Wan2.2-S2V数字人-对口型-音频驱动视频生成
Wan2.2-S2V数字人,通过一张静态图片和一段音频(如说话或唱歌)自动生成高质量、口型同步的电影级视频。
 23
230元/小时
v1.0
Wan2.2-S2V-ComfyUI-多种玩法合集
镜像简介
阿里巴巴通义实验室推出的Wan-S2V是一款先进的AI模型,它能通过一张静态图片和一段音频(如说话或唱歌)自动生成高质量、口型同步的电影级视频。该模型不仅能产生逼真的面部表情和身体动作,还支持复杂的场景渲染和专业运镜效果,适用于对话、演唱、表演等多种专业创作场景,在多项关键技术指标上达到行业领先水平。
镜像使用教程
镜像作者视频:
1.创建实例
建议租用48GB显存的4090
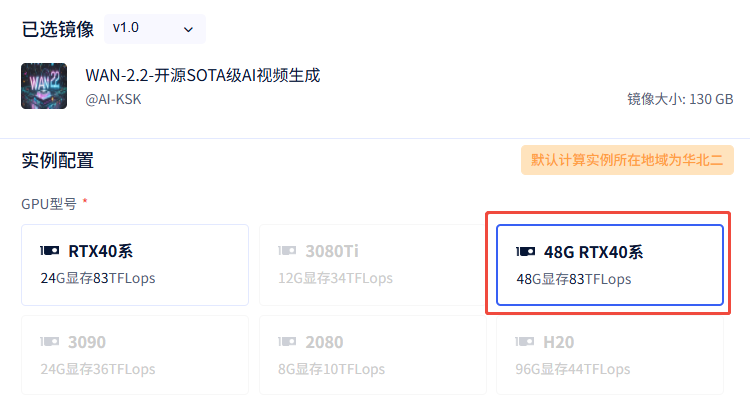
2.启动后点击JupyterLab
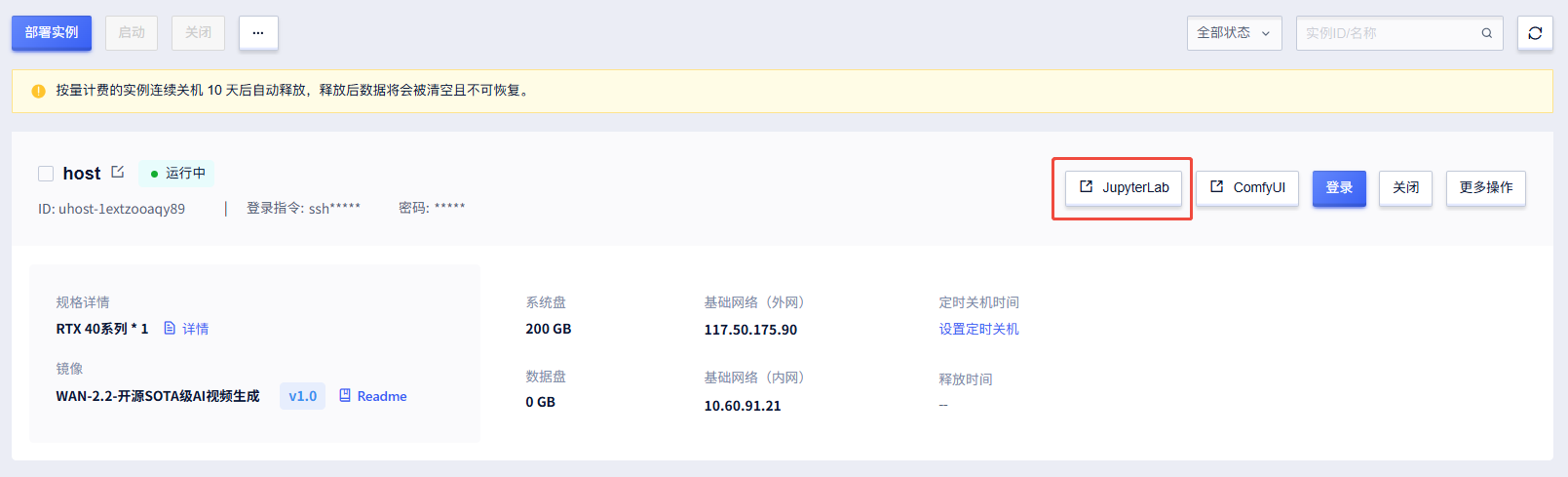
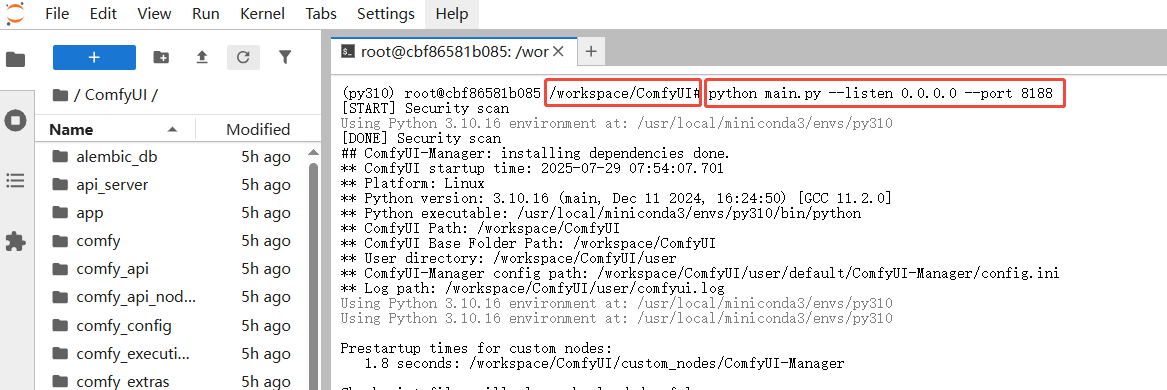
3.ComfyUI路径下打开Terminal

复制启动命令并运行
source venv/bin/activate && python main.py --listen 0.0.0.0 --port 8188
4.点击ComfyUI启动进入
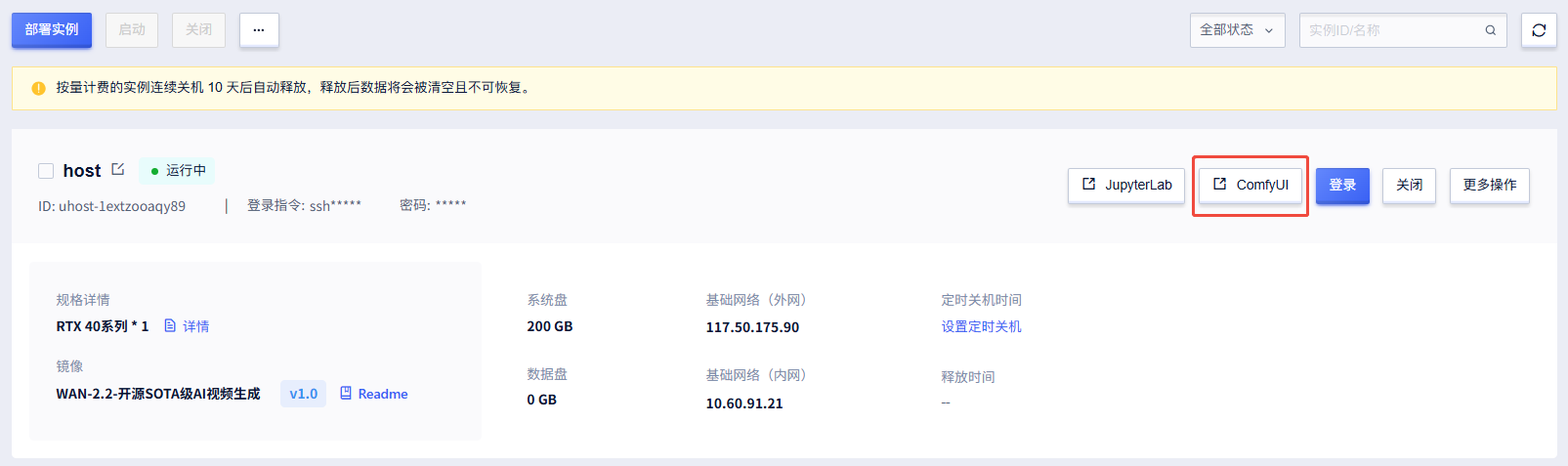
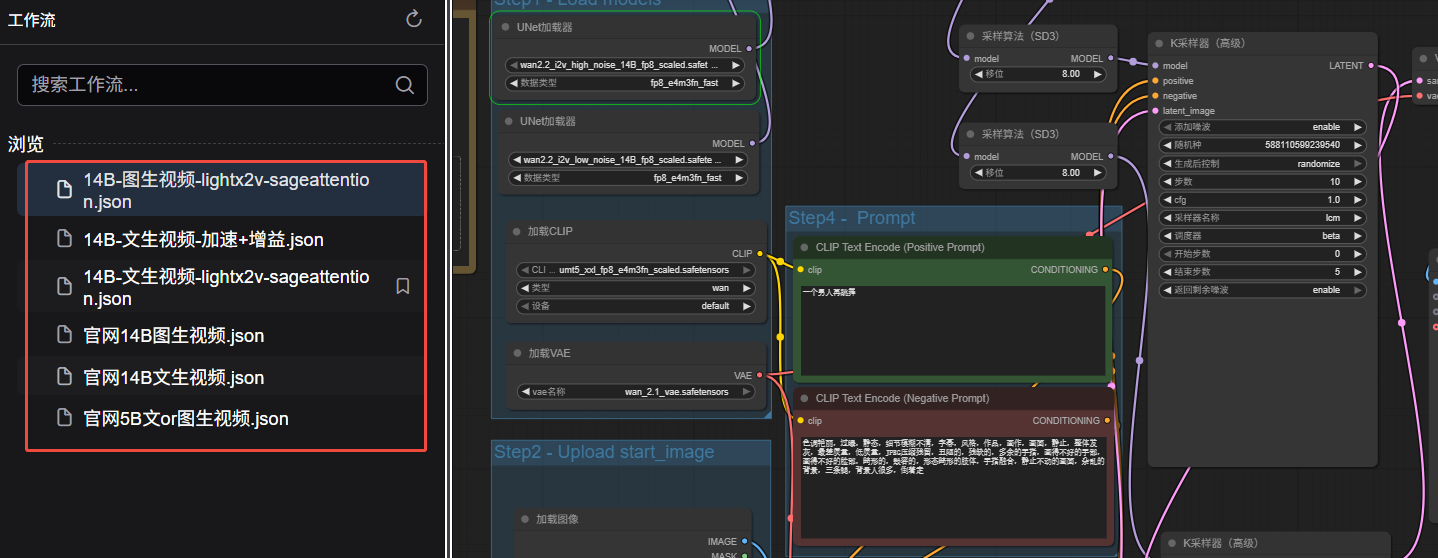
5.点击左侧文件夹,选择想要运行的工作流
欢迎加入AI-KSK镜像使用交流群

@AI-KSK 认证作者
认证作者
认证作者

镜像信息
已使用241 次
运行时长
344 H
镜像大小
130GB
最后更新时间
2026-02-02
支持卡型
RTX40系20803080Ti309048G RTX40系2080TiH20A800P40A100RTX50系V100S
+12
框架版本
CUDA版本
12.8
应用
JupyterLab: 8888
版本
v1.0
2026-02-02