音频视频语音识别转文本字幕faster-whisper 1.2
将音频或视频文件语音识别转为文本文件或字幕文件
 22
220元/小时
v1.2
音频视频语音识别转文本及字幕
镜像简介
可以将mp3,wav音频文件或是mp4视频文件的语音识别转为文本或是字幕文件,基于当前最新模型,启用字级时间戳,识别效果快速准确。
使用教程
1、首先点击右侧蓝色按钮【使用该镜像创建实例】
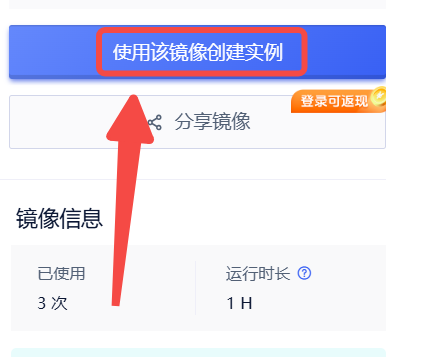
2、选择合适的GPU,点击下方蓝色按钮【立即部署】
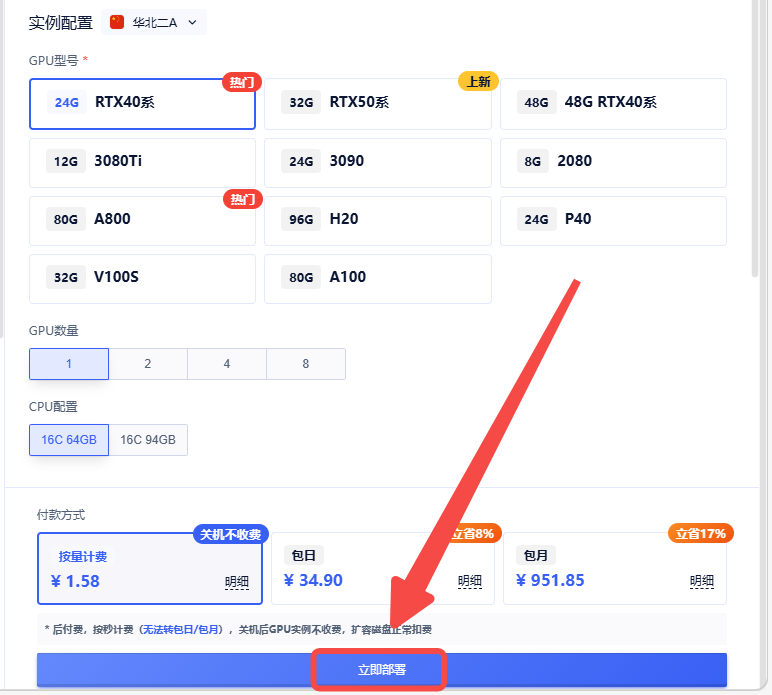
3、稍等一两分钟后实例便会运行,显示【运行中】后继续等待1分钟左右初始化,再点击右侧【SD-WebUI】按钮,即可打开WebUI操作界面

软件操作比较简单,按WebUI界面提示操作即可
@AI画师大阳 认证作者
认证作者
认证作者
镜像信息
已使用260 次
运行时长
2850 H
镜像大小
100GB
最后更新时间
2026-02-02
支持卡型
RTX40系20803080Ti309048G RTX40系2080TiH20A800P40A100RTX50系V100S
+12
框架版本
CUDA版本
12.8
应用
JupyterLab: 8888
版本
v1.2
2026-02-02