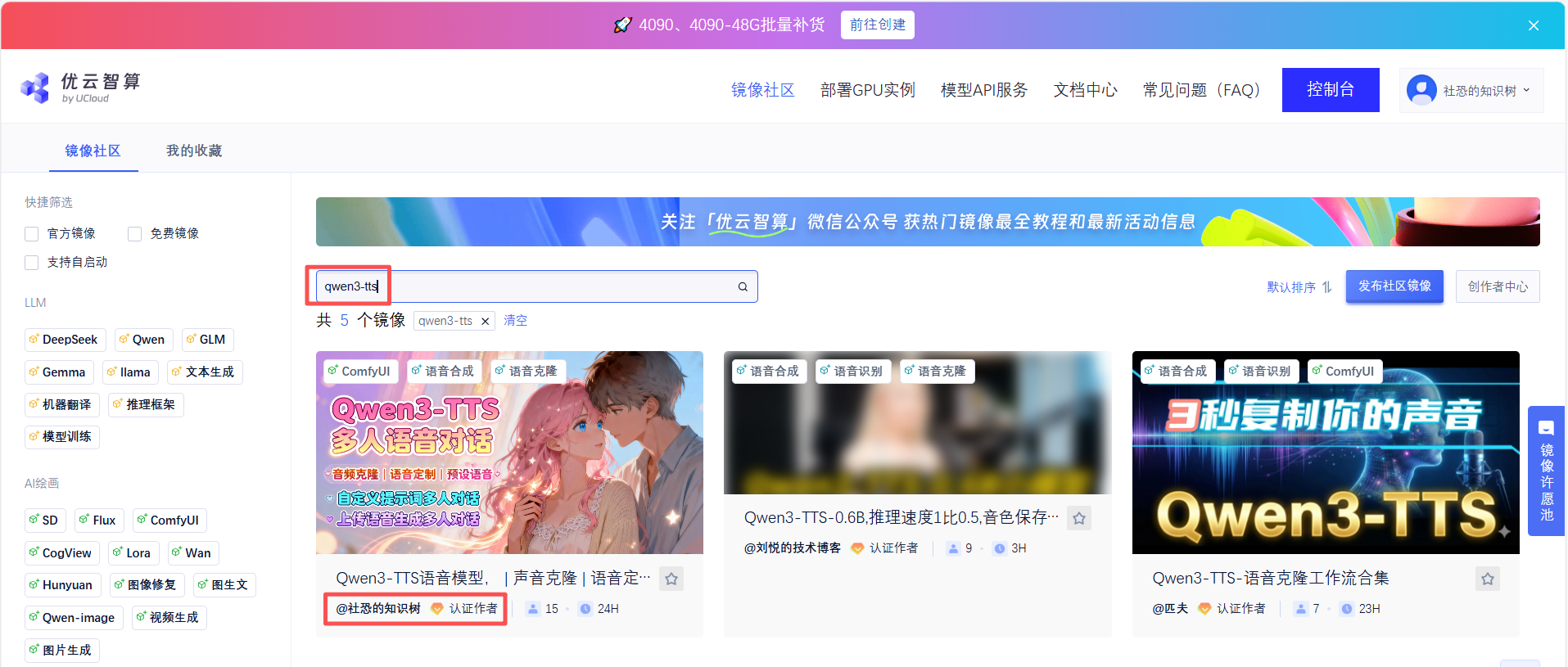
01 查找镜像部署
点击镜像社区输入"Qwen3-TTS",查找UP主制作的镜像,或者直接搜索用户社恐的知识树。
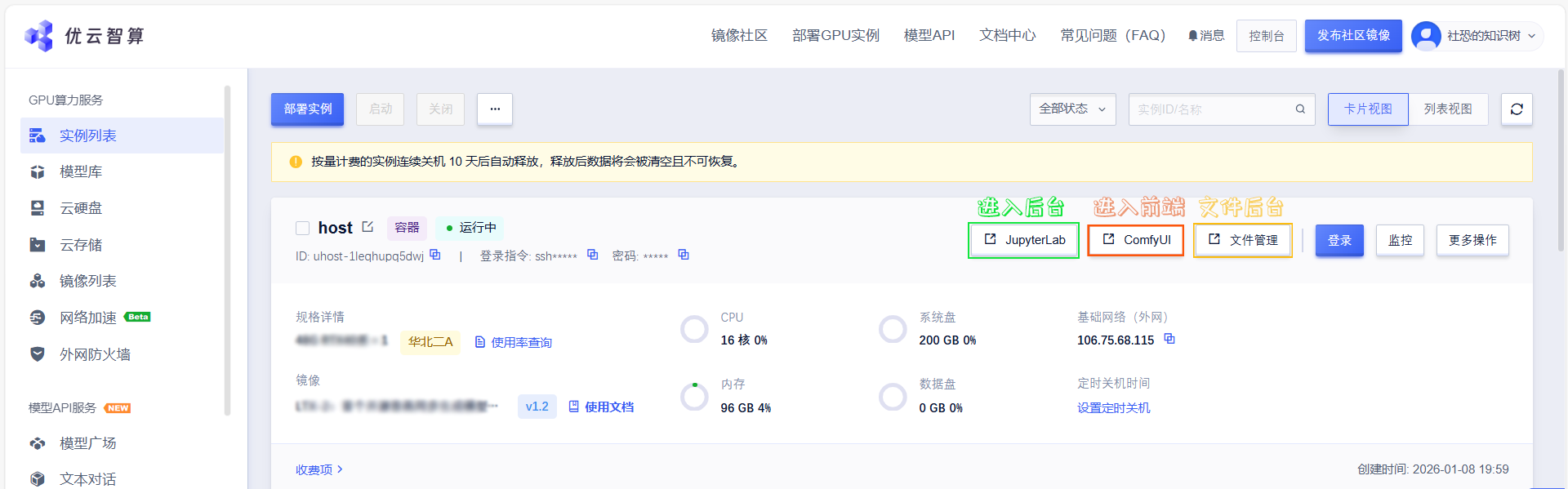
02 启动运行ComfyUI

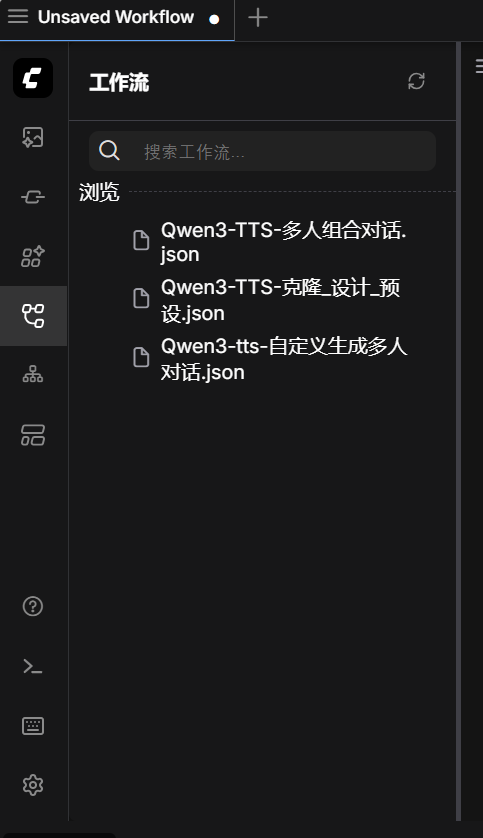
03 查找内置ComfyUI工作流
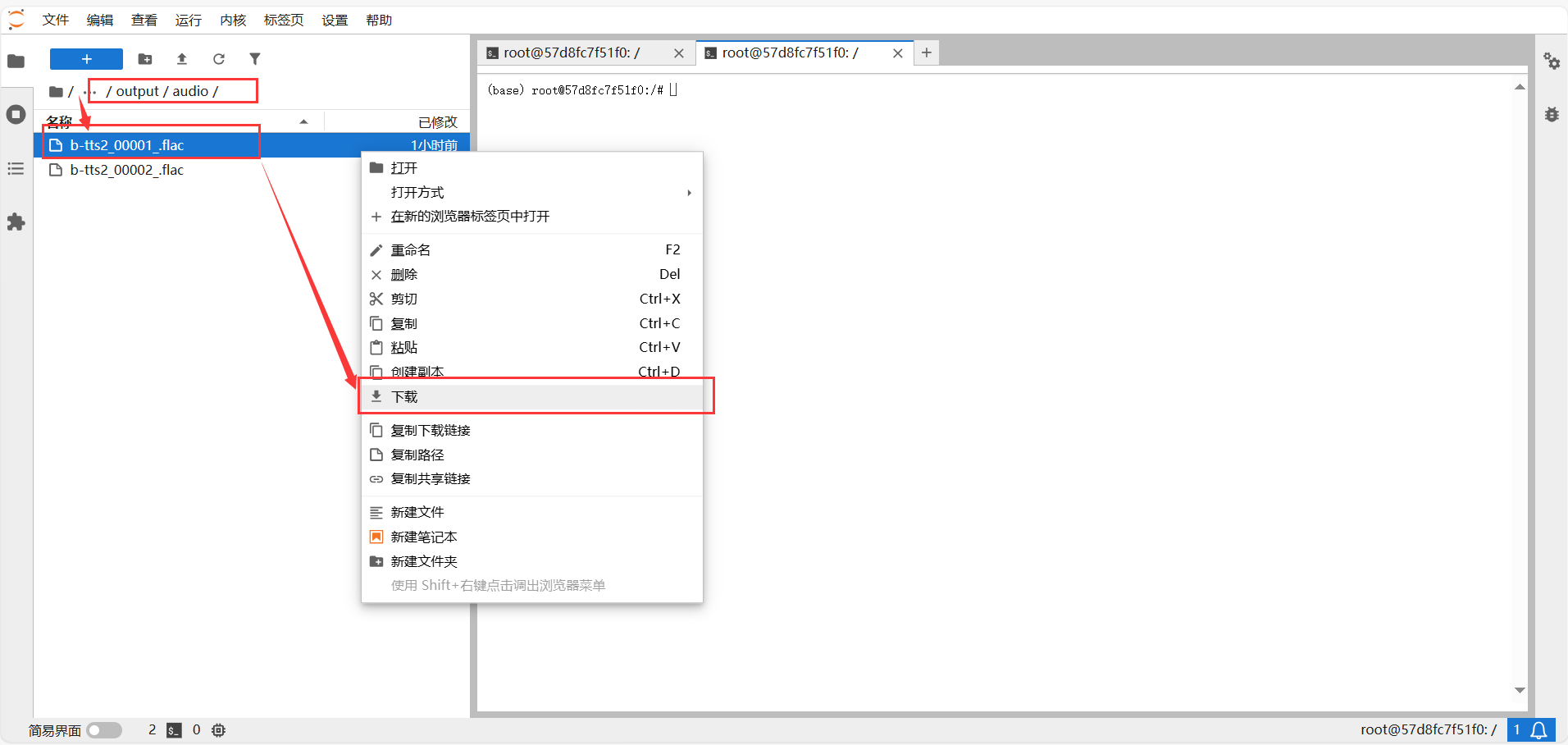
04 如何下载已经生成的文件到本地电脑
首先点击“JupyterLab”进入后台文件夹,其中Input是上传文件存放的位置,比如图片音频视频等,output文件夹是所有生成文件存放的位置,点击进入output文件夹,选中要下载的文件,右键点击弹出窗口选这下载即可
@社恐的知识树 认证作者
认证作者
认证作者
镜像信息
已使用118 次
运行时长
87 H
镜像大小
100GB
最后更新时间
2026-01-27
支持卡型
3090RTX40系3080Ti48G RTX40系
+4
框架版本
CUDA版本
12.8
应用
JupyterLab: 8888
自定义开放端口
8186
+1
版本
v2.0
2026-01-27
v1.0
2026-01-23