Step-Audio TTS在线语音克隆3B模型 构建By科哥
Step-Audio TTS在线语音克隆3B模型 构建By科哥
 3
30元/小时
v1.0
Step-Audio TTS在线语音克隆3B模型 构建By科哥
镜像简介
https://github.com/stepfun-ai/Step-Audio/blob/main/README_CN.md
Step-Audio 是业界首个集语音理解与生成控制一体化的产品级开源实时语音对话系统,支持多语言对话(如 中文,英文,日语),语音情感(如 开心,悲伤),方言(如 粤语,四川话),可控制语速及韵律风格,支持RAP和哼唱等。其核心技术突破体现在以下四大技术亮点:
1300亿多模态模型: 单模型能实现理解生成一体化完成语音识别、语义理解、对话、语音克隆、语音生成等功能,开源千亿参数多模态模型 Step-Audio-Chat。
高效数据生成链路: 基于130B 突破传统 TTS 对人工采集数据的依赖,生成高质量的合成音频数据,并同步开源首个基于大规模合成数据训练,支持 RAP 和哼唱的指令加强版语音合成模型 Step-Audio-TTS-3B 。
精细语音控制: 支持多种情绪(如生气,高兴,悲伤)、方言(包括粤语、四川话等)和唱歌(包括 RAP、干声哼唱)的精准调控,满足用户对多样化语音生成的需求。
扩展工具调用: 通过 ToolCall 机制和角色扮演增强,进一步提升其在 Agents 和复杂任务中的表现。
bug反馈可以加入科哥专属群交流!

使用教程
已经设置开机运行 大概需要等待3-5分钟加载大模型。 1.创建实例
2.选择合适的机型,立即部署
 3.运行完成,加载完毕模型后,在控制台打开【webui】即可进入使用界面;
3.运行完成,加载完毕模型后,在控制台打开【webui】即可进入使用界面;
4.卡顿时候,点击【重启应用】,释放资源,等待完成启动,再次打开 【webui】即可进入使用界面;
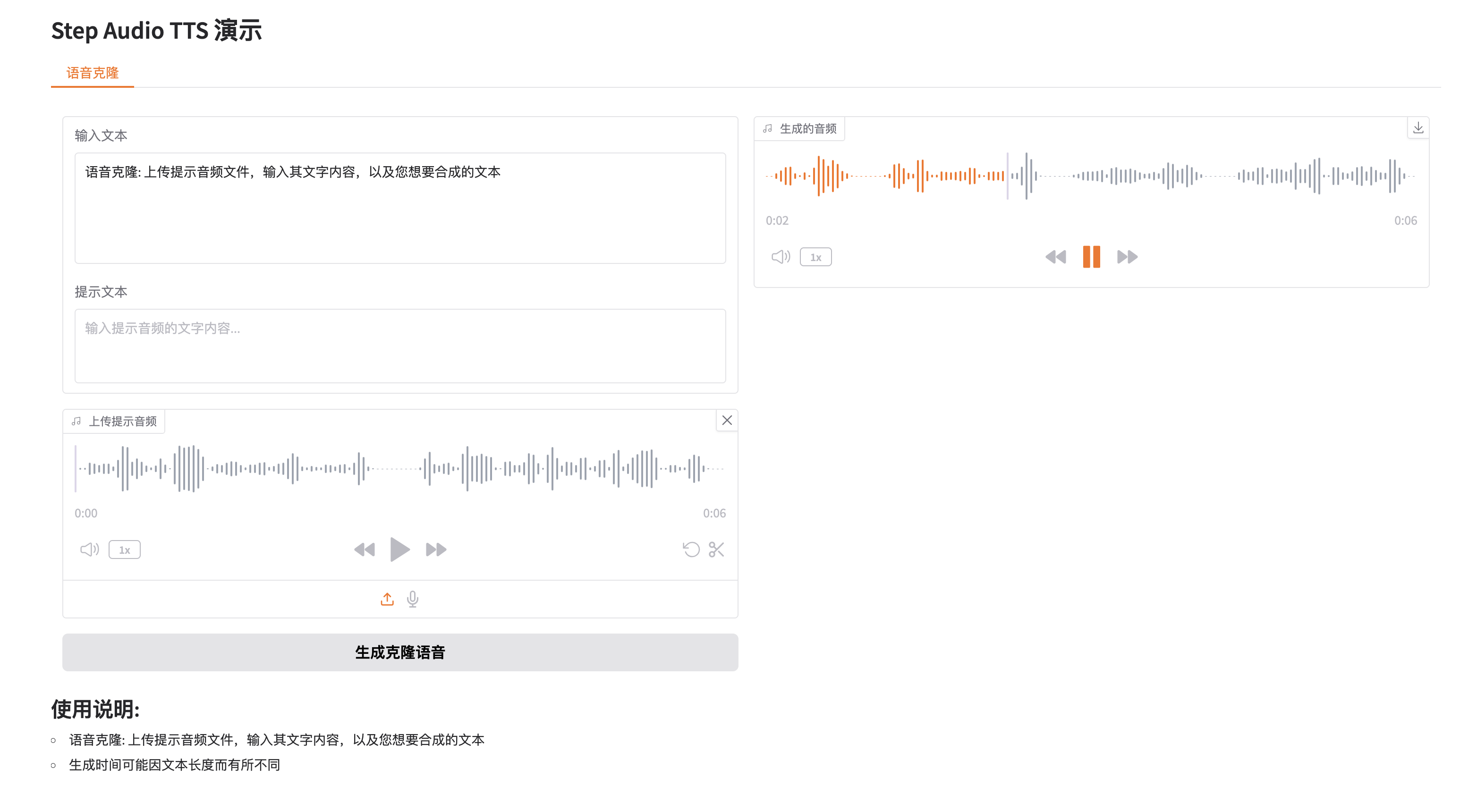
更多高级指令,可以进入jupyterlab,自行操作,例如:
查看进程:
ps -ef |grep python
终止进程:
kill -9 pid
官方更新源码在这里: https://modelscope.cn/studios/Swarmeta_AI/Step-Audio-TTS-3B
有bug请微信科哥: 312088415
@鸡你太美 认证作者
认证作者
认证作者

镜像信息
已使用28 次
运行时长
31 H
 支持自启动
支持自启动镜像大小
80GB
最后更新时间
2026-04-27
支持卡型
RTX40系20803080Ti309048G RTX40系2080TiH20A800P40A100RTX50系V100SV100S
+13
框架版本
CUDA版本
12.4
应用
JupyterLab: 8888
版本
v1.0
2026-04-27