echomimic_v3阿里蚂蚁团队开源图片加声音生成说话数字人视频基于Comfyui加速和二次高清输出 构建By科哥
echomimic_v3阿里蚂蚁团队开源图片加声音生成说话数字人视频基于Comfyui加速和二次高清输出 构建By科哥
 3
30元/小时
v3.1
v3.0
EchoMimic V3支持40系列显卡一张照片一段音频生成半身数字人说话视频 支持手势动作
注意事项
- 如果输入音频带有背景音乐,可能会影响生成效果。建议加个去除背景音乐节点
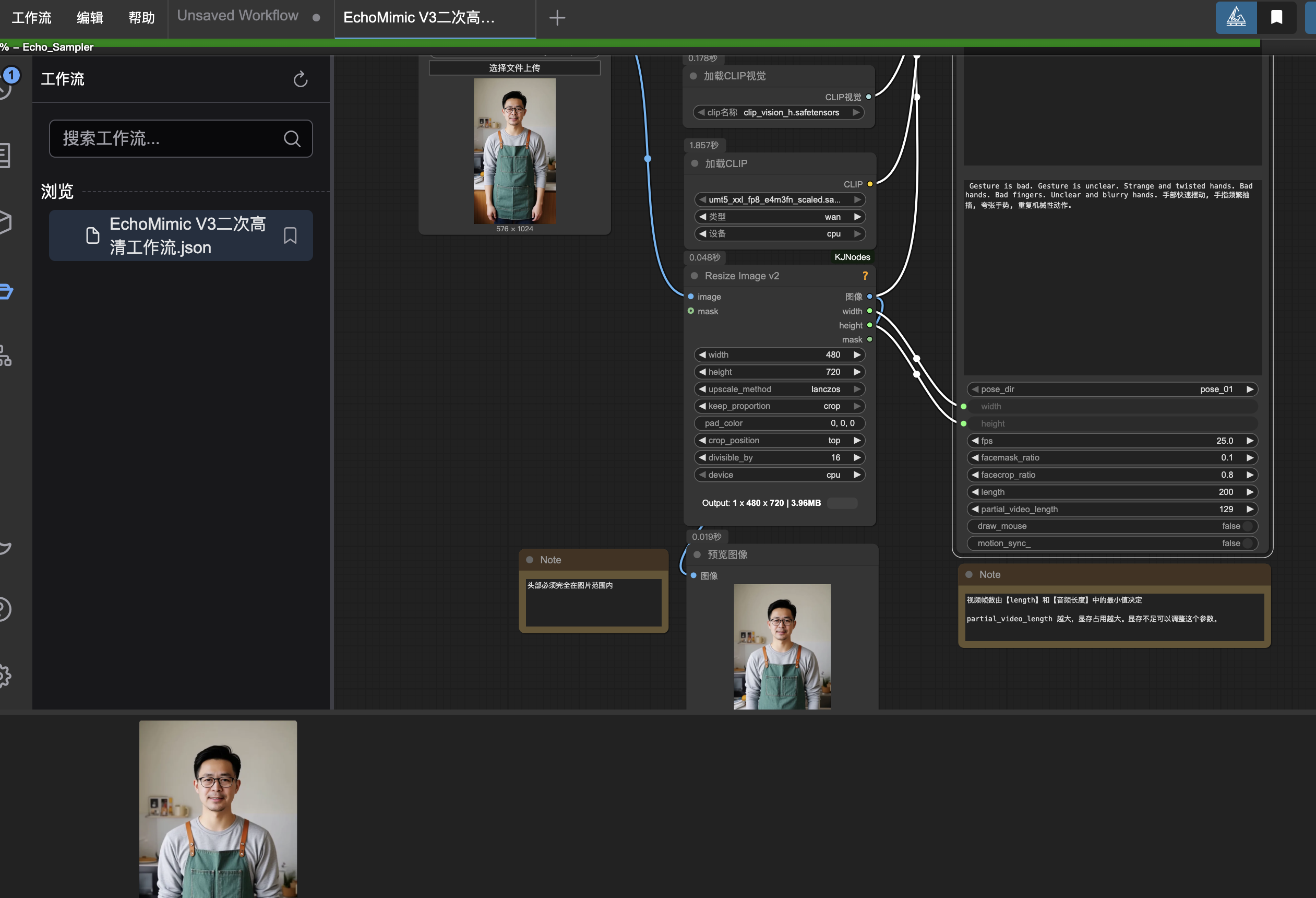
- 头部必须完全在图片内,否则会影响生成质量。
- 音频 CFG: audio_guidance_scale在 2 到 3 之间工作最佳。增加音频 CFG 值可以更好的唇部同步,而减少音频 CFG 值可以提高视觉质量。
- 文本CFG:guidance_scale在 3 到 6 之间工作最佳。增加文本CFG值可以更好地遵循提示,而减少文本CFG值可以提高视觉质量。* 采样步骤:谈话头需要5步,谈话身体需要15~25步。
- 参数 partial_video_length的值越大,占用显存越大,但运行次数减少。
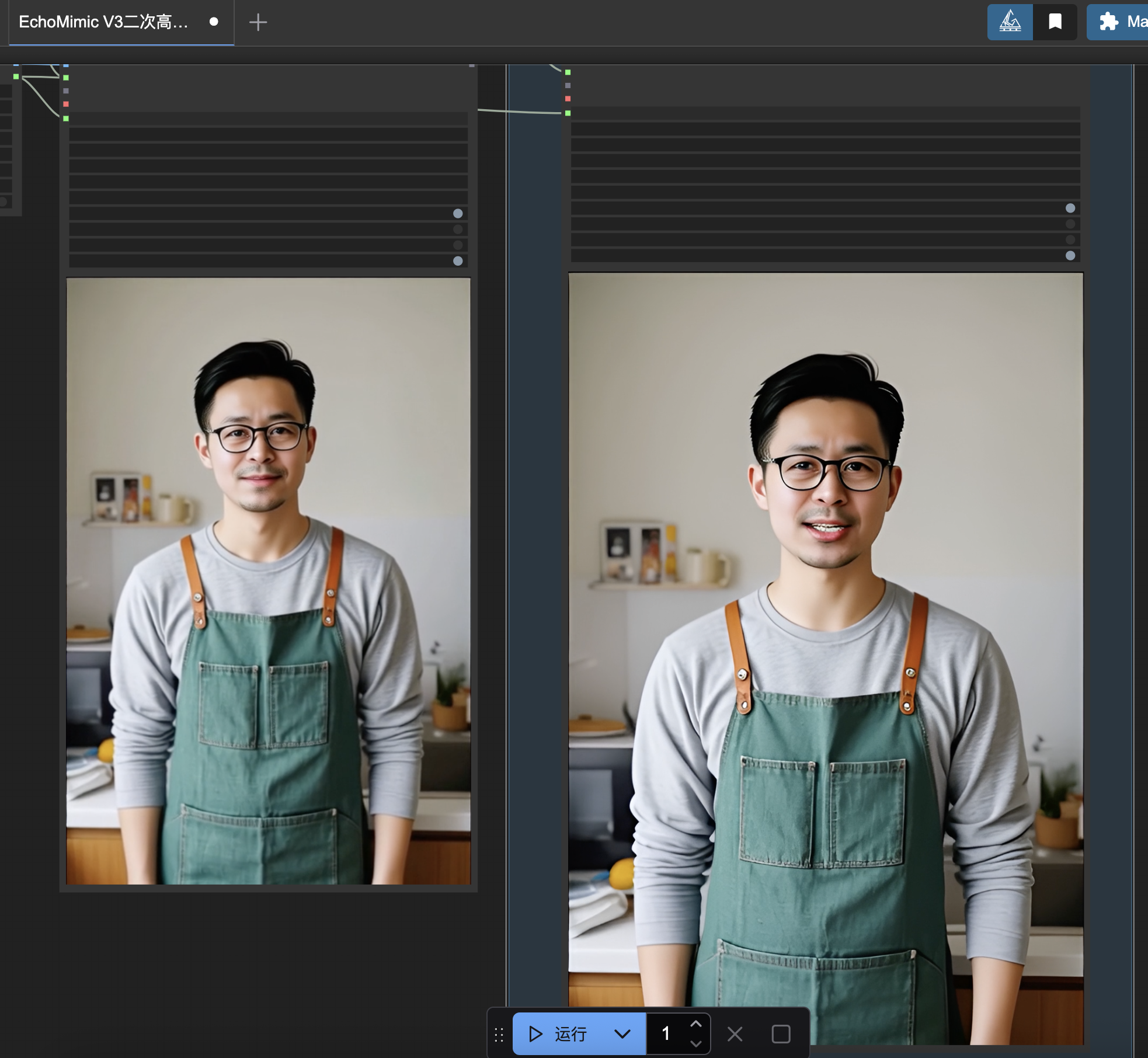
运行使用界面截图
优云镜像使用操作一般流程:
1、在社区镜像区域,选择镜像:
2、在打开的新页面 点击“使用该镜像创建实例”:
3、选择一个合适的显卡【GPU】根据情况选择:
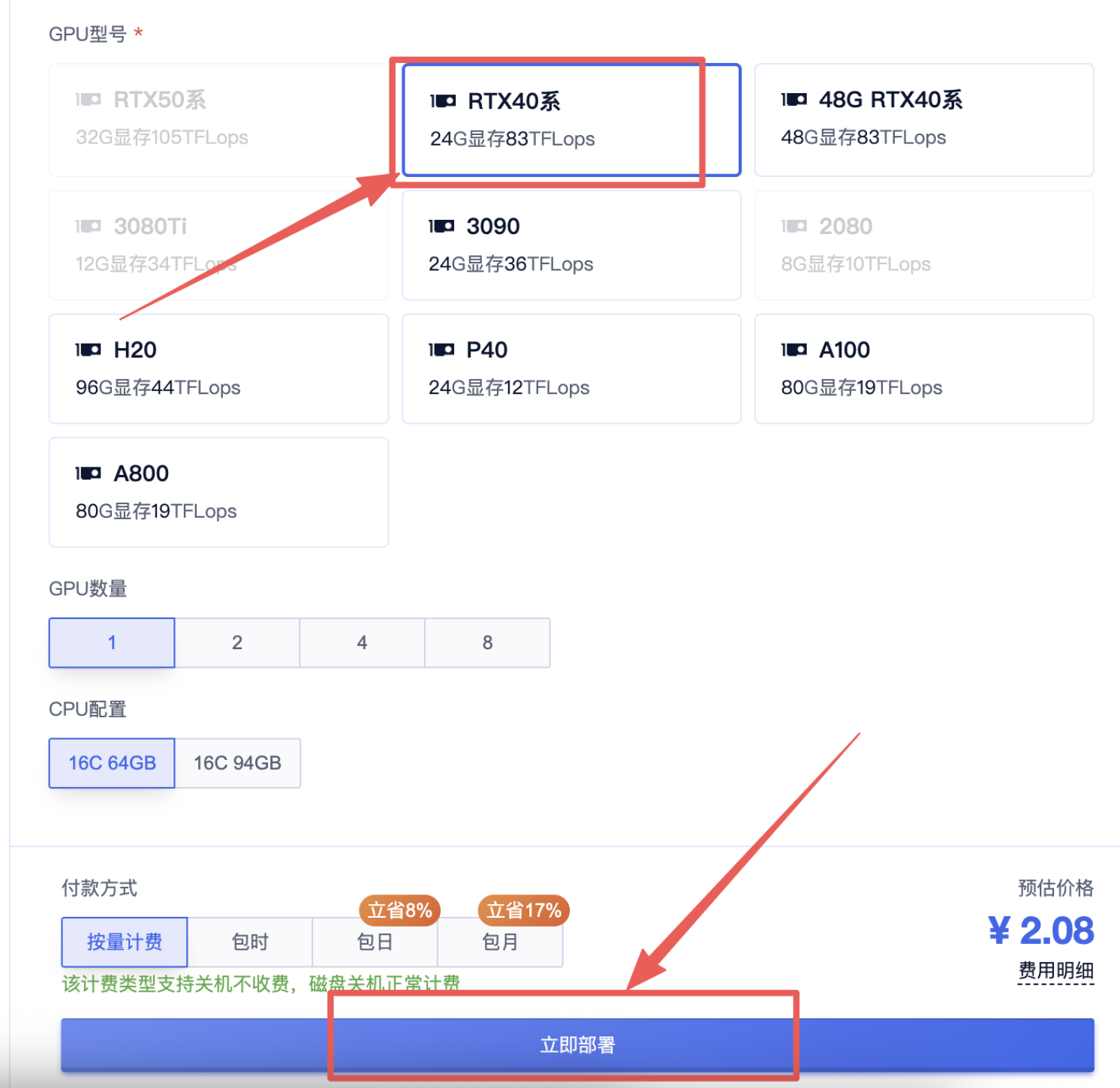
4、确认部署信息无误,点击“开始部署”,然后等待部署完成:
如何启动应用
不是自动运行的应用:
1、手动点击加号新建起始页:
2、打开终端:
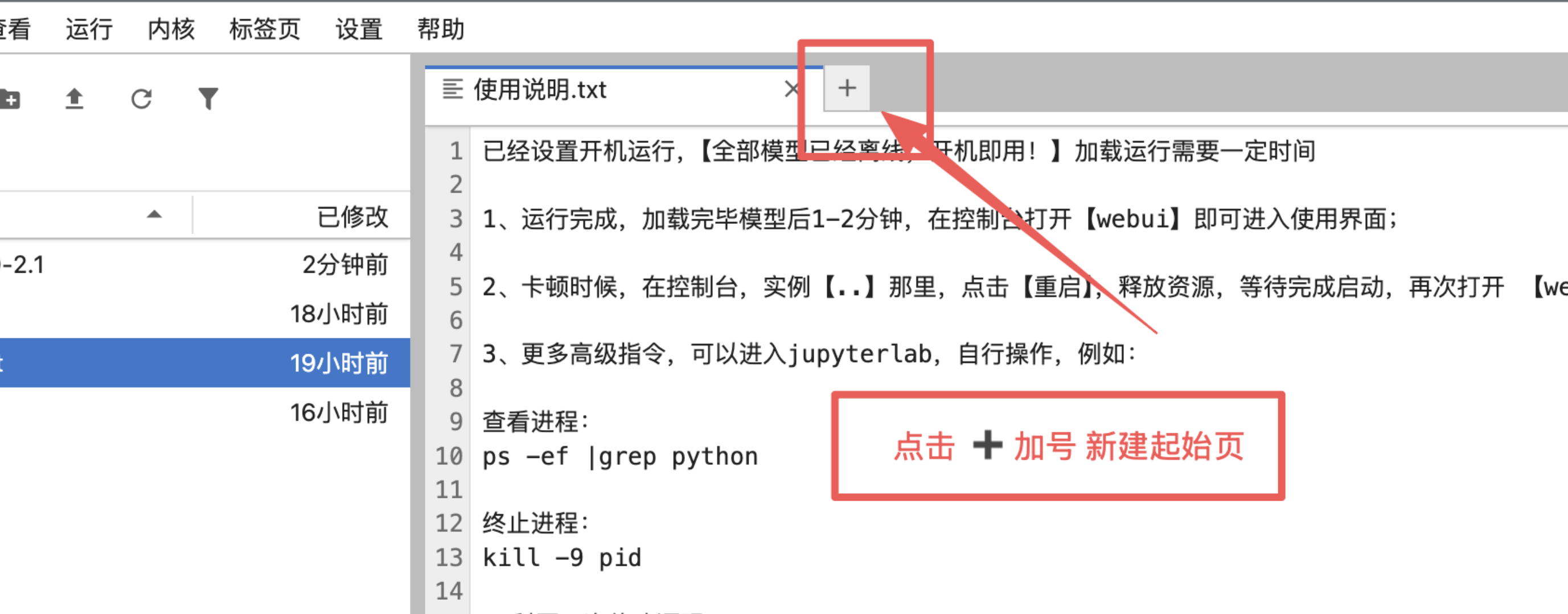
3、输入指令然后回车:
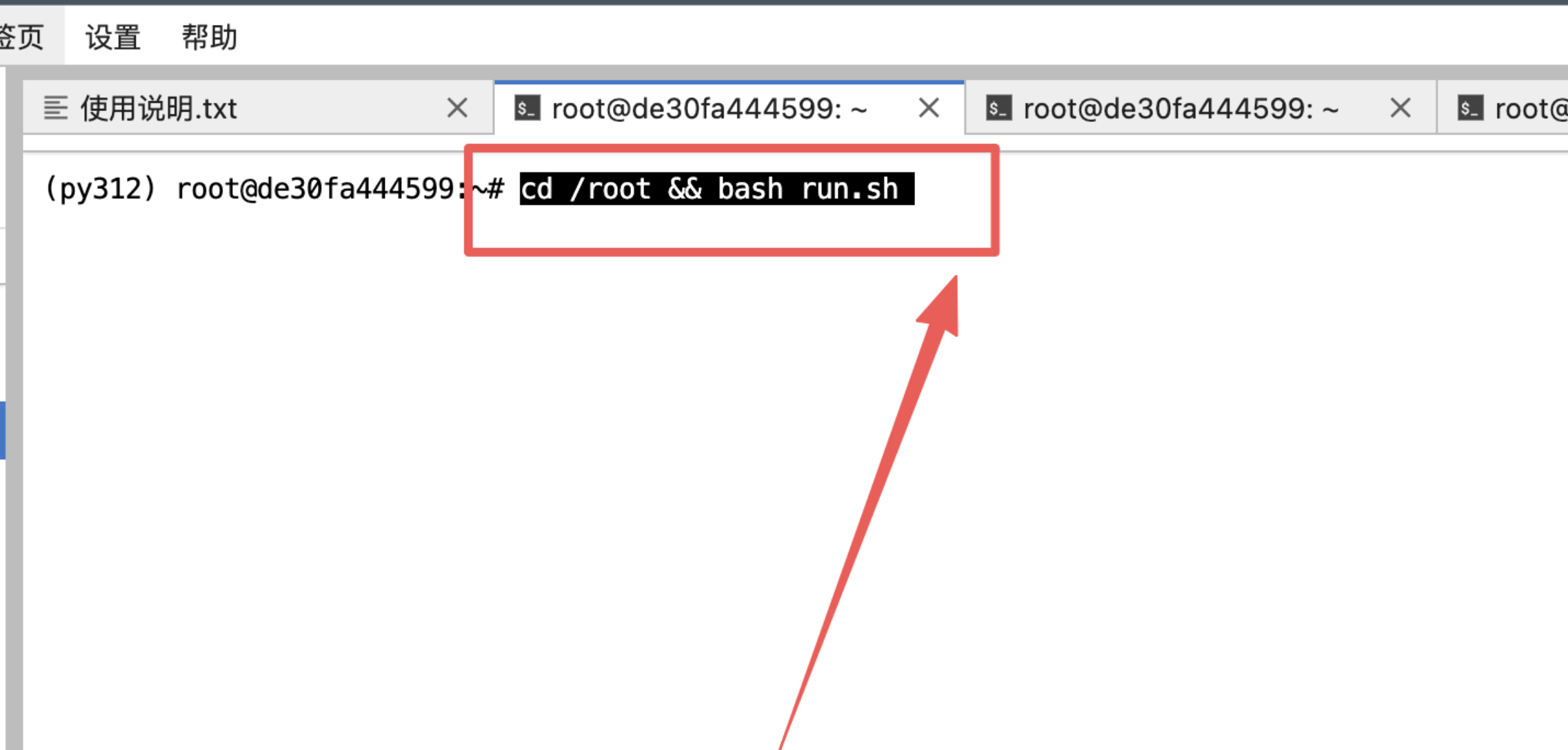
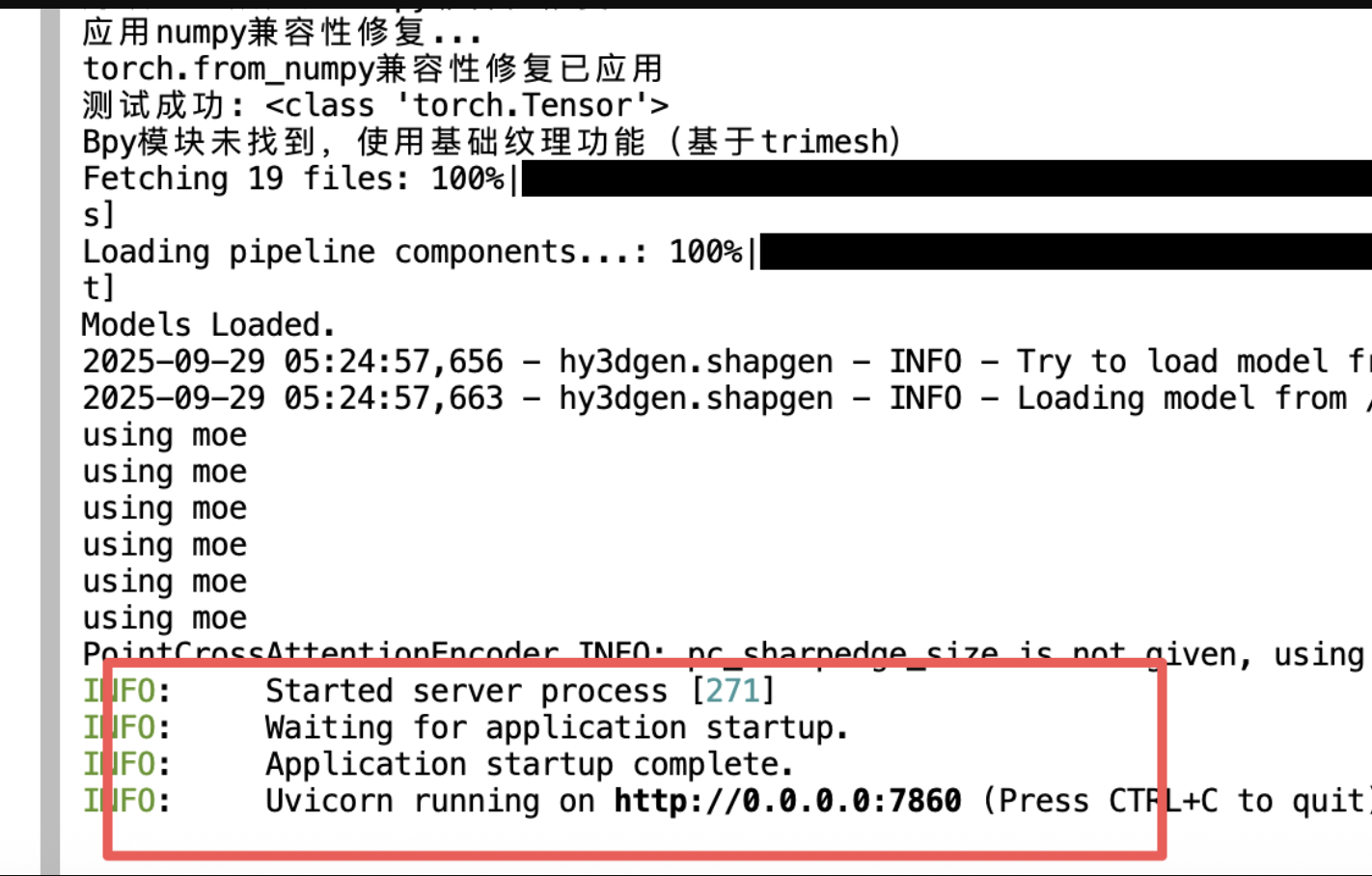
4、等待加载模型完毕:
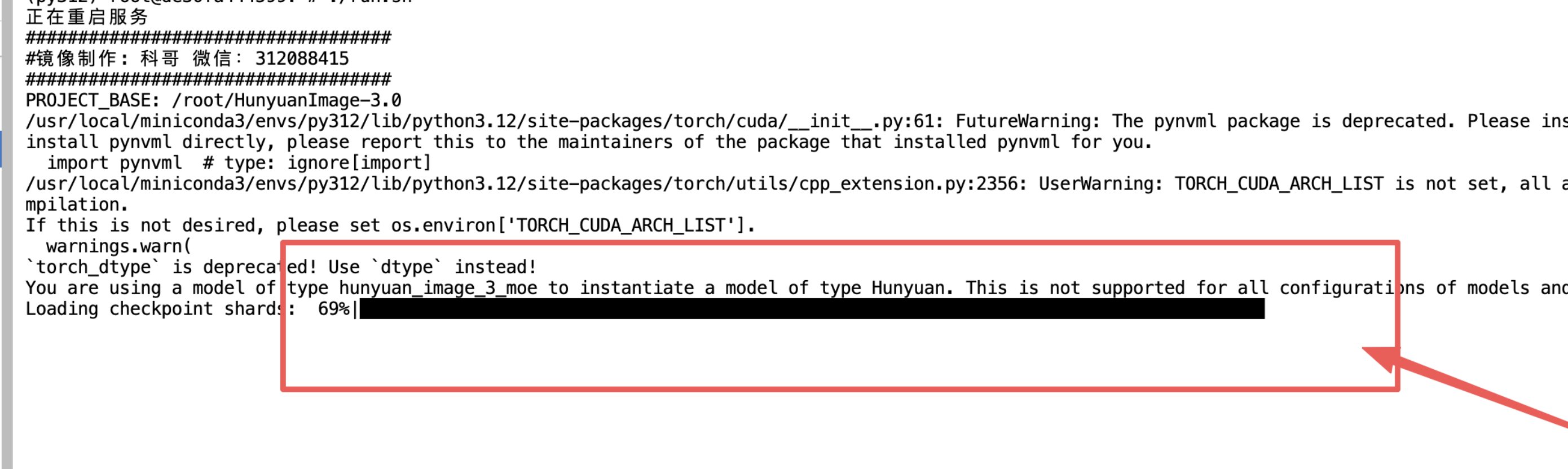
5、看到这个出现:
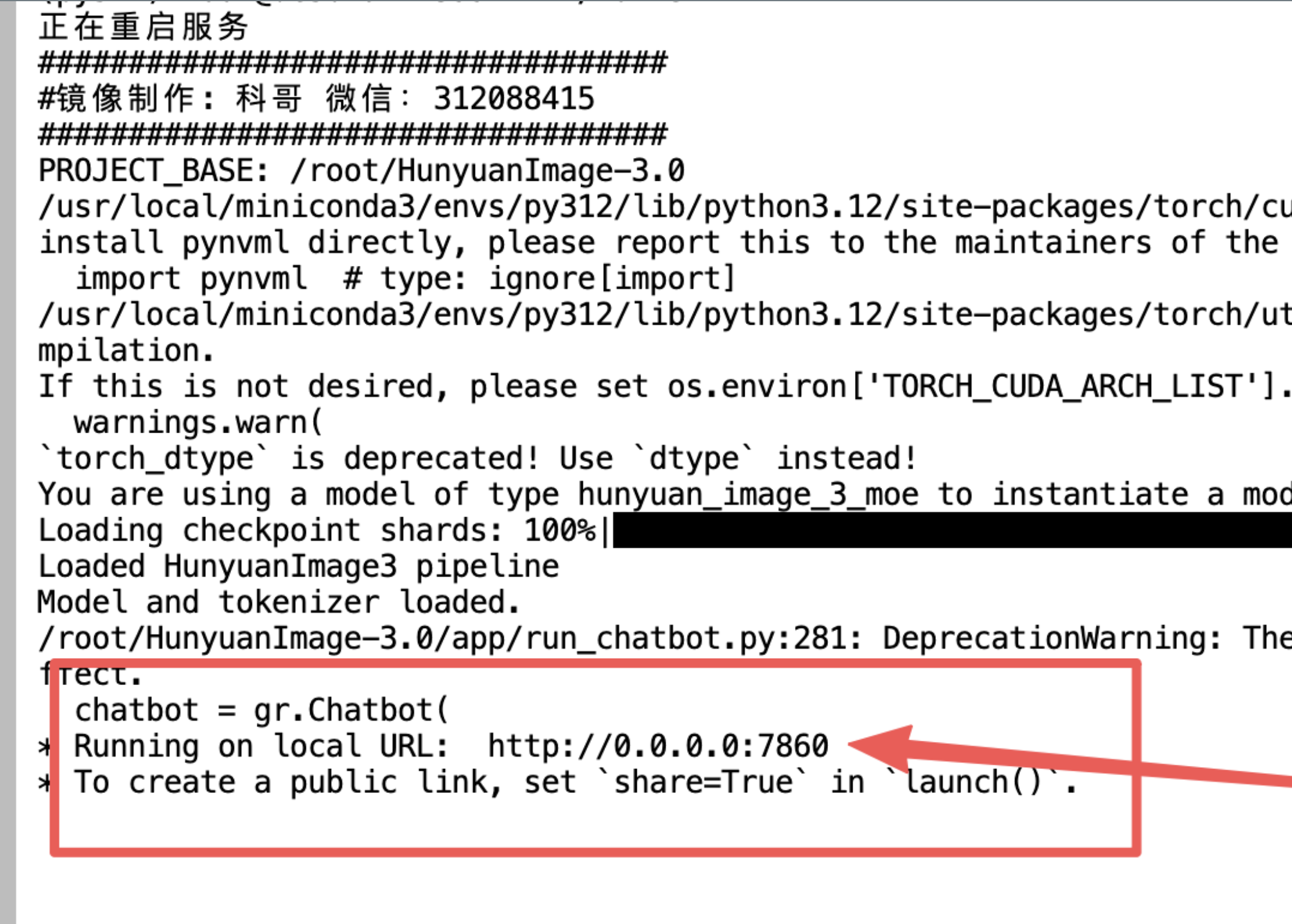
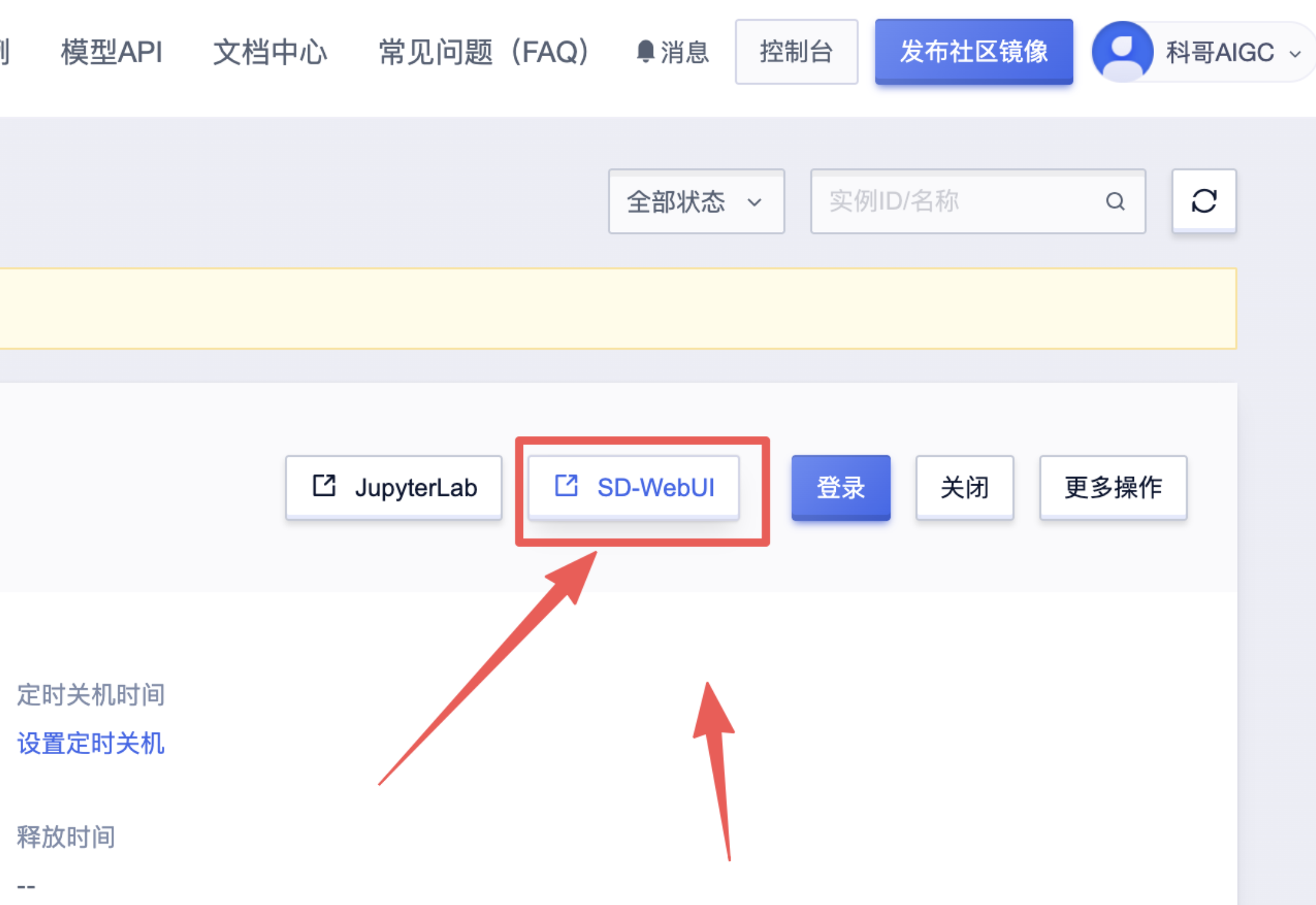
6、返回控制面板打开“SD-WebUI”
- AI数字人直播卖货欢迎来了解: https://kege-aigc.feishu.cn/docx/G271dgZr1o8CvMx9KKrcRuuonDf
以上都是镜像运行打开操作的一般步骤
优其他使用报错问题加群咨询
更多高级指令,可以进入jupyterlab,自行操作,例如:
- 查看进程:
ps -ef |grep python
- 终止进程:
kill -9 pid
- 重启程序:
cd /root && bash run.sh
- 官方更新源码在这里:
- https://github.com/antgroup/echomimic_v3
有bug请微信科哥或加群: 312088415
bug反馈可以加入科哥专属群交流➕ 广告勿进!

科哥在UCloud镜像列表【不断更新中】:
@鸡你太美 认证作者
认证作者
认证作者
镜像信息
已使用32 次
运行时长
39 H
镜像大小
60GB
最后更新时间
2026-04-27
支持卡型
RTX40系48G RTX40系30903080TiA800H20P40A100V100S
+9
框架版本
CUDA版本
12.8
应用
JupyterLab: 8888
版本
v3.1
2026-04-27
v3.0
2026-04-27