FireRedASR2S语音识别转文字语音转文本音频转文本模型ai系统 二次构建开发 by科哥
FireRedASR2S语音识别转文字语音转文本音频转文本模型ai系统 二次构建开发 by科哥
 2
20元/小时
v1.1
FireRedASR2S语音识别转文字语音转文本音频转文本模型ai系统 二次构建开发 by科哥
FireRedASR2S是什么
- FireRedASR2S是小红书Super Intelligence-AudioLab开源的工业级端到端语音识别模型
- 集成ASR、VAD、语种识别和标点预测四大SOTA模块。模型支持中文普通话及20+方言、英语、代码切换和歌词识别
- 中文普通话字错率低至2.89%,方言平均11.55%,全面领先Doubao-ASR、Qwen3-ASR等竞品。
- 系统支持一键本地部署,无需外部API,已在小红书语音评论、语音搜索等高频场景规模化落地。
镜像使用教程
1、 创建实例
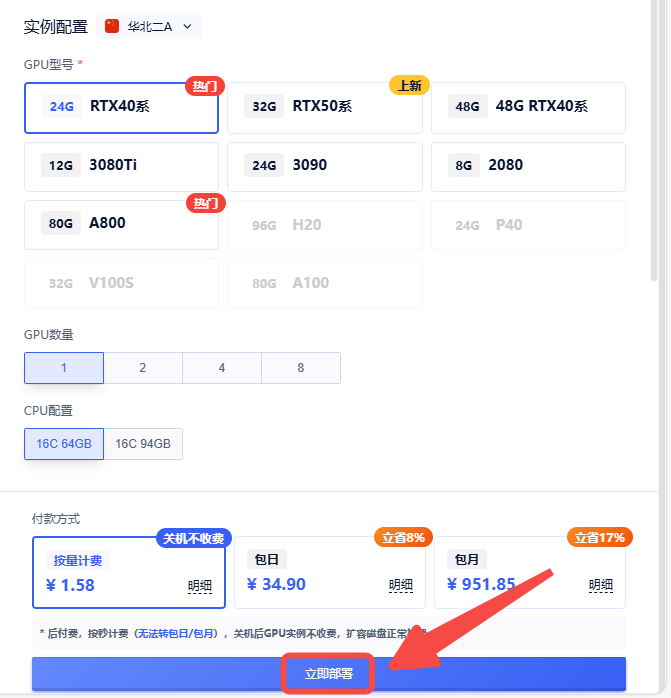
2、启动后点击「SD-WebUI」操作页面会在新的网页窗口打开

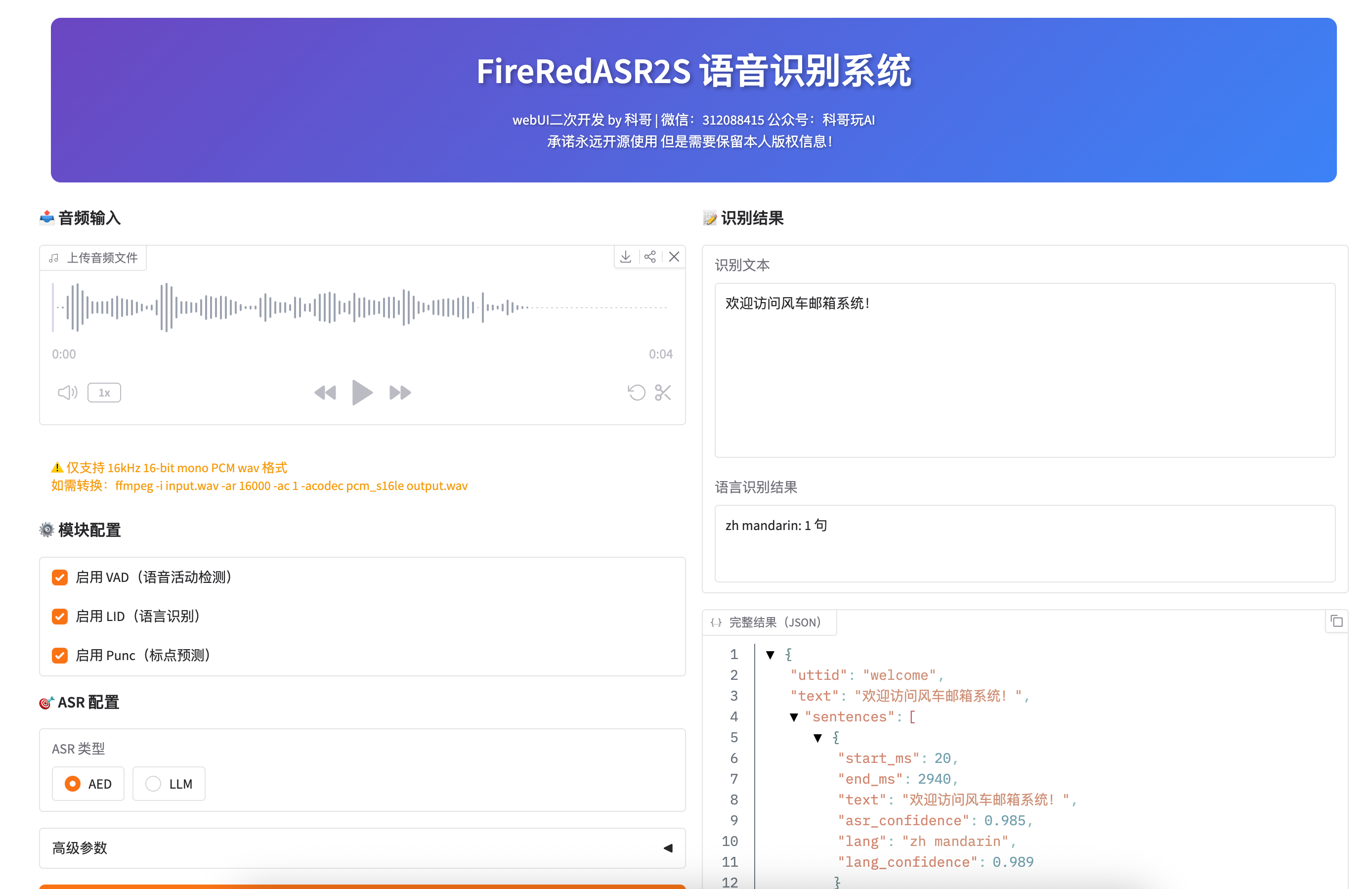
运行截图:
FireRedASR2S WebUI 用户使用手册
开发者: 科哥 (微信: 312088415 | 公众号: 科哥玩AI) 仓库地址: https://github.com/kegeai888/FireRedASR2S-webui-WebUI 原始项目: https://github.com/FireRedTeam/FireRedASR2S
📖 简介
FireRedASR2S 是工业级全栈语音识别系统,支持:
- 🎤 语音识别(中英文等多语言)
- 🔊 语音活动检测(VAD)
- 🌍 语言识别(100+ 语言)
- ✏️ 标点预测
本 WebUI 提供友好的图形界面,无需命令行即可使用。
🚀 快速开始
1. 下载模型(首次使用)
bash download_models.sh
说明:
- 自动下载 4 个模型到
models/目录 - 使用国内镜像加速,约需 5-10 分钟
- 仅需执行一次
2. 启动 WebUI
bash start_app.sh
说明:
- 自动激活 py310 环境
- 自动清理显存和端口占用
- 启动成功后访问:http://localhost:7860
🎯 使用步骤
步骤 1: 上传音频
点击"上传音频文件",选择你的音频文件。
支持格式:
- 任意格式(mp3、wav、m4a、flac 等)
- 系统会自动转换为 16kHz 单声道 PCM
音频长度限制:
- AED 模式:建议 60 秒以内(超过 200 秒会报错)
- LLM 模式:建议 30 秒以内
- 长音频:请启用 VAD 自动分段
步骤 2: 配置模块
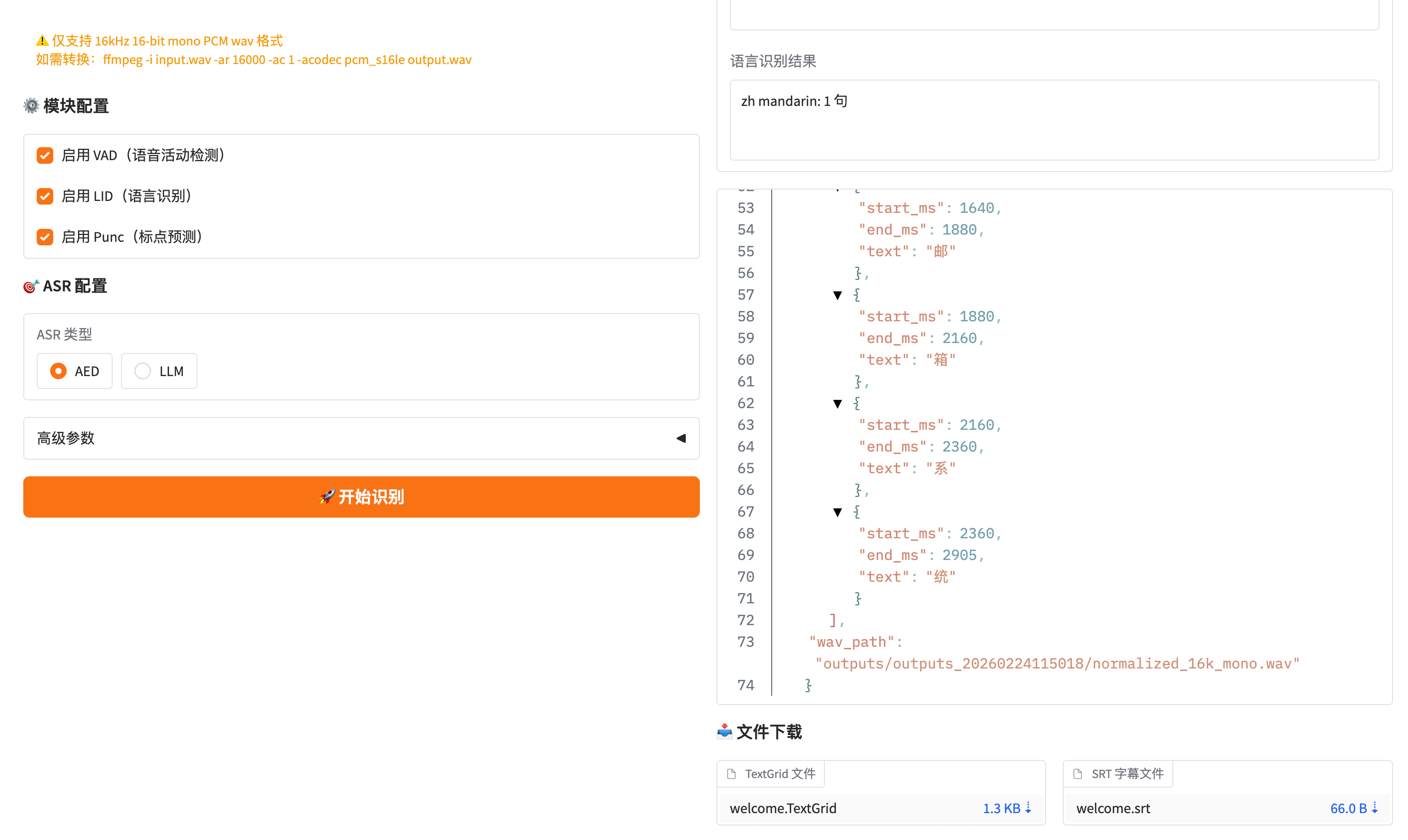
模块开关:
- ✅ 启用 VAD:自动检测语音段,过滤静音(推荐开启)
- ✅ 启用 LID:识别音频语言(中文、英文等)
- ✅ 启用 Punc:自动添加标点符号(推荐开启)
ASR 类型:
- AED(推荐):速度快,支持 60 秒音频
- LLM:效果更好,但仅支持 30 秒音频
步骤 3: 调整参数(可选)
点击"高级参数"展开:
| 参数 | 说明 | 推荐值 |
|---|---|---|
| Beam Size | 解码束宽,越大越准确但越慢 | 3 |
| ASR Batch Size | ASR 批处理大小 | 1 |
| Punc Batch Size | 标点批处理大小 | 1 |
| 使用 GPU | 是否使用 GPU 加速 | ✅ |
步骤 4: 开始识别
点击"🚀 开始识别"按钮,等待处理完成。
处理流程:
- 音频格式转换(如需要)
- 加载模型(首次较慢,后续会缓存)
- VAD 分段(如启用)
- 语音识别
- 语言识别(如启用)
- 标点预测(如启用)
- 生成结果文件
步骤 5: 查看结果
识别文本:
- 显示完整的识别结果(带标点)
语言识别结果:
- 显示检测到的语言及句子数量
- 例如:
zh mandarin: 5 句
完整结果(JSON):
- 包含时间戳、置信度等详细信息
- 可用于二次开发
文件下载:
- TextGrid 文件:用于 Praat 等语音分析工具
- SRT 字幕文件:可直接用于视频字幕
📂 输出文件说明
每次识别会在 outputs/ 目录下创建时间戳文件夹:
outputs/
└── outputs_20260224112734/
├── result.json # 完整结果(JSON 格式)
├── normalized_16k_mono.wav # 转换后的音频
├── hello_zh.TextGrid # TextGrid 文件
└── hello_zh.srt # SRT 字幕文件
⚙️ 使用场景
场景 1: 会议录音转写
配置:
- ✅ 启用 VAD(过滤静音)
- ✅ 启用 Punc(添加标点)
- ✅ 启用 LID(识别语言)
- ASR 类型:AED
适用:
- 会议录音
- 采访录音
- 讲座录音
场景 2: 短音频精准识别
配置:
- ❌ 关闭 VAD(音频已预处理)
- ❌ 关闭 LID(已知语言)
- ✅ 启用 Punc
- ASR 类型:LLM
适用:
- 语音指令
- 短句识别
- 高精度场景
场景 3: 多语言音频
配置:
- ✅ 启用 VAD
- ✅ 启用 LID(重要!)
- ✅ 启用 Punc
- ASR 类型:AED
适用:
- 多语言会议
- 国际采访
- 语言学习材料
❓ 常见问题
Q1: 识别结果不准确怎么办?
解决方案:
- 确保音频质量良好(无噪音、清晰)
- 尝试调整 Beam Size(增大到 5-10)
- 尝试切换 ASR 类型(AED ↔ LLM)
- 启用 VAD 过滤静音段
Q2: 长音频识别失败?
解决方案:
- 必须启用 VAD(自动分段)
- 确保音频不超过 60 秒(AED)或 30 秒(LLM)
- 或使用 ffmpeg 手动分段:
ffmpeg -i long.wav -f segment -segment_time 30 -c copy output%03d.wav
Q3: 显存不足怎么办?
解决方案:
- 关闭 GPU:取消勾选"使用 GPU"
- 减小 Batch Size(改为 1)
- 重启 WebUI 清理显存:
bash start_app.sh
Q4: 端口 7860 被占用?
解决方案:
start_app.sh会自动释放端口- 如仍失败,手动终止进程:
lsof -ti:7860 | xargs kill -9
Q5: 模型加载很慢?
说明:
- 首次加载需要 10-30 秒(正常)
- 后续会缓存模型,速度显著提升
- 切换配置(如 AED ↔ LLM)会重新加载
Q6: 音频格式不支持?
解决方案:
- WebUI 会自动转换格式,无需手动处理
- 如仍失败,使用 ffmpeg 手动转换:
ffmpeg -i input.mp3 -ar 16000 -ac 1 -acodec pcm_s16le output.wav
🛠️ 命令行使用(高级)
如需批量处理或脚本调用,可使用 CLI:
python fireredasr2s/fireredasr2s_cli.py \
--wav_path audio.wav \
--enable_vad 1 \
--enable_lid 1 \
--enable_punc 1 \
--asr_type aed
批量处理:
python fireredasr2s/fireredasr2s_cli.py \
--wav_dir /path/to/audio_folder \
--asr_batch_size 4
详细参数:
python fireredasr2s/fireredasr2s_cli.py --help
📞 技术支持
遇到问题?
- 微信:312088415
- 公众号:科哥玩AI
反馈建议?
- 欢迎提交 Issue 或 Pull Request
📄 版权声明
本 WebUI 由科哥二次开发,承诺永远开源使用,但需保留版权信息。
原始 FireRedASR2S 项目版权归 Xiaohongshu 所有。
祝使用愉快! 🎉
bug反馈可以加入科哥专属群交流➕ 广告勿进!

科哥在UCloud镜像列表【不断更新中】:
@鸡你太美 认证作者
认证作者
认证作者
镜像信息
已使用26 次
运行时长
28 H
 支持自启动
支持自启动镜像大小
60GB
最后更新时间
2026-04-27
支持卡型
3080TiRTX40系48G RTX40系2080Ti30902080A800H20P40V100SA100
+11
框架版本
CUDA版本
12.8
应用
JupyterLab: 8888
版本
v1.1
2026-04-27