 1
1镜像名称
LongCat-AudioDiT 剧本创作台(LongCat-AudioDiT WebUI版)
镜像简介
本镜像专为LongCat-AudioDiT模型打造,集成可视化WebUI界面,无需复杂部署即可实现语音克隆、多角色剧本音频生成、长文本自动切分等功能,适配本地部署,开源免费且易用性强。
-
功能: 这个镜像主要用于AI语音克隆、多角色对话音频合成、长文本语音生成,支持音色库管理、剧本队列编排,可快速实现方言及多角色语音生成,适配小白用户及二次开发。
-
特点: 预装LongCat-AudioDiT(1B/3.5B)模型、Whisper转写模型及WebUI全部依赖,模块化架构配中文注释,本地部署后可直接使用,支持显存优化,一键启动可视化界面。
环境与依赖
本镜像构建和运行所需的基础环境。
- 框架及版本: (例如:PyTorch 2.0.1)
- CUDA版本: (例如:CUDA 11.8)
- 其他依赖: (例如:Python 3.10, GCC 7.5)
配置方法
方法一
1.创建实例
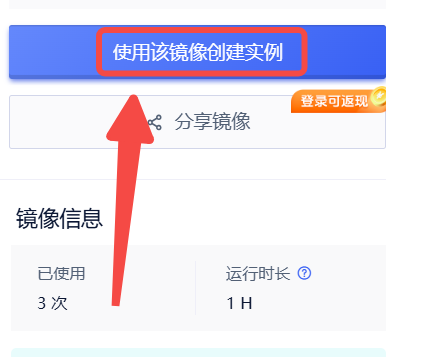 2.选择合适的机型,立即部署
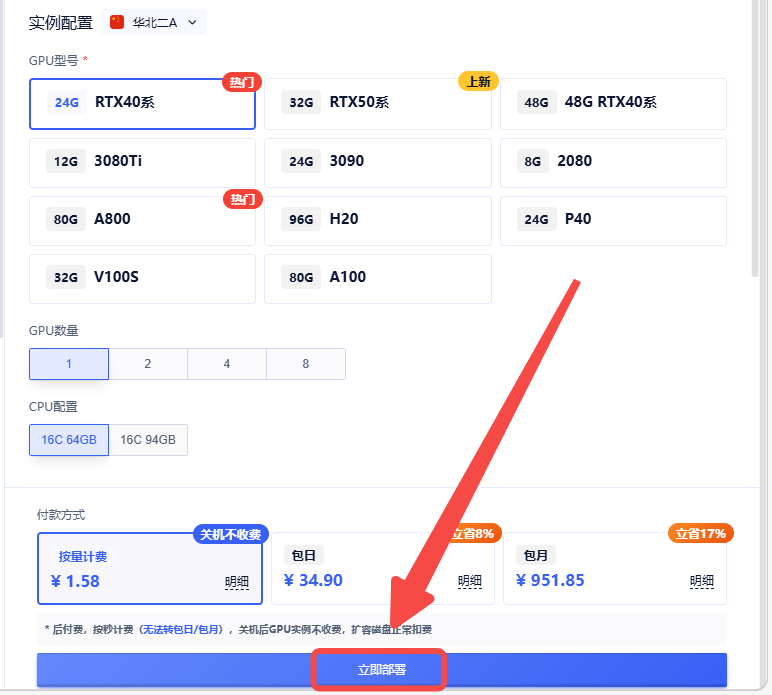
2.选择合适的机型,立即部署
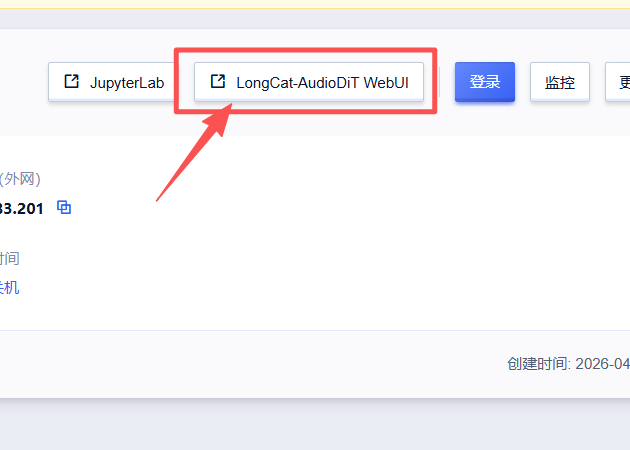
 3.返回实例页面,点击以下按钮,即可进入操作页面
3.返回实例页面,点击以下按钮,即可进入操作页面
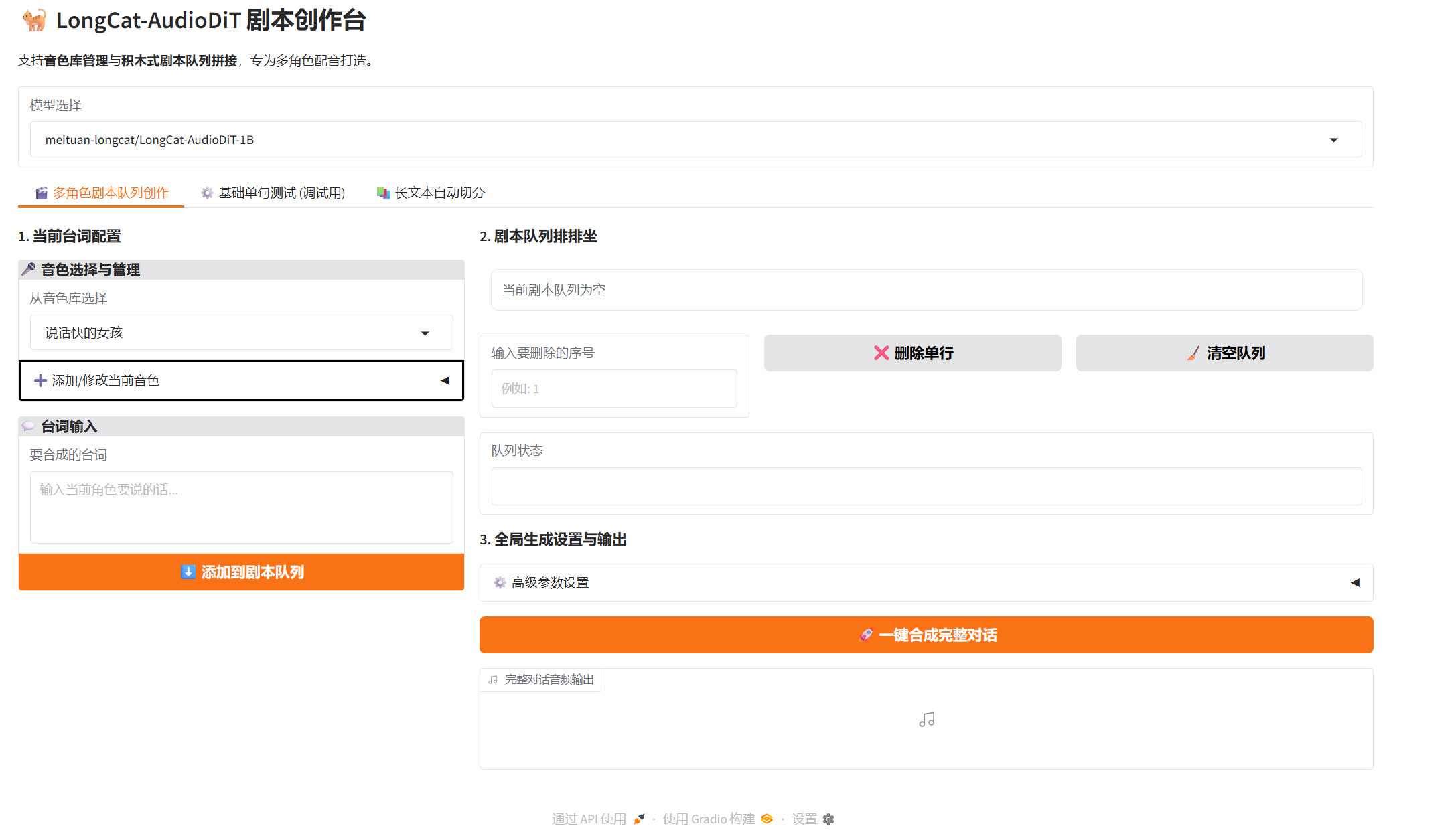
操作界面截图
环境验证代码
提供一段简单的代码或命令,以验证环境是否配置成功。
方法二
启动服务 进入实例终端(Terminal),执行以下命令启动 WebUI: python webui.py
访问界面 等待终端显示 Running on local URL: http://0.0.0.0:7860 后,点击平台提供的 API/Web链接 (或通过公网IP+端口)即可打开操作界面。
常见问题
Q1: 启动WebUI后,无法加载LongCat模型或显存不足怎么办?
A1: 请确认本地NVIDIA显卡显存≥8G,启动容器时添加--gpus all参数;若显存不足,可切换至1B模型,或关闭其他占用显存的程序。
Q2: 上传参考音频后,自动转写功能失效怎么办?
A2:请确保参考音频为.wav格式且时长≤7秒,口音过重时可手动输入参考文本;若仍失效,可重启容器重新加载Whisper模型。
Q3: 剧本队列合成后,音频无法试听或下载怎么办?
A3: 检查容器端口映射是否正常(确保7860端口未被占用),若仍异常,可重新启动容器,或查看容器日志排查错误。
 认证作者
认证作者
 支持自启动
支持自启动