 13
13镜像使用指南
教学视频:
本镜像已内置 WebUI。启动实例后,点击 WebUI 即可进入操作页面。
推荐配置
进入 WebUI 后,左侧建议先这样设置:
分辨率:720P Block Swap:开启 卸载到内存的 DIT blocks:48
这里最重要的是 Block Swap。
Block Swap 开到 48 后,可以把 DIT blocks 卸载到内存中,大幅降低显存占用。实测 48GB 显卡也可以运行 720P。
如果想更快,可以使用更高显存的 GPU;如果想更稳,也可以先用 480P 测试。
常用模式
WebUI 内置 6 种官方示例,新手主要看两个:
单人图生长视频 上传 1 张人物图 + 1 段音频,适合单人数字人口播。
双人图生长视频 上传 1 张双人图 + 2 段音频,适合双人对话。
段落数怎么算
视频长度由 段落数 决定,不是由音频自动决定。
第 1 段约 3.72 秒。 之后每增加 1 段,约增加 3.2 秒。
公式:
总时长 = 3.72 +(段落数 - 1)× 3.2
常用参考:
1 段 ≈ 3.72 秒 2 段 ≈ 6.92 秒 3 段 ≈ 10.12 秒 4 段 ≈ 13.32 秒 5 段 ≈ 16.52 秒 10 段 ≈ 32.52 秒
比如 12 秒音频,建议选择 4 段,生成后多出来的部分后期裁掉。
单人提示词怎么写
单人提示词不用复杂,按这个顺序写:
人物是谁 + 场景在哪 + 镜头怎么拍 + 表情动作 + 画面稳定清晰
示例:
A medium shot of one person speaking clearly in a clean indoor studio. Natural facial expression, subtle head movement, accurate lip synchronization, stable camera, clean lighting, consistent identity, high quality video.
如果上传了参考图,提示词不要大幅修改人物长相。
参考图负责人物,提示词主要负责场景、镜头和画面质量。
双人模式怎么用
双人模式建议统一按这个规则:
左边人物 = person1 = 人物一音频 右边人物 = person2 = 人物二音频
提示词建议这样写:
Person1 is on the left. Person2 is on the right. They are having a natural conversation.
如果是先后说话:人物一先说,人物二后说。
如果是穿插说话:准备两条等长音频轨,不说话的位置保留静音。这样模型更容易判断哪一段音频应该驱动哪个人物。
任务队列
点击提交后,任务会进入队列。系统会按顺序运行任务,不会同时并行渲染多个任务。
如果生成结果不满意,可以在任务台终止当前任务,让下一个任务继续执行。
本镜像支持快速启动。
启动实例后,可直接进入 ComfyUI 使用,无需手动配置环境。
1. 点击 ComfyUI 启动进入
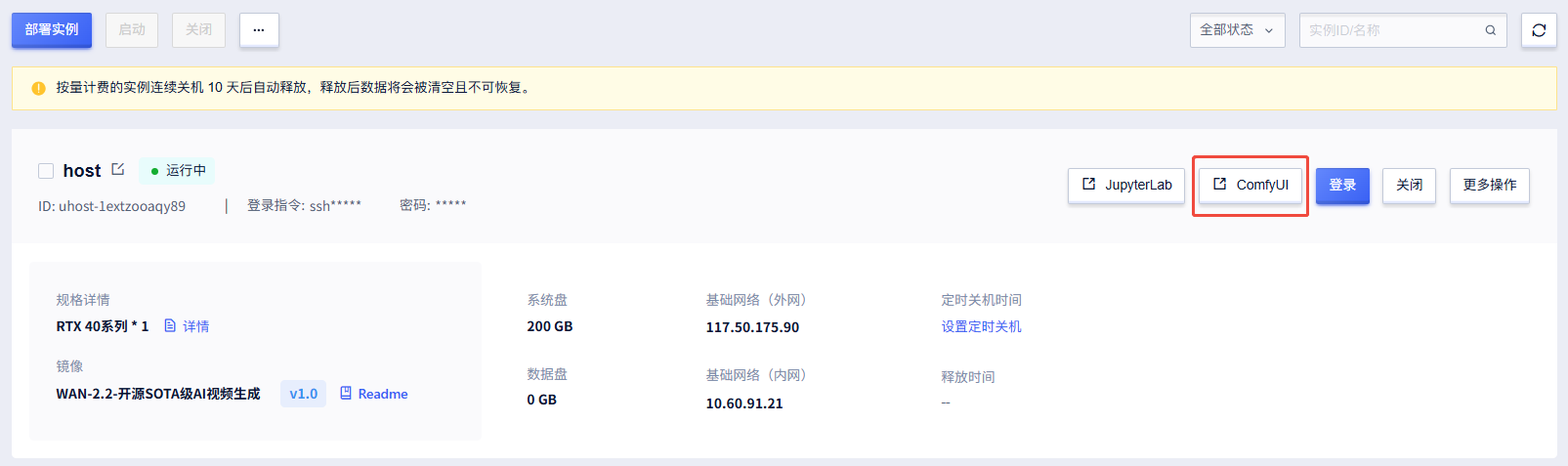
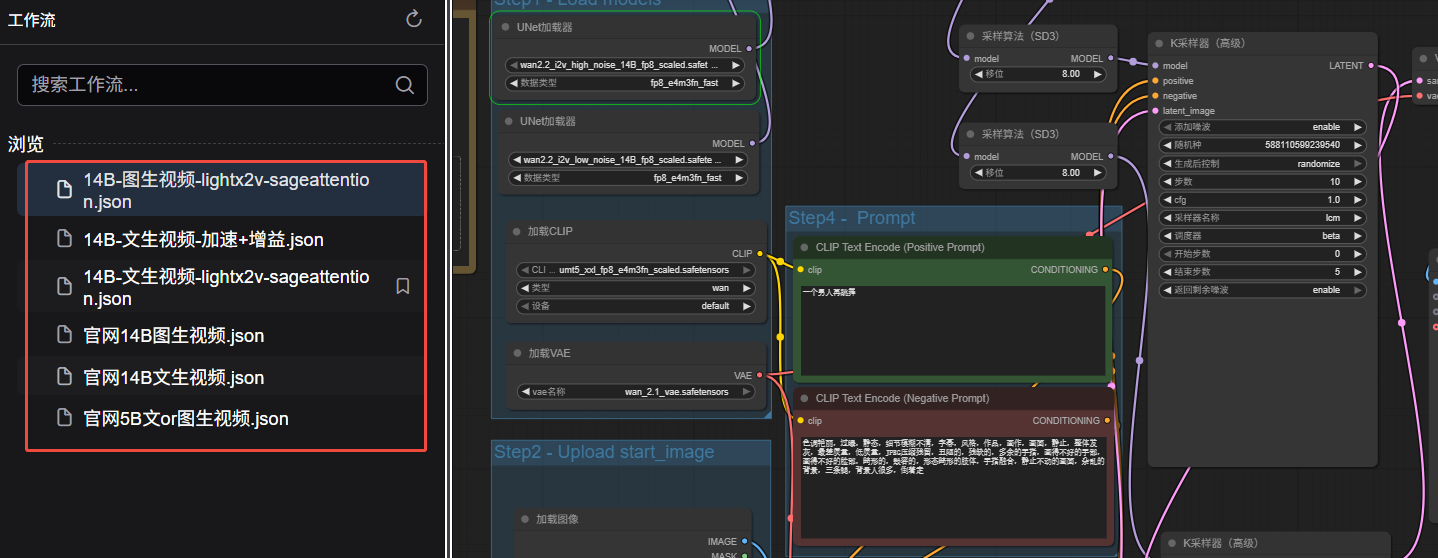
2. 点击左侧文件夹,选择要运行的工作流
欢迎加入 AI-KSK 镜像使用交流群

 认证作者
认证作者

 支持自启动
支持自启动