WAN2.2-S2V最新版数字人+动作参考
阿里开源音+图片+动作参考生成视频模型,Comfyui官方最终优化版工作流
 12
120元/小时
v1.0
Wan2.2-S2V 数字人音+图生视频模型
阿里通义万相开源的一款以音频驱动生成视频的AI模型,它能通过一张图片+音频来生成一段口型同步,表情神态,肢体动作流畅自然的高质量视频,并且支持多种语言.
B站视频教程
镜像使用文档:
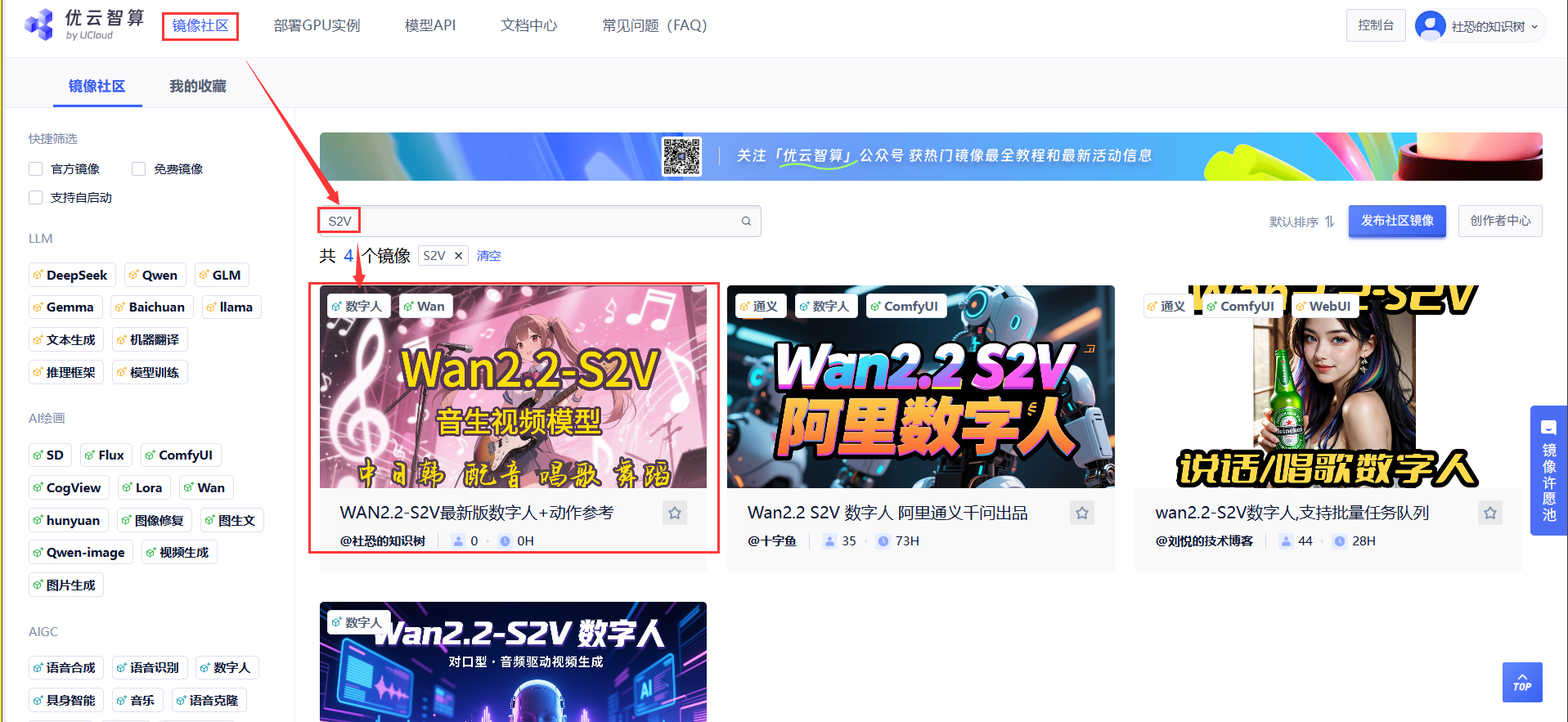
01 查找镜像
点击镜像社区,在搜索框内输入S2V,点击社恐的知识树制作的S2V镜像
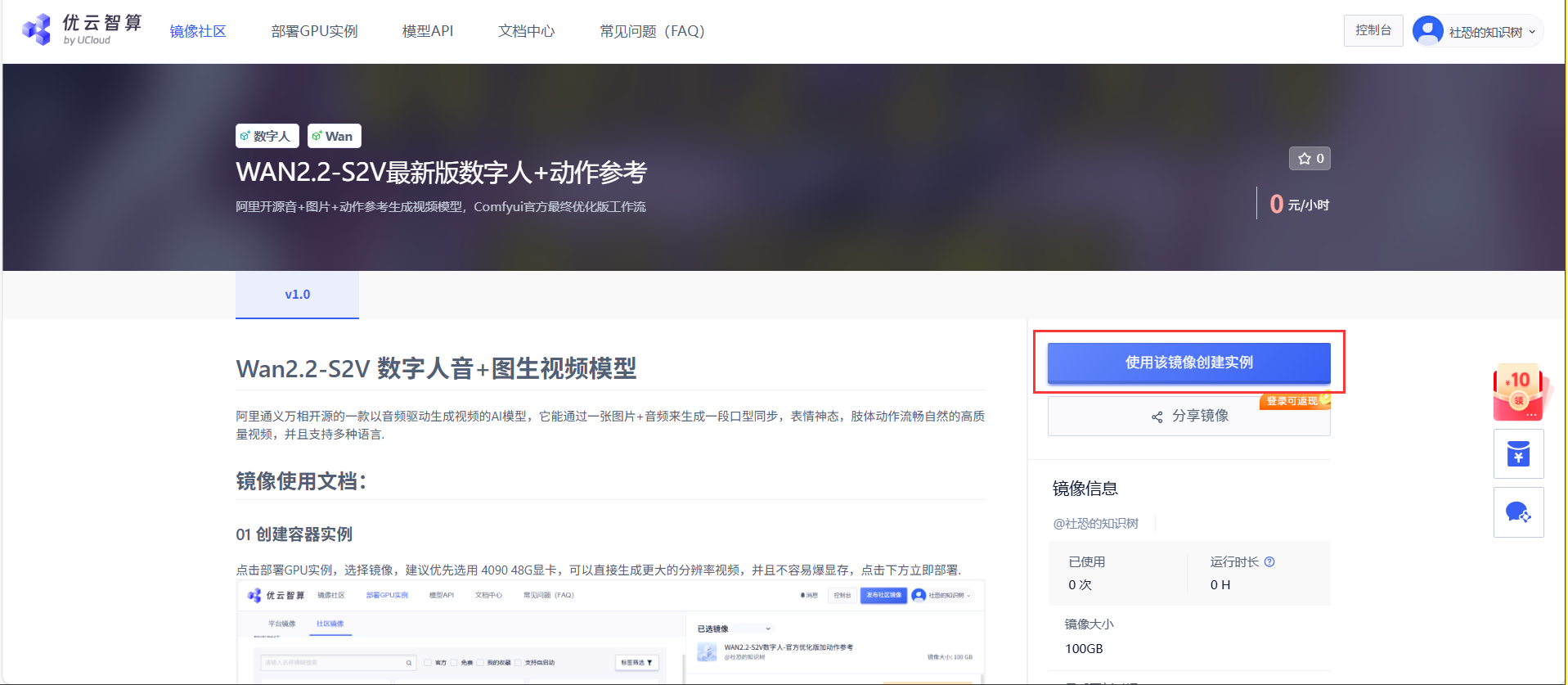
02 部署镜像
点击使用该镜像创建实例
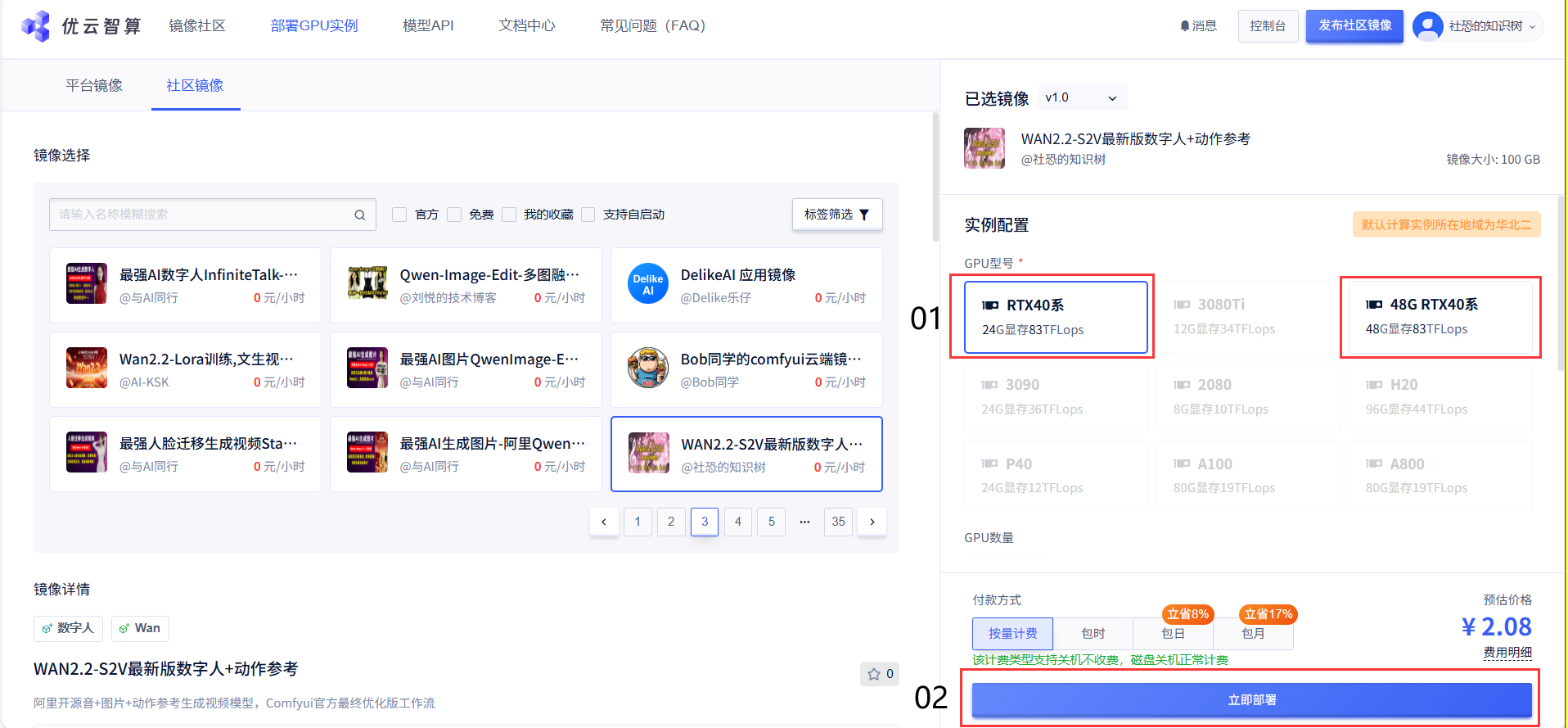
03 创建容器实例
点击部署GPU实例,选择镜像,建议优先选用
4090 48G显卡,可以直接生成更大的分辨率视频,并且不容易爆显存,点击下方立即部署.
04 启动云服务器
立即部署完成后会自动跳转到控制台,选择已部署的镜像实例点击启动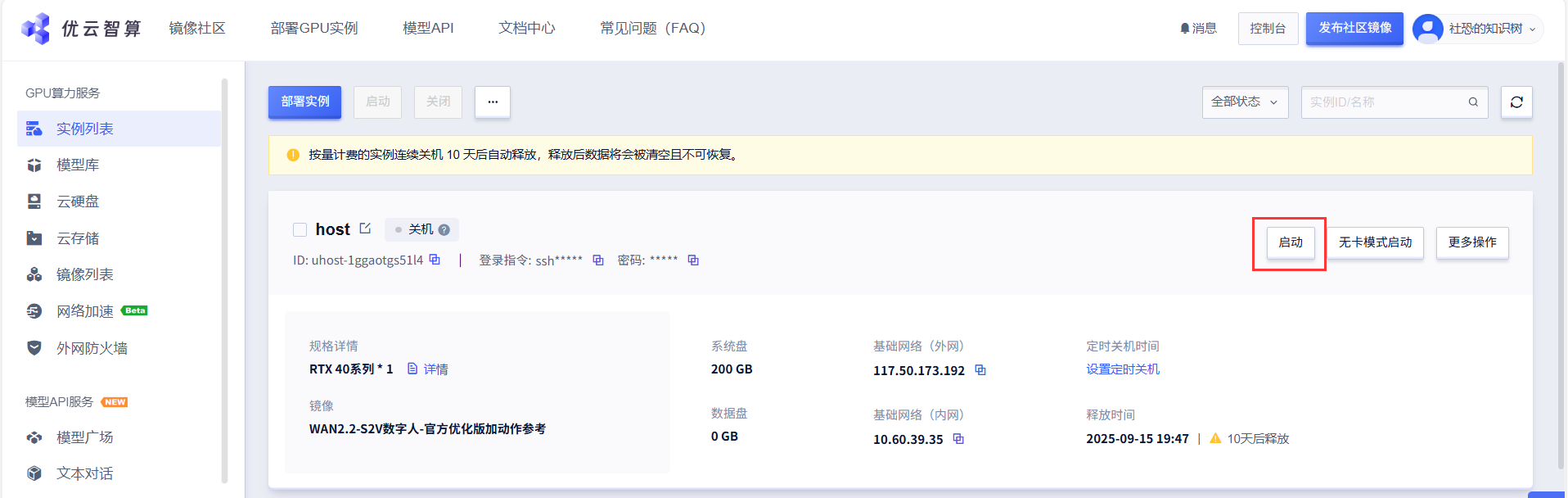
05 运行ComfyUI
启动完成后,点击红色框内"ComfyUI"进入前端操作页面,点击蓝色框内“JupyterLab”进入后台文件夹页面,如果点击ComfyUI没反应,请刷新页面
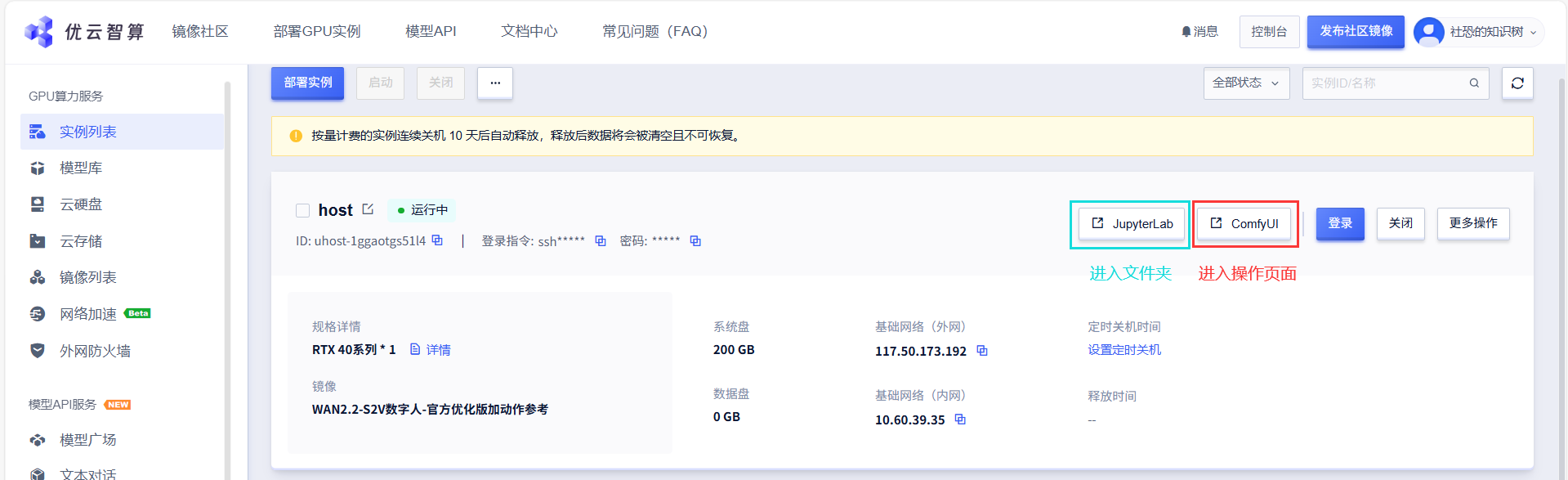
06 查找内置ComfyUI工作流
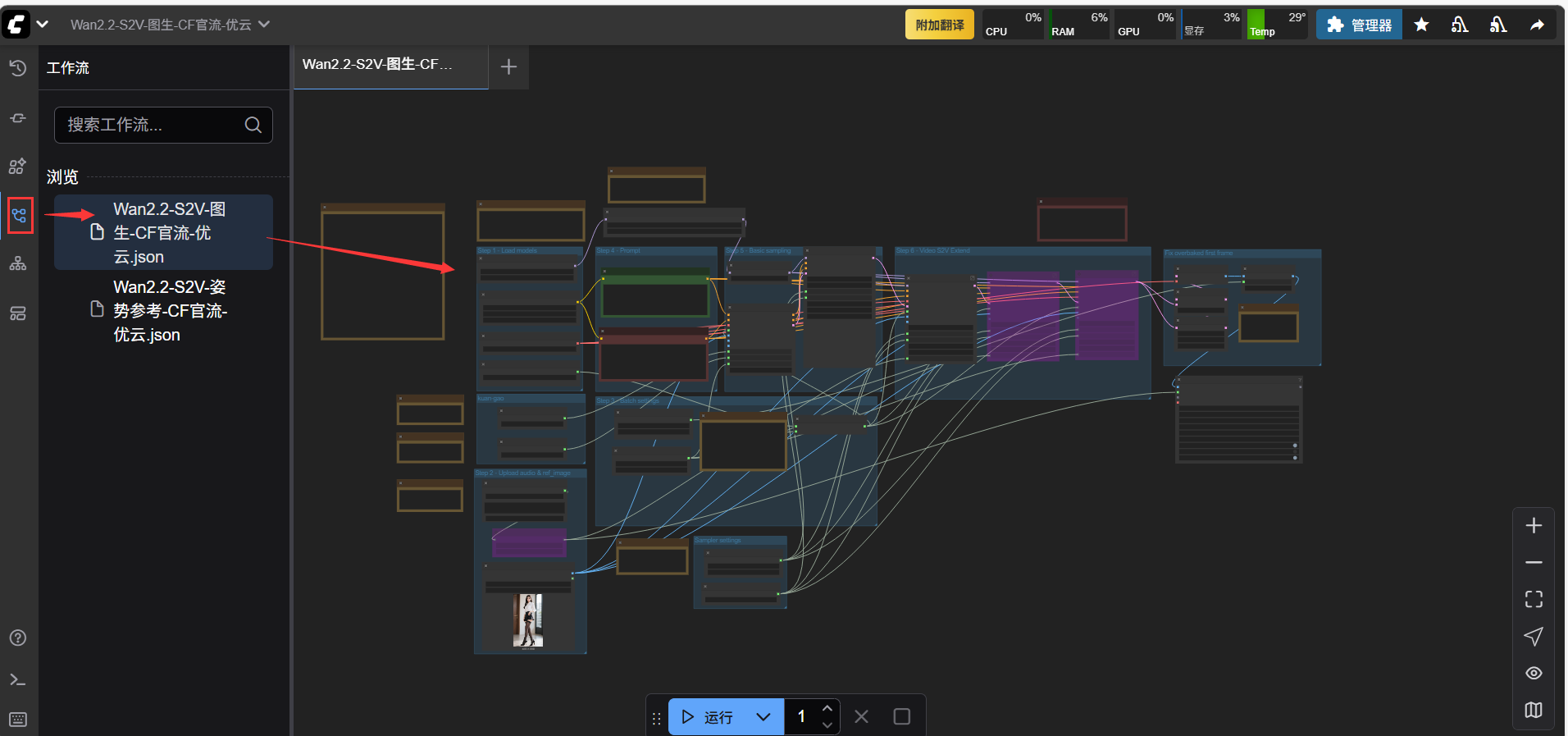
07 如何下载已经生成的文件到本地电脑
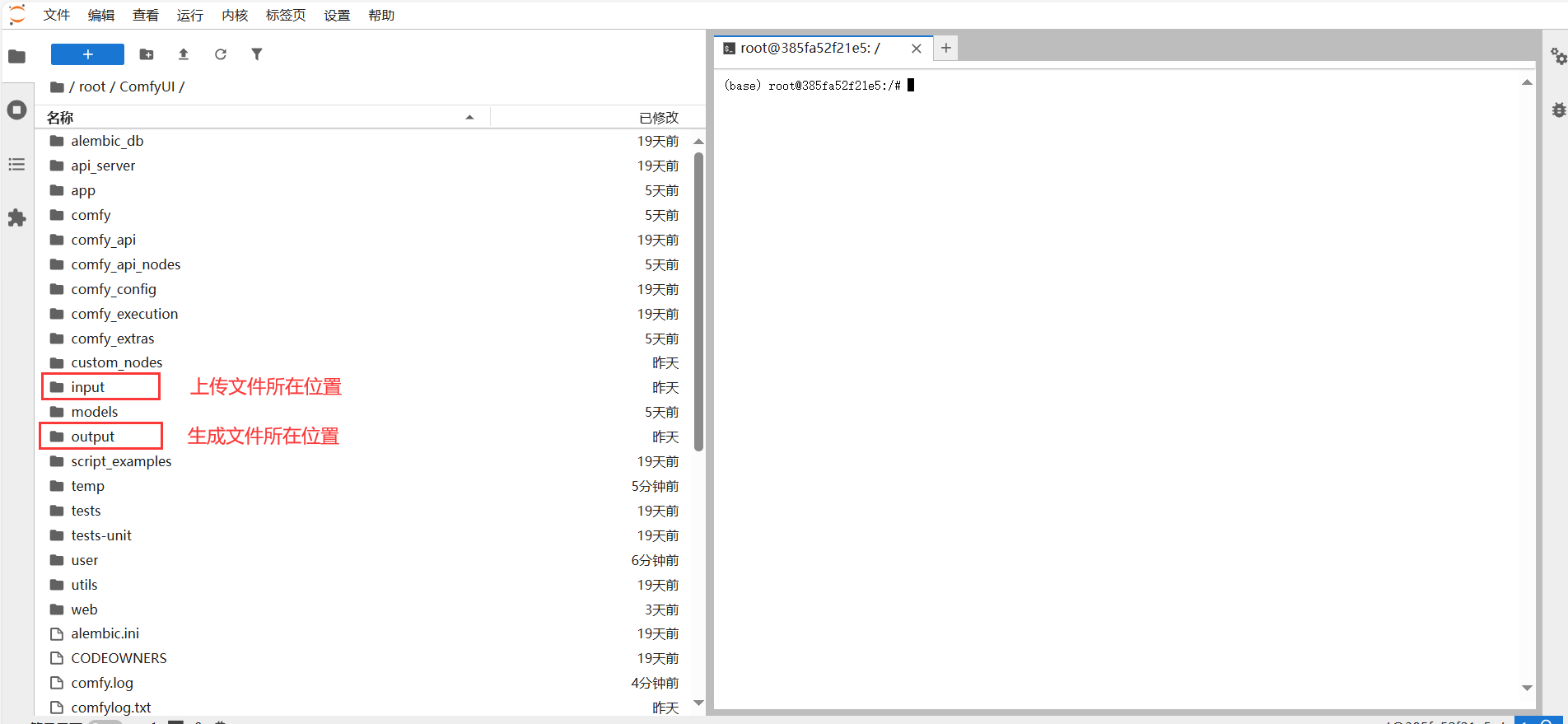
首先点击“JupyterLab”进入后台文件夹,其中Input是上传文件存放的位置,比如图片音频视频等,output文件夹是所有生成文件存放的位置
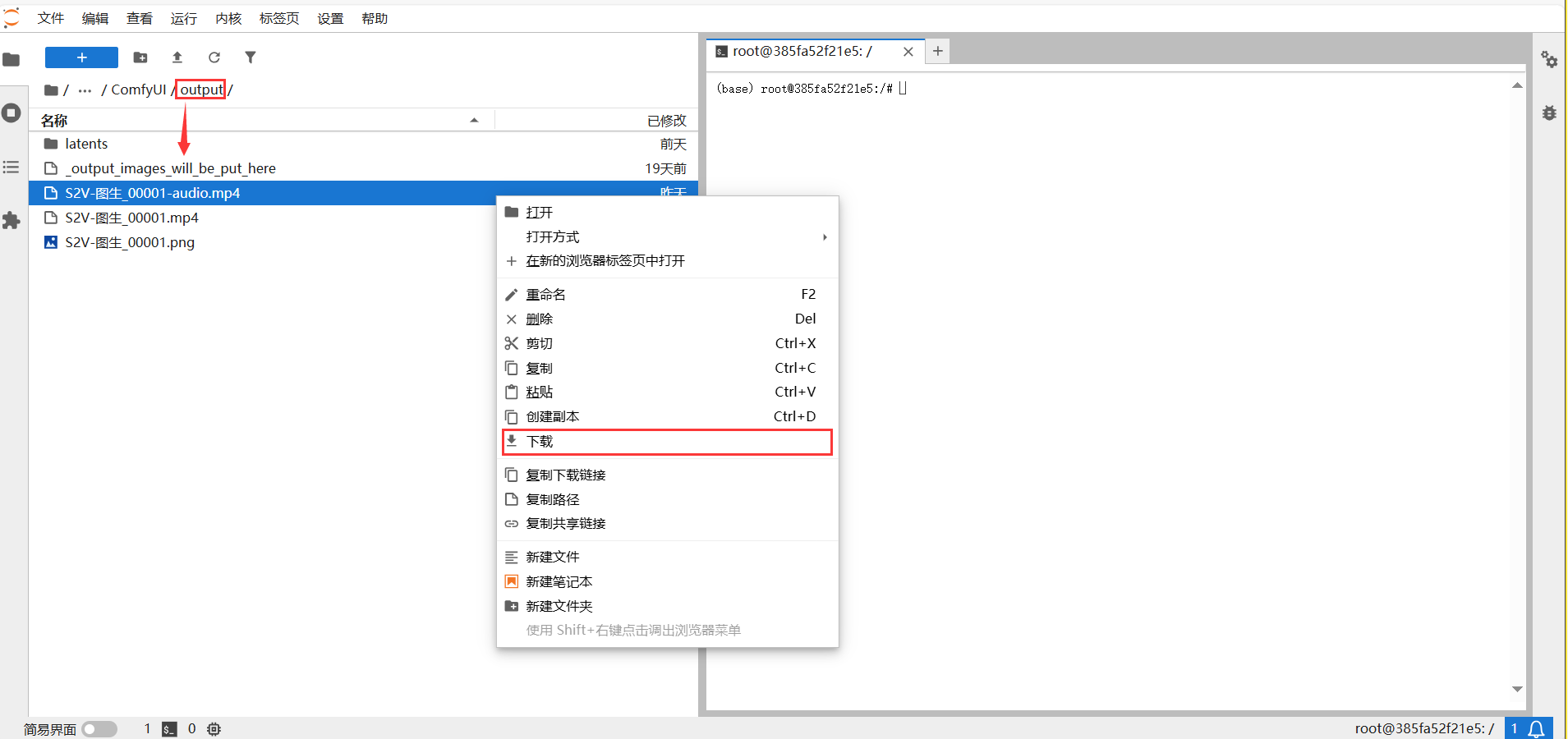
 点击进入output文件夹,选中要下载的文件,右键点击弹出窗口选这下载即可
点击进入output文件夹,选中要下载的文件,右键点击弹出窗口选这下载即可
欢迎加入社恐的知识树-作者交流群

@社恐的知识树 认证作者
认证作者
认证作者
镜像信息
已使用104 次
运行时长
121 H
镜像大小
100GB
最后更新时间
2025-09-06
支持卡型
RTX40系20803080Ti309048G RTX40系2080TiH20A800P40A100RTX50系V100S
+12
框架版本
CUDA版本
12.8
应用
JupyterLab: 8888
版本
v1.0
2025-09-06