Wan2.2-S2V-14B: 音频驱动的电影视频生成
通过音频驱动的图片转视频生成软件,支持声音克隆功能
 2
20元/小时
v1.0
Wan2.2-S2V-14B: 音频驱动的图片转视频生成
镜像简介
通过一段音频素材和图片生成一个全新的人物讲话视频,人物说话内容就是音频素材内容,可实现音唇同步
镜像使用指南
1、首先点击右侧蓝色按钮【使用该镜像创建实例】
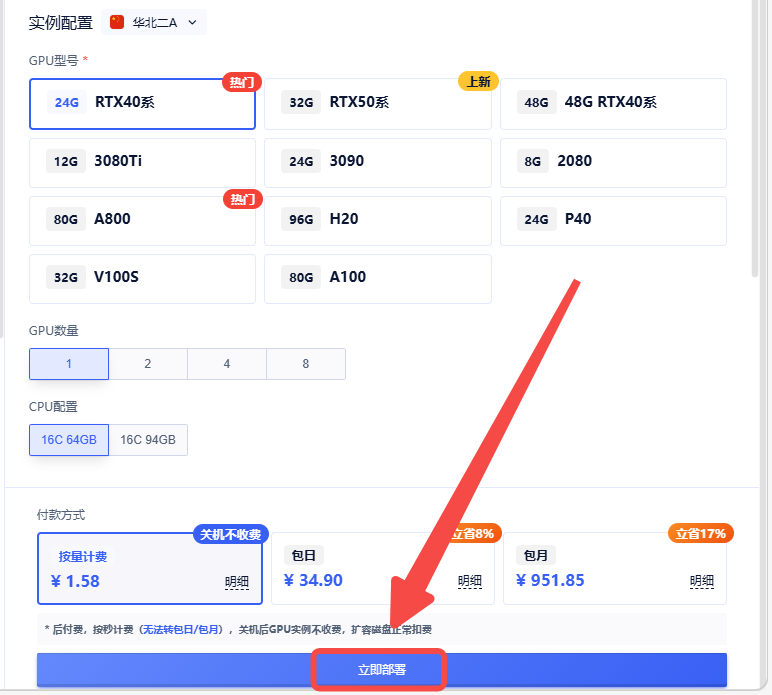
2、GPU选择48G或是96G型号,低显存会导致报错终止,点击下方蓝色按钮【立即部署】
3、稍等一两分钟后实例便会运行,显示【运行中】后继续等待1分钟左右初始化,再点击右侧【SD-WebUI】按钮,即可打开WebUI操作界面

注意
分辨率建议480*832,高分辨率太耗时
生成480P以上视频需要96G显存
如果使用声音克隆功能,音频样本建议3-10秒
@AI画师大阳 认证作者
认证作者
认证作者
镜像信息
已使用119 次
运行时长
120 H
 支持自启动
支持自启动镜像大小
120GB
最后更新时间
2026-02-02
支持卡型
RTX40系20803080Ti309048G RTX40系2080TiH20A800P40A100RTX50系V100SV100S
+13
框架版本
CUDA版本
12.8
应用
JupyterLab: 8888
版本
v1.0
2026-02-02