LightOn-OCR-1B,图片和PDF文字提取,图文混排,实时生成MarkDown文档,MarkDown文档下载,支持PDF全量解析
LightOn-OCR-1B,图片和PDF文字提取,图文混排,实时生成MarkDown文档,MarkDown文档下载,支持PDF全量解析
 1
10元/小时
v1.0
LightOn-OCR-1B,图片和PDF文字提取,图文混排,实时生成MarkDown文档,MarkDown文档下载,流式推理,支持PDF全量解析
镜像简介
本镜像搭载高效的1B参数视觉语言模型LightOn-OCR-1B,专注于复杂图片与PDF文档的文字信息提取,可精准处理图文混排版面,并支持实时生成结构清晰的MarkDown文档。结合目标检测与视觉场景识别技术,它能够理解并解析文档的视觉元素与逻辑关系,适用于文档数字化、知识库构建、资料高效归档及自动化内容整理等场景。
镜像使用指南
1、使用该镜像创建实例,该镜像支持自启动,初始化后,需要等待服务启动,大概2分钟左右,可以输入命令 tail -50f /root/wan/log.txt 查看启动日志
 2、随后点击 SD-WEBUI 按钮即可,上传图片或者PDF文档,点击解析按钮即可
2、随后点击 SD-WEBUI 按钮即可,上传图片或者PDF文档,点击解析按钮即可
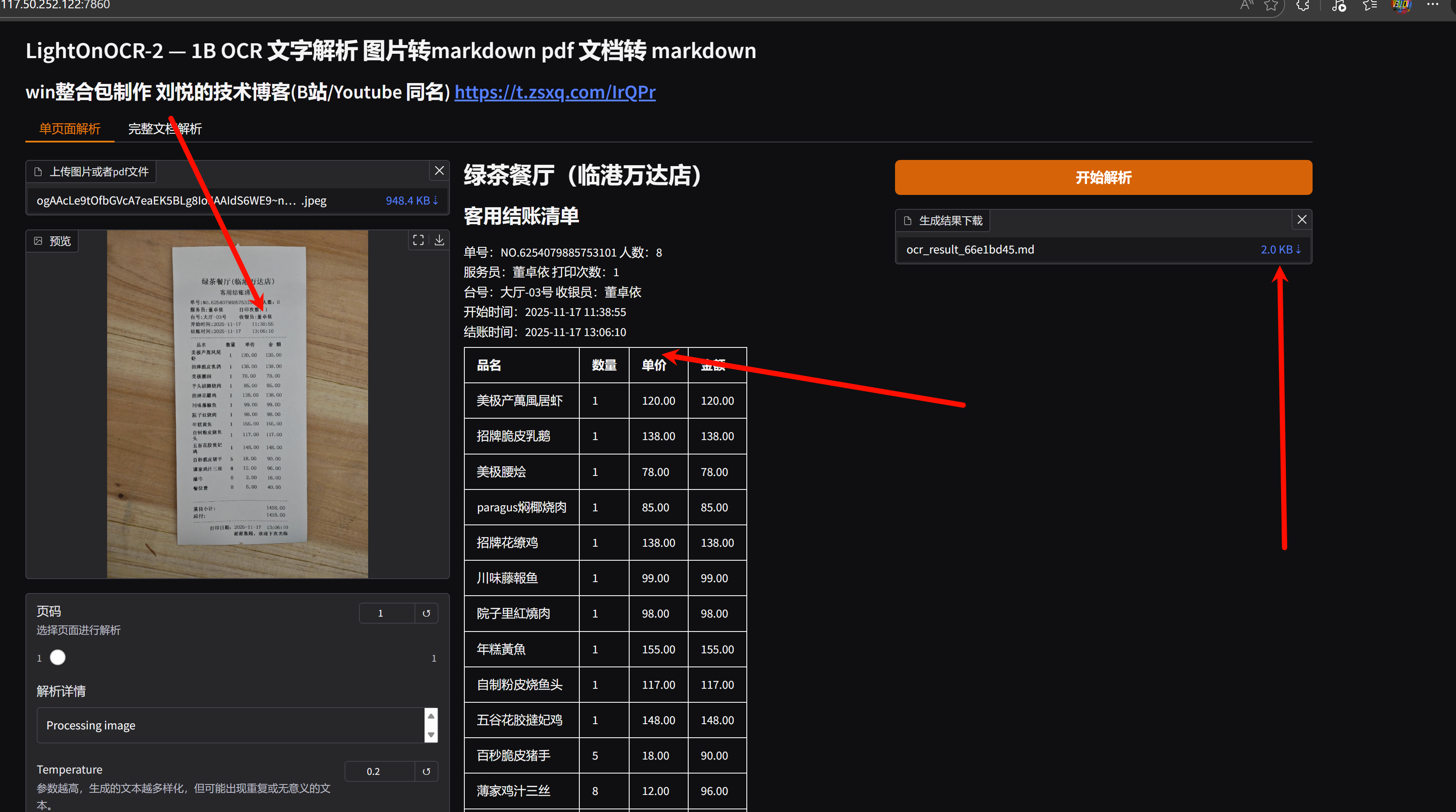
3 也支持全量PDF文档解析,直接下载结果,不限制页数
@刘悦的技术博客 认证作者
认证作者
认证作者

镜像信息
已使用15 次
运行时长
0 H
 支持自启动
支持自启动镜像大小
110GB
最后更新时间
2026-02-02
支持卡型
RTX40系RTX50系48G RTX40系3080Ti2080Ti30902080A800
+8
框架版本
CUDA版本
12.8
应用
JupyterLab: 8888
版本
v1.0
2026-02-02