Qwen3-vl-abliterated视觉模型,视频理解,多图理解,批量任务,反推提示词
Qwen3-vl-abliterated视觉模型,视频理解,多图理解,批量任务,反推提示词
 34
340元/小时
v1.0
Qwen3-vl-abliterated视觉模型
镜像简介
本镜像搭载Qwen3-vl-abliterate先进视觉语言模型,专精于视频与多图像的内容深度理解,并支持批量任务处理。核心功能包括从视觉素材中智能反推生成高质量描述性提示词,大幅简化创作与分析流程。适用于视频内容分析、图文素材库整理、AI训练数据预处理及跨模态内容理解等场景,为用户提供强大的智能视觉解析工具。
功能支持
- 视频理解、多图理解
- 批量任务
- 反推提示词
使用教程
1、该镜像支持自启动,初始化后,需要等待程序编译启动,大概4分钟左右
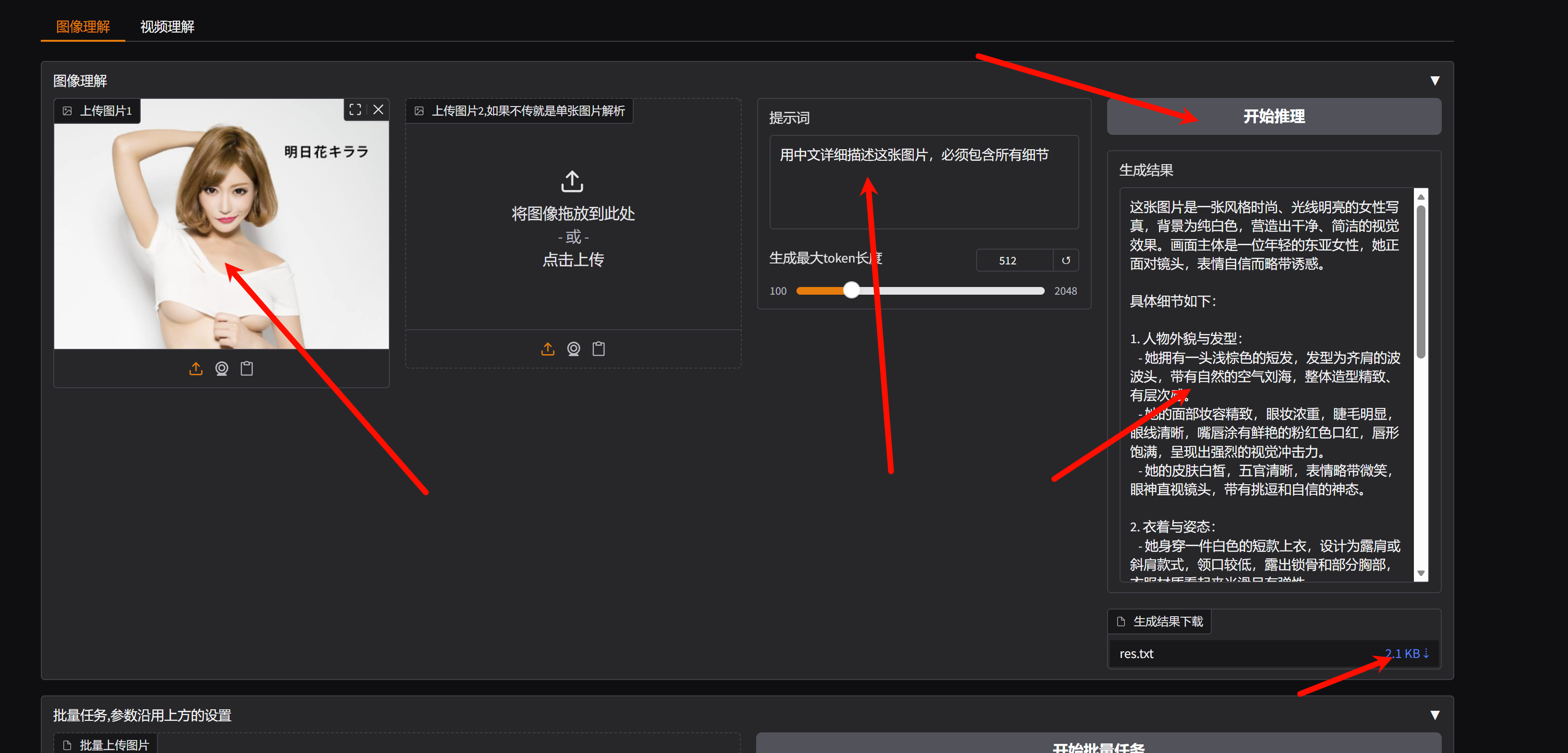
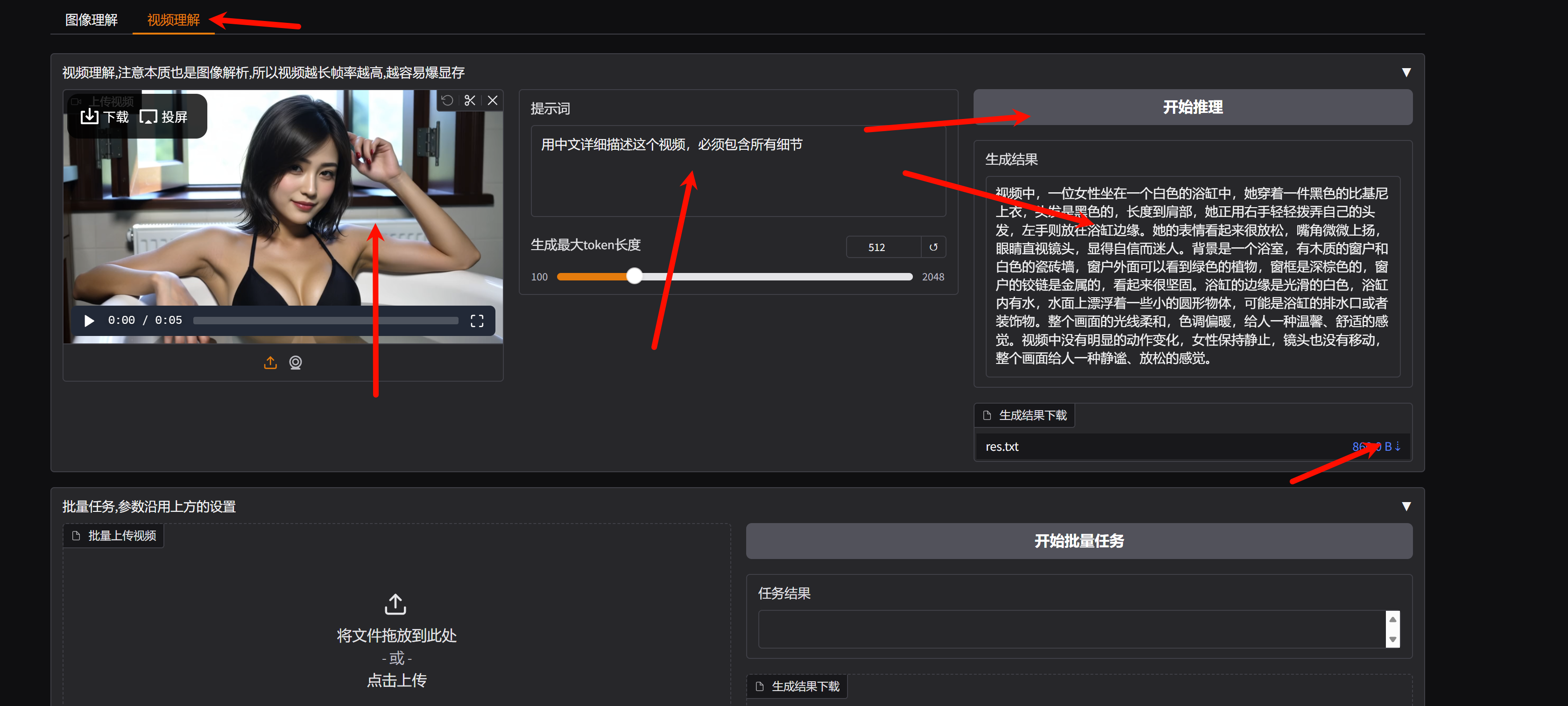
2、随后点击SD-WEBUI按钮,上传图片或者视频,输入提示词,点击生成按钮即可
刘悦的镜像交流官方社群

@刘悦的技术博客 认证作者
认证作者
认证作者
镜像信息
已使用168 次
运行时长
1144 H
 支持自启动
支持自启动镜像大小
90GB
最后更新时间
2026-01-30
支持卡型
RTX40系RTX50系48G RTX40系3080Ti3090
+5
框架版本
CUDA版本
12.8
应用
JupyterLab: 8888
版本
v1.0
2026-01-30