ChatterBox多语言语音合成语言克隆声音克隆 webui二次开发构建by科哥
支持23个国家的语言声音克隆
 4
40元/小时
v1.1
ChatterBox多语言语音合成语言克隆声音克隆 webui二次开发构建by科哥
镜像简介
本镜像集成ChatterBox多语言语音合成与克隆系统,支持23种国家语言的语音生成与高拟真音色复刻。通过优化的WebUI界面,用户可便捷地进行跨语言语音合成、个性化声音克隆及多语种内容制作,适用于虚拟人配音、全球化有声内容、教育辅助及智能客服等场景,提供高质量、易操作的语音AI解决方案。
镜像使用指南
1、在社区镜像区域,选择镜像:
2、在打开的新页面 点击“使用该镜像创建实例”:
2、在打开的新页面 点击“使用该镜像创建实例”:
3、选择一个合适的显卡【GPU】根据情况选择,点击“开始部署”,然后等待部署完成:
3、选择一个合适的显卡【GPU】根据情况选择,点击“开始部署”,然后等待部署完成:
4、实例运行后打开webui即可
运行页面预览
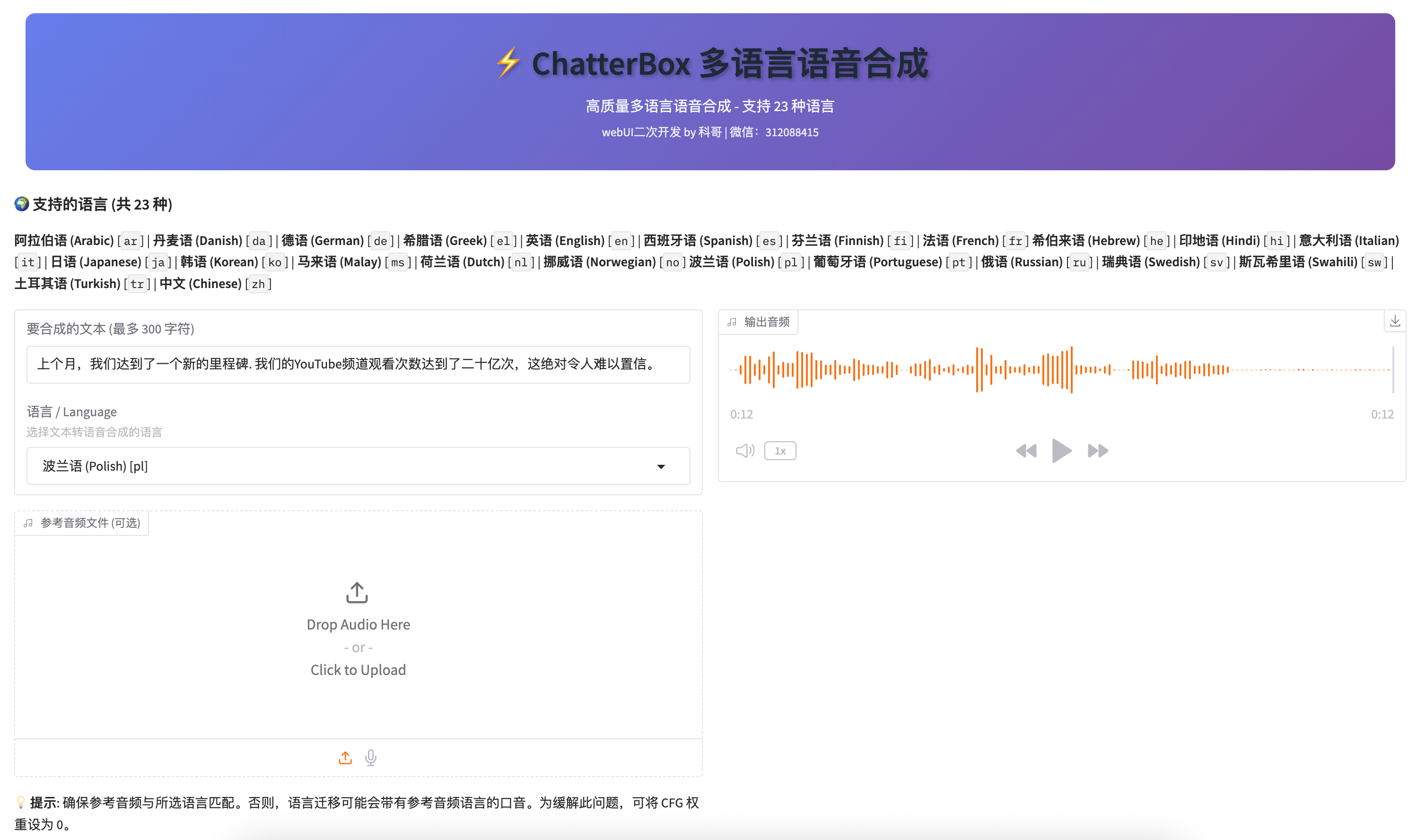
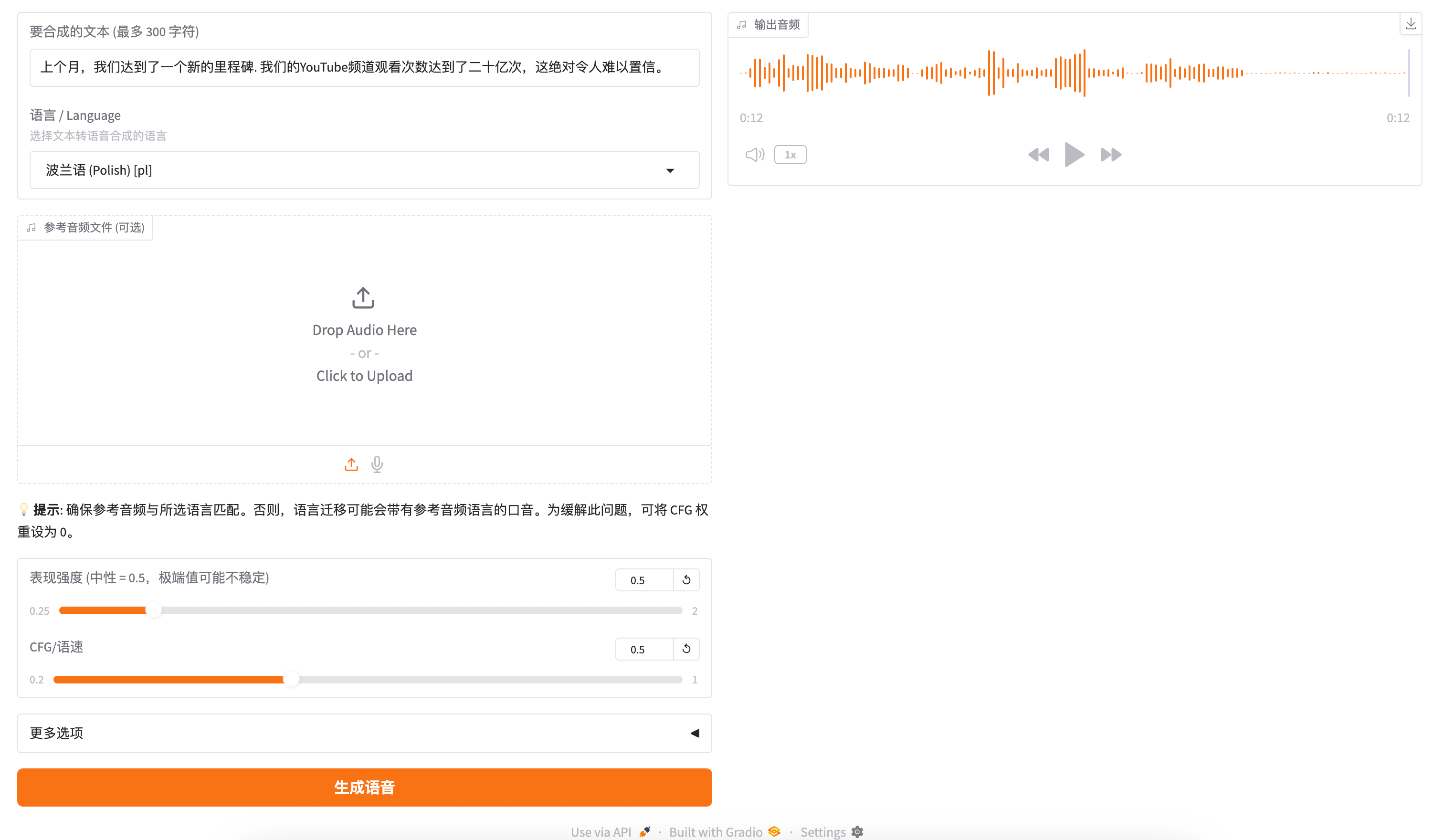
ChatterBox 多语言语音合成 - 用户使用手册
webUI 二次开发 by 科哥 | 微信:312088415
界面介绍
打开浏览器访问 http://服务器IP:7860,您将看到简洁的中文操作界面。
主要区域
┌─────────────────────────────────────────────────────────┐
│ ⚡ ChatterBox 多语言语音合成 │
│ 高质量多语言语音合成 - 支持 23 种语言 │
│ webUI二次开发 by 科哥 | 微信:312088415 │
├─────────────────────────────────────────────────────────┤
│ ┌─────────────┐ ┌─────────────────────────────────┐ │
│ │ 输入区域 │ │ 输出区域 │ │
│ │ │ │ │ │
│ │ 文本框 │ │ 音频播放器 │ │
│ │ 语言选择 │ │ │ │
│ │ 参考音频 │ │ │ │
│ │ 参数调节 │ │ │ │
│ │ │ │ │ │
│ │ [生成语音] │ │ │ │
│ └─────────────┘ └─────────────────────────────────┘ │
└─────────────────────────────────────────────────────────┘
基本使用流程
第一步:输入文本
在 "要合成的文本" 输入框中,输入您想要转换为语音的文字。
- 最多支持 300 字符
- 支持中英文混合输入
示例:
你好,欢迎使用 ChatterBox 语音合成系统。
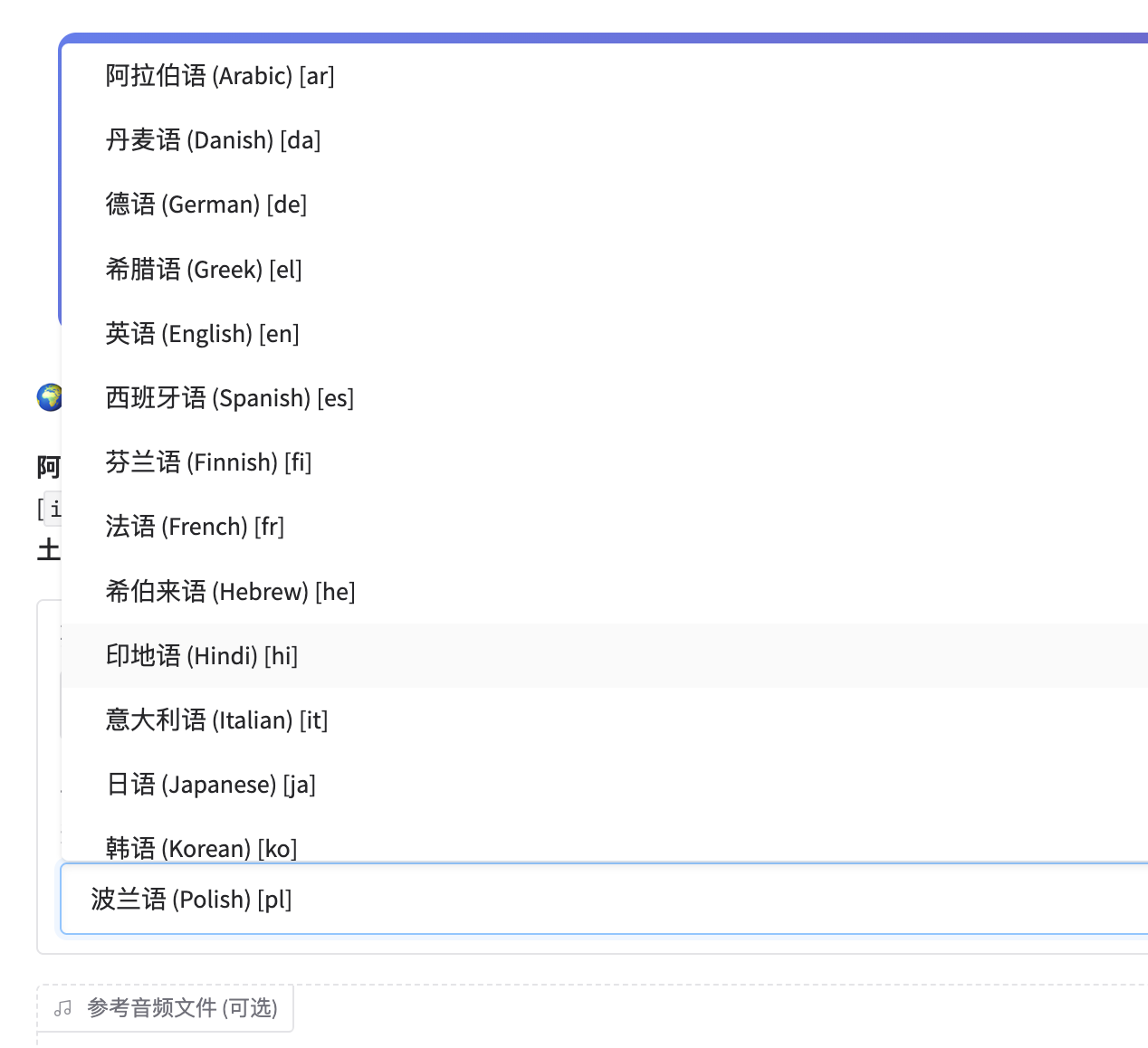
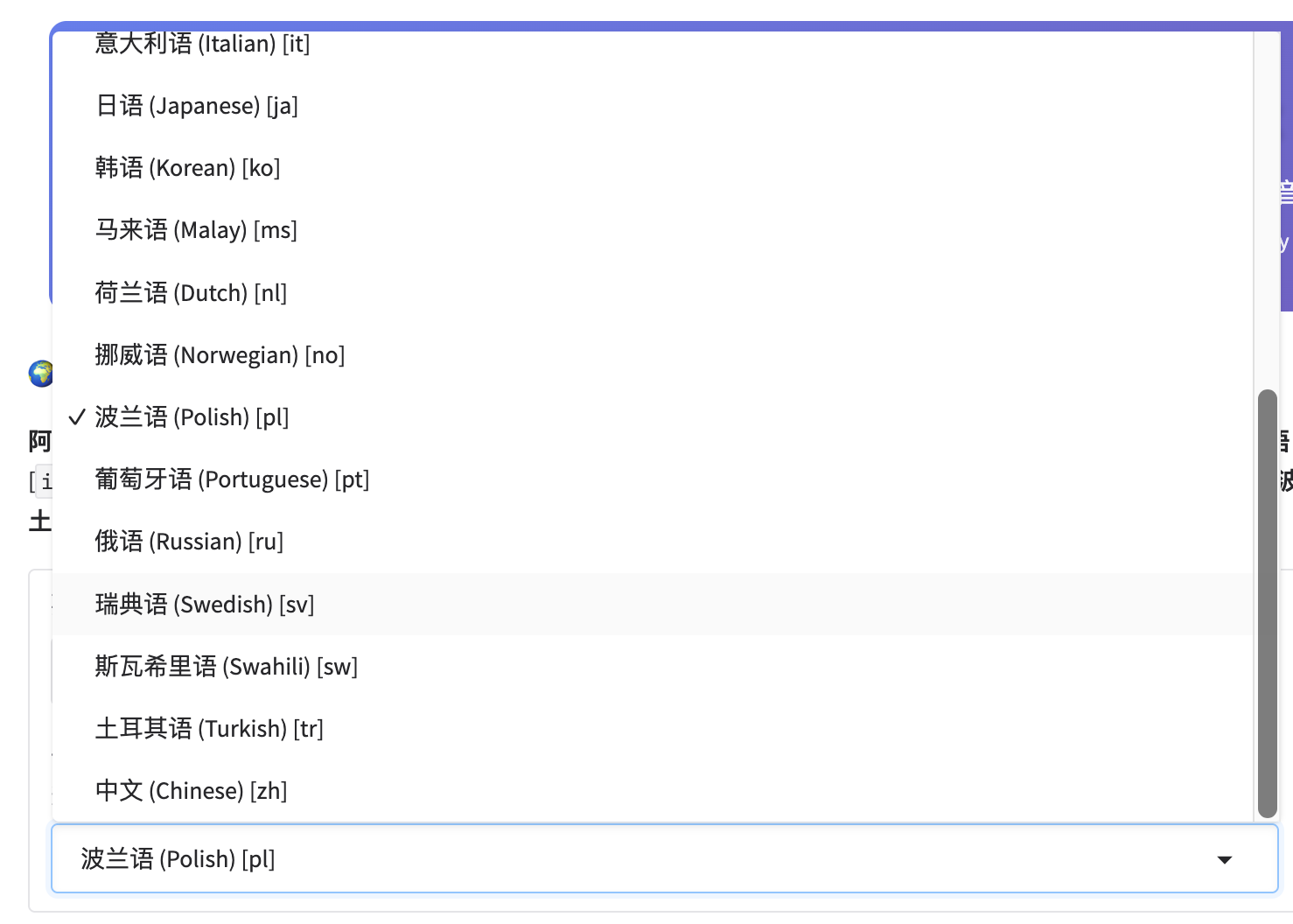
第二步:选择语言
点击 "语言" 下拉框,选择文本对应的语言。
显示格式:中文名称 (英文名称) [代码]
支持的语言(23种):
| 语言 | 代码 | 语言 | 代码 |
|---|---|---|---|
| 中文 | zh | 西班牙语 | es |
| 英语 | en | 法语 | fr |
| 阿拉伯语 | ar | 德语 | de |
| 丹麦语 | da | 希腊语 | el |
| 芬兰语 | fi | 希伯来语 | he |
| 印地语 | hi | 意大利语 | it |
| 日语 | ja | 韩语 | ko |
| 马来语 | ms | 荷兰语 | nl |
| 挪威语 | no | 波兰语 | pl |
| 葡萄牙语 | pt | 俄语 | ru |
| 瑞典语 | sv | 斯瓦希里语 | sw |
| 土耳其语 | tr |
💡 提示: 确保语言选择与文本语言一致,否则发音可能不准确。
第三步:(可选)上传参考音频
如果希望生成的语音具有特定人的声音特征,可以上传参考音频。
- 来源: 上传文件 或 麦克风录制
- 要求: 音频时长需超过 5 秒
- 格式: 支持常见音频格式(wav, mp3, flac 等)
💡 提示: 参考音频的语言应与所选语言匹配,否则可能带有口音。
第四步:(可选)调整参数
表现强度
- 范围: 0.25 ~ 2.0
- 默认: 0.5(中性)
- 说明: 控制语音的表现力
- 低于 0.5:更平缓
- 高于 0.5:更夸张
- 极端值可能导致不稳定
CFG/语速
- 范围: 0.2 ~ 1.0
- 默认: 0.5
- 说明: 控制生成节奏
- 值越大,语速越快
- 设为 0 可进行语言迁移
高级选项(点击展开)
| 参数 | 范围 | 默认值 | 说明 |
|---|---|---|---|
| 随机种子 | 0-任意 | 0 | 0=随机生成,其他值=可复现结果 |
| 温度 | 0.05-5.0 | 0.8 | 控制随机性,越高变化越大 |
第五步:生成语音
点击 "生成语音" 按钮,等待处理完成。
- 处理时间:约 5-15 秒(取决于文本长度)
- 完成后右侧会显示音频播放器
输出文件
生成的音频会自动保存到项目的 outputs 目录。
文件名格式: 语言代码_时间戳.wav
示例:
zh_20241230143025.wav # 中文语音
en_20241230143030.wav # 英语语音
es_20241230143035.wav # 西班牙语语音
使用技巧
1. 获得更好的发音效果
- 使用标点符号帮助断句:
你好,欢迎使用。 - 避免过长句子,建议分段生成
- 选择正确的语言代码
2. 自定义声音克隆
- 上传清晰的参考音频(5秒以上)
- 确保参考音频与目标语言一致
- 调整表现强度参数控制相似度
3. 生成可复现的结果
在 "更多选项" 中设置固定的随机种子值,使用相同参数可生成完全相同的音频。
4. 语言迁移
将 CFG/语速 设为 0,可以实现跨语言的语音特征迁移。
常见问题
Q: 生成的语音有杂音怎么办?
A: 尝试:
- 降低温度参数(如 0.5-0.7)
- 检查参考音频质量
- 使用更短的文本
Q: 发音不准确?
A: 确认:
- 语言选择是否与文本一致
- 文本是否包含特殊字符
- 尝试简化文本内容
Q: 生成失败?
A: 可能原因:
- 文本超过 300 字符限制
- 参考音频不足 5 秒
- 服务器资源不足,稍后重试
Q: 如何下载生成的音频?
A: 音频会自动保存到服务器 outputs 目录,也可以在播放器中直接下载。
参数推荐值
| 场景 | 表现强度 | CFG/语速 | 温度 |
|---|---|---|---|
| 日常使用 | 0.5 | 0.5 | 0.8 |
| 有声书 | 0.6-0.8 | 0.4 | 0.7 |
| 新闻播报 | 0.3-0.4 | 0.6 | 0.6 |
| 情感朗读 | 0.8-1.2 | 0.5 | 0.9 |
快捷操作
- 切换语言时: 默认文本和参考音频会自动更新为该语言的示例
- 清空文本: 直接删除输入框内容
- 重新生成: 保持参数不变,再次点击生成按钮
祝您使用愉快!
bug反馈可以加入科哥专属群交流➕ 广告勿进!

科哥在UCloud镜像列表【不断更新中】:
@鸡你太美 认证作者
认证作者
认证作者
镜像信息
已使用34 次
运行时长
31 H
 支持自启动
支持自启动镜像大小
40GB
最后更新时间
2026-04-27
支持卡型
3090RTX50系RTX40系48G RTX40系2080Ti3080Ti2080A800H20P40V100SA100
+12
框架版本
CUDA版本
12.8
应用
JupyterLab: 8888
版本
v1.1
2026-04-27