AudioX 统一音频生成平台通过一段提示词一段视频推理一段配音音效 webui汉化构建by科哥
AudioX 统一音频生成平台通过一段提示词一段视频推理一段配音音效 webui汉化构建by科哥
 2
20元/小时
v1.1
AudioX 统一音频生成平台通过一段提示词一段视频推理一段配音音效 webui汉化构建by科哥
镜像简介
本镜像提供AudioX统一音频生成平台的汉化WebUI界面,支持通过文字提示词或输入视频智能生成匹配的配音、音效与背景音乐。推荐30/40系列显卡运行,适用于短视频制作、影视后期、广告配音及多媒体内容创作等场景,为用户提供高效、便捷的一站式AI音效生成解决方案。
镜像使用指南
1、该镜像支持自启动,初始化后,需要等待服务启动,大概2分钟左右,可以输入命令 tail -50f /root/wan/log.txt 查看启动日志
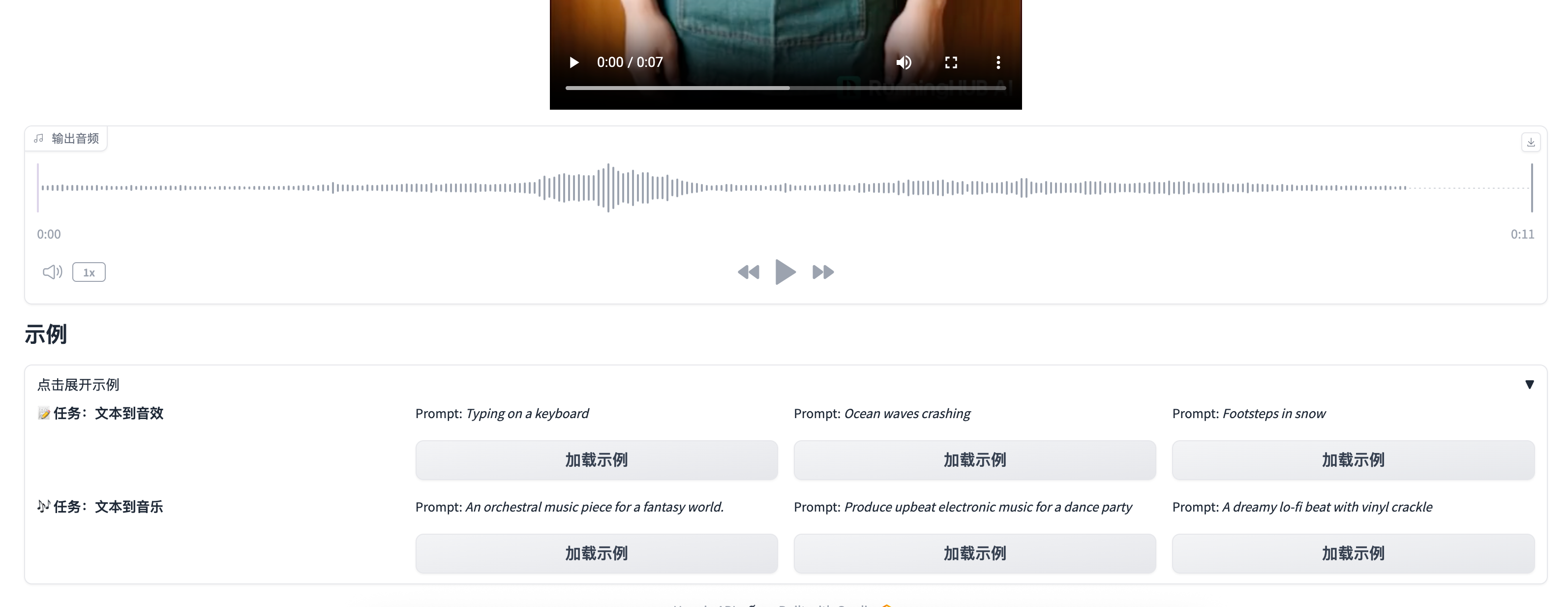
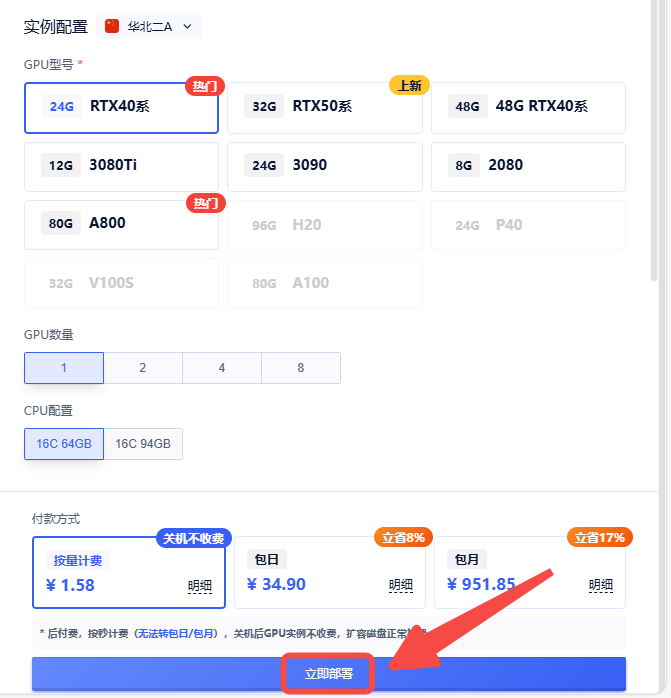 2、随后点击 SD-WEBUI 按钮即可,上传音色文件或者选择音色,点击生成即可
2、随后点击 SD-WEBUI 按钮即可,上传音色文件或者选择音色,点击生成即可
运行截图:
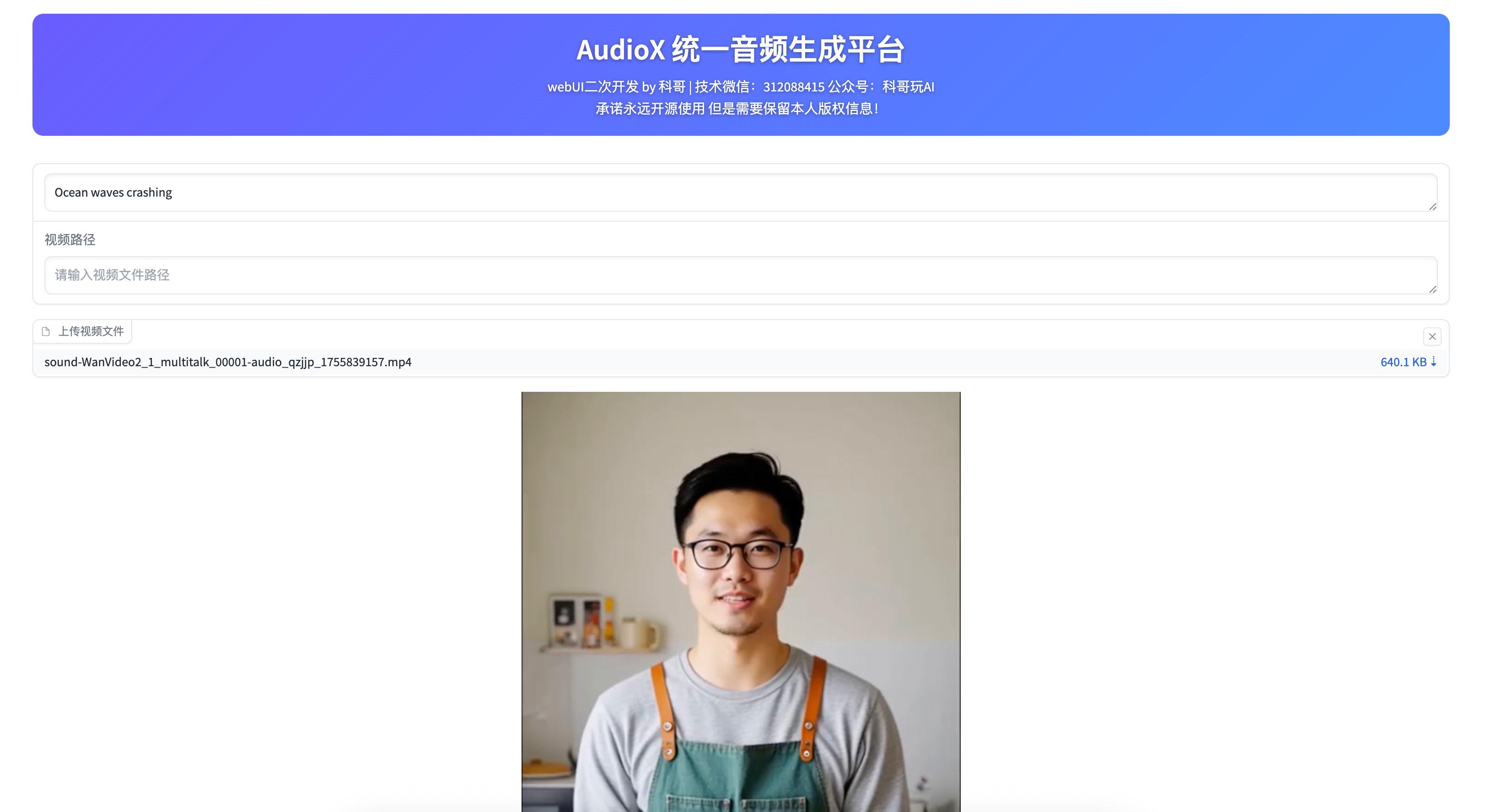
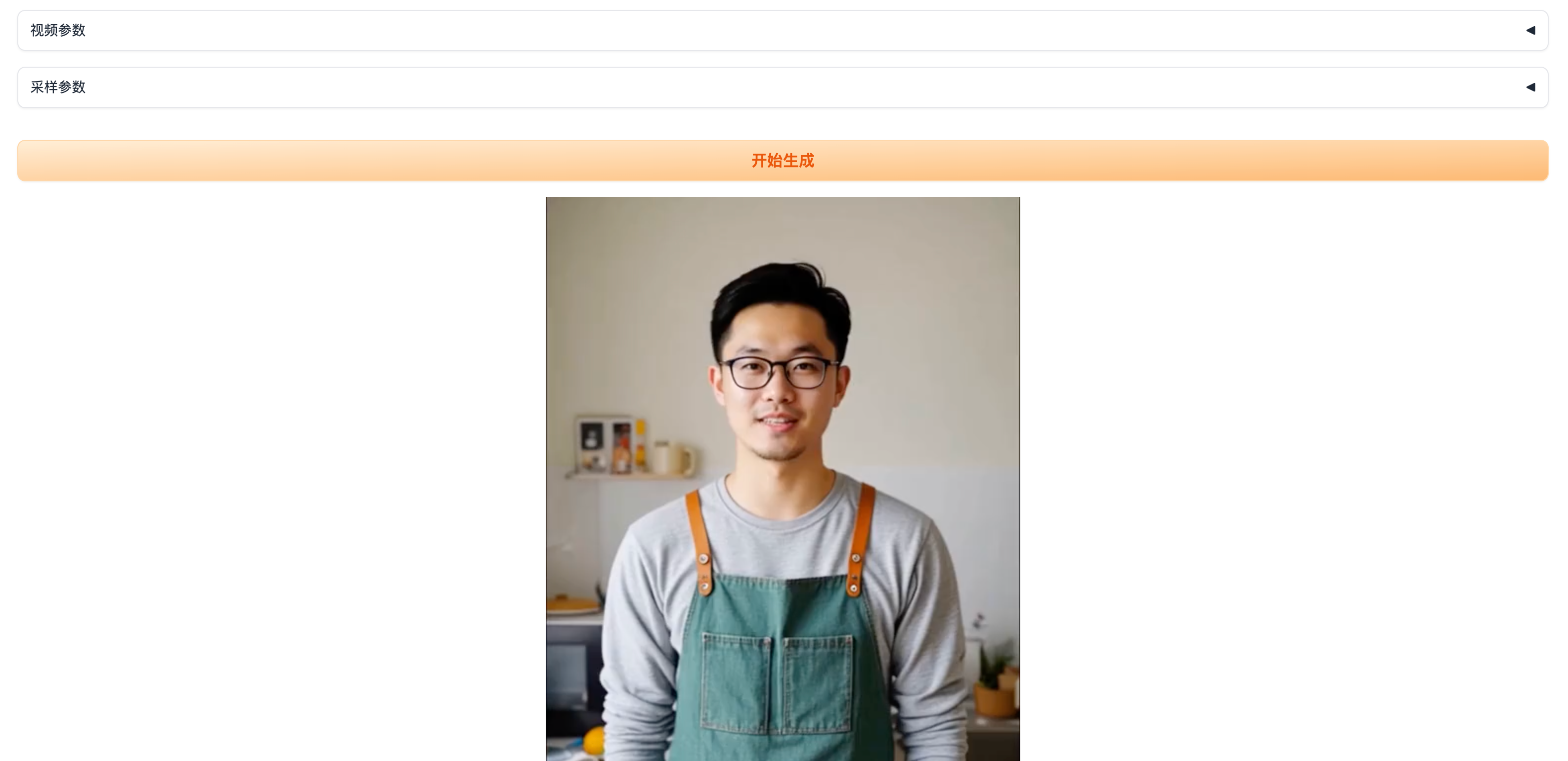
用户使用手册(AudioX WebUI)
1. 你可以做什么
本页面用于统一音频生成,支持以下常见任务:
- 文本到音效(如键盘声、海浪声、脚步声)
- 文本到音乐(如管弦乐、电子乐、Lo-fi)
- 基于视频条件生成音频(可输入视频路径或上传视频)
2. 页面区域说明
2.1 顶部信息区
- 标题:
AudioX 统一音频生成平台 - 副标题:版权与联系信息
2.2 输入区
提示词:描述你想生成的声音/音乐(核心输入)视频路径:本地视频文件路径(可选)上传视频文件:直接上传视频(可选)上传音频提示文件/音频提示路径:用于特定条件输入(默认隐藏)
2.3 参数区
视频参数视频起始秒:从视频第几秒开始读取条件生成时长(秒):生成音频的时长
采样参数采样步数:越大通常细节更多,但推理更重预览间隔:中间预览频率(0 表示关闭)CFG 强度:文本约束强度随机种子(-1 为随机):固定种子可复现结果采样器类型:采样算法选择Sigma 最小值 / 最大值、CFG 重缩放:高级采样控制
初始音频(默认隐藏):用于在已有音频基础上继续生成
2.4 操作与结果区
开始生成:执行生成输出视频:展示合成后视频(如有)输出音频:展示生成结果音频发送到初始音频:把当前输出送回“初始音频”继续迭代
2.5 示例区(默认展开)
- 点击
加载示例可自动填入提示词和推荐参数,快速体验
3. 标准使用流程(推荐)
- 在
提示词输入你想要的声音描述(尽量具体)。 - 按需设置:
- 纯文本生成:可不填视频
- 视频条件生成:填写
视频路径或上传视频
- 先用默认参数直接点
开始生成。 - 根据结果微调:
- 不够贴合描述:适当提高
CFG 强度 - 细节不足:提高
采样步数 - 想复现当前结果:记录并固定
随机种子
- 不够贴合描述:适当提高
4. 提示词编写建议
- 建议结构:
声音主体 + 场景 + 节奏/情绪 + 质感 - 示例:
雨夜街道上的脚步声,近距离,带轻微回声轻快电子舞曲,128bpm,明亮合成器,适合派对梦幻Lo-fi,低保真黑胶噪声,舒缓氛围
5. 常见问题
5.1 点击开始生成后没有结果
- 先检查提示词是否为空
- 检查视频路径是否有效(若使用了视频条件)
- 先用示例按钮验证流程是否正常
5.2 结果不稳定、每次都不同
- 将
随机种子从-1改成固定数字
5.3 结果与预期偏差较大
- 增加提示词细节
- 调整
CFG 强度和采样步数 - 尝试更换
采样器类型
5.4 视频相关输入无效
- 优先使用上传方式测试
- 使用路径时确保文件存在且可读
6. 最佳实践
- 第一次先用默认参数跑通,再逐项微调。
- 每次只改 1~2 个参数,便于判断影响。
- 对满意结果记录:提示词、种子、采样器、步数,便于复现。
bug反馈可以加入科哥专属群交流➕ 广告勿进!

科哥在UCloud镜像列表【不断更新中】:
@鸡你太美 认证作者
认证作者
认证作者
镜像信息
已使用27 次
运行时长
56 H
 支持自启动
支持自启动镜像大小
60GB
最后更新时间
2026-04-27
支持卡型
3090RTX40系48G RTX40系3080Ti2080Ti2080A800H20V100SA100
+10
框架版本
CUDA版本
12.8
应用
JupyterLab: 8888
版本
v1.1
2026-04-27