SoulX-FlashTalk数字人视频图片生成ai数字人说话数字人 webui二次开发
SoulX-FlashTalk数字人视频图片生成ai数字人说话数字人 webui二次开发 构建by科哥
 6
60元/小时
v1.0
SoulX-FlashTalk数字人视频图片生成ai数字人说话数字人 webui二次开发 构建by科哥
1. 项目核心
SoulX-FlashTalk是Soul AI Lab开源的14B音频驱动数字人模型,为首个实现0.87s亚秒级启动延迟、8×H800节点32FPS实时吞吐的模型,主打超长视频稳定生成。
2. 核心技术
采用自纠正双向蒸馏技术,搭配延迟感知时空适配方案,解决数字人生成的身份漂移、画质下降问题,视觉保真度刷新纪录。
3. 部署要求
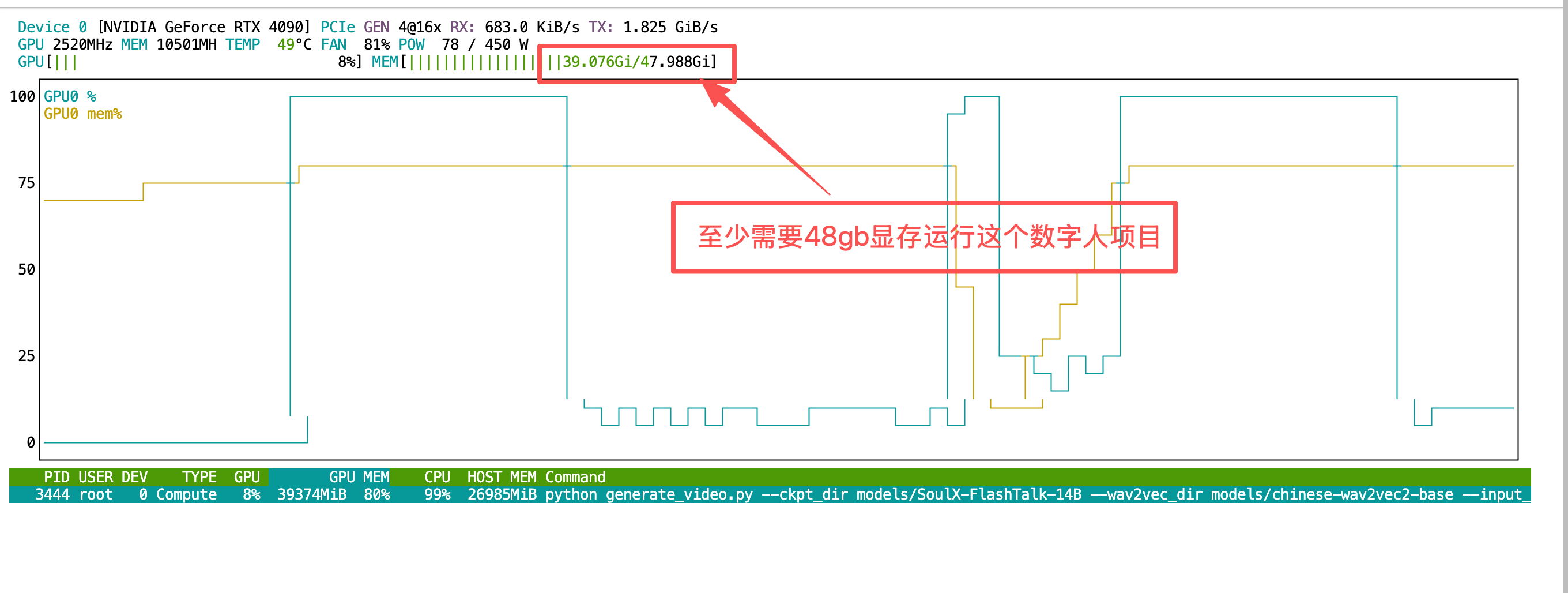
单卡推理需要40系48G显存及以上显卡,使用cpu offload方式可以运行,测试成功!
bug反馈可以加入科哥专属群交流➕ 广告勿进!

科哥在UCloud镜像列表【不断更新中】:
项目运行截图:
SoulX-FlashTalk 用户使用手册
本手册指导用户如何使用 SoulX-FlashTalk 进行音频驱动的虚拟形象视频生成
项目仓库:https://github.com/kegeai888/SoulX-FlashTalk-webUI
📖 目录
🚀 快速开始
启动 WebUI
在项目根目录下运行:
bash start_app.sh
启动成功后,浏览器访问:
- 本地访问:
http://localhost:7860 - 远程访问:
http://[服务器IP]:7860
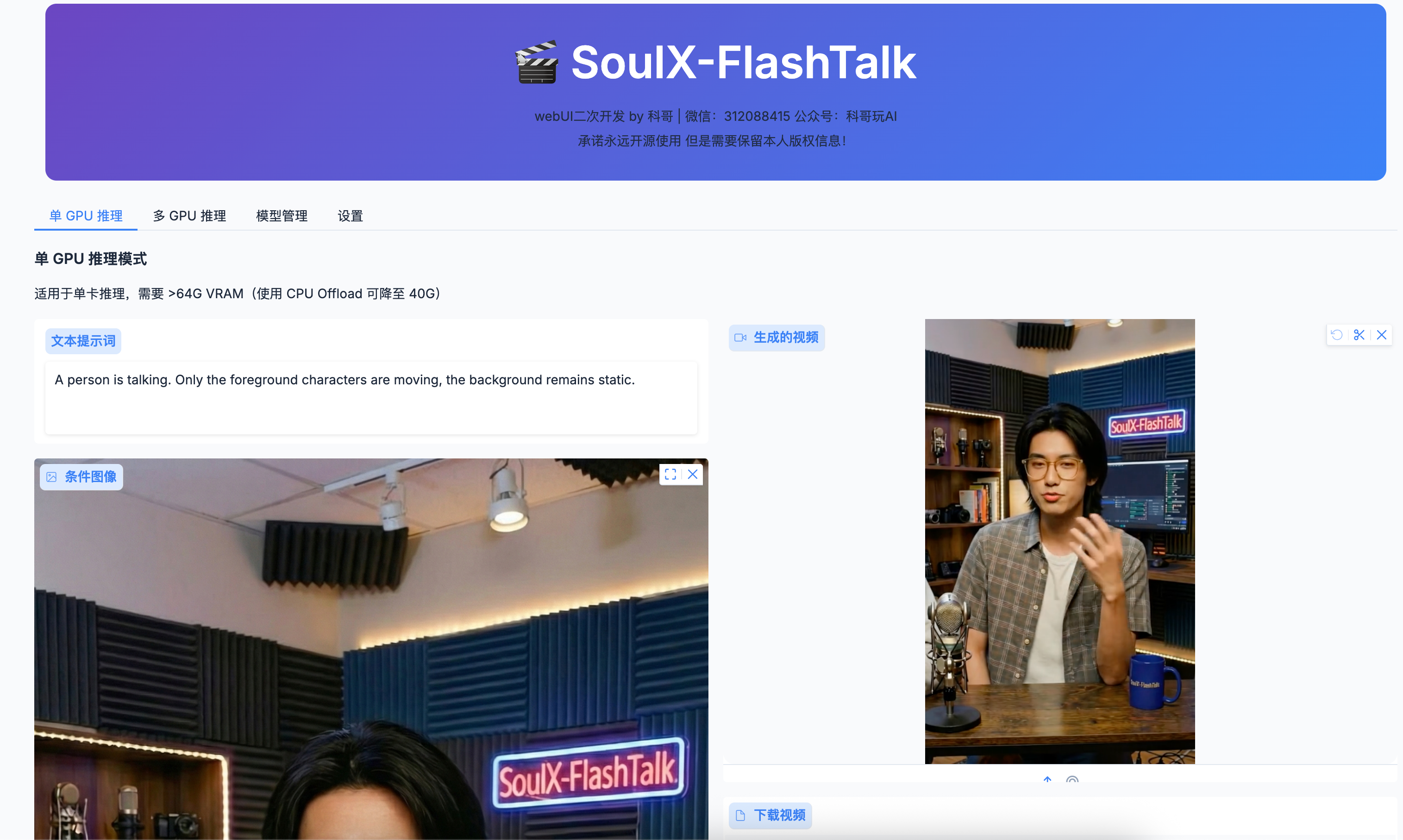
🎨 WebUI 使用指南
界面概览
WebUI 提供了 4 个主要功能标签页:
- 单 GPU 推理 - 适合单卡用户,支持 48GB 显存环境
- 多 GPU 推理 - 适合多卡用户,实现更快的推理速度
- 模型管理 - 下载和管理所需模型
- 设置 - 查看系统信息和调整推理参数
1. 单 GPU 推理(推荐新手使用)
步骤 1:准备输入素材
方式一:使用默认样例(最简单)
页面会自动加载默认样例:
- 图片:
man.png - 音频:
test.mp3
直接点击"🚀 开始生成"即可!
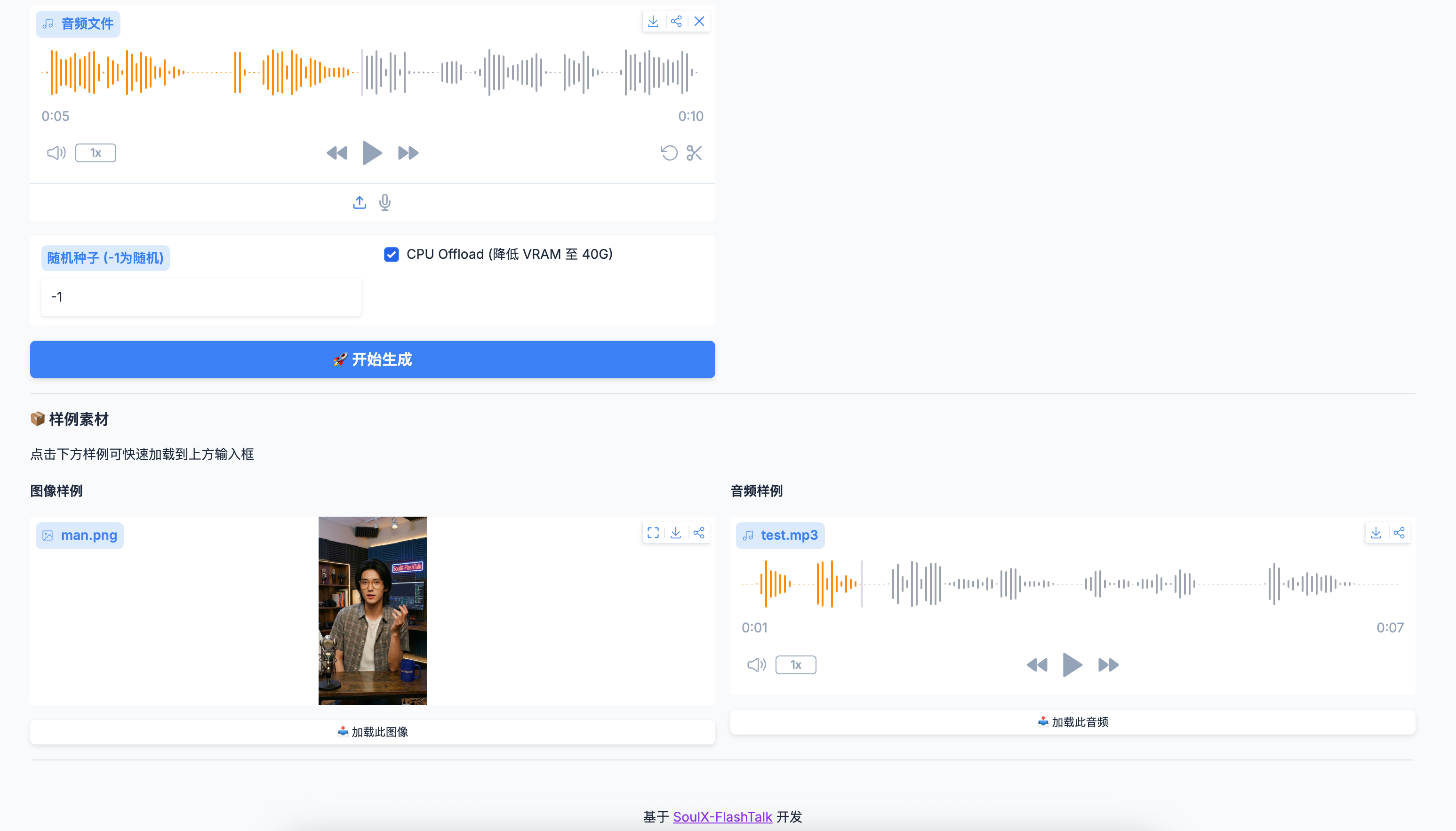
方式二:使用页面底部的样例预览
- 滚动到页面底部的"📦 样例素材"区域
- 查看图片和音频预览
- 点击"📥 加载此图像"或"📥 加载此音频"按钮
- 样例会自动加载到上方输入框
方式三:上传自己的素材
-
上传图片:
- 点击"条件图像"区域
- 选择一张人物正面照片
- 推荐:清晰的正面照,背景简单
-
上传音频:
- 点击"音频文件"区域
- 选择音频文件(支持 WAV、MP3 等格式)
- 音频会自动转换为 16kHz 采样率
步骤 2:配置参数
文本提示词(可选修改):
A person is talking. Only the foreground characters are moving, the background remains static.
- 描述视频生成的风格和要求
- 默认值已经很好,通常不需要修改
随机种子:
- 默认值:
-1(随机生成) - 如果想要可复现的结果,可以设置固定数字(如
9999)
CPU Offload:
- 默认:✅ 已勾选
- 适用于 48GB 显存环境
- 如果显存 >64GB,可以取消勾选以获得更快速度
步骤 3:开始生成
- 点击"🚀 开始生成"按钮
- 等待推理完成(进度条会显示当前状态)
- 短音频(6秒):约 10 分钟
- 长音频(37秒):约 15 分钟
- 生成完成后,视频会自动显示在右侧
- 点击"下载视频"按钮保存到本地
生成时间参考
| 音频时长 | 预计生成时间 | 显存使用 |
|---|---|---|
| 6-10秒 | 10-12分钟 | 30-40GB |
| 30-40秒 | 15-20分钟 | 30-40GB |
| 60秒以上 | 25-30分钟 | 30-40GB |
2. 多 GPU 推理(高级用户)
适用于拥有多张 GPU 的用户,可以显著加快推理速度。
使用步骤
- 切换到"多 GPU 推理"标签页
- 输入 GPU ID 列表(如:
0,1,2,3) - 上传图片和音频(同单 GPU 模式)
- 配置参数
- 点击"🚀 开始生成"
注意事项
- 需要 8 张 H800 或更高配置才能实现实时推理
- 多卡推理会显示实时日志
- 推理完成后会自动显示输出视频
3. 模型管理
首次使用必须下载模型
- 切换到"模型管理"标签页
- 查看模型状态:
- ✅ 绿色:已下载
- ❌ 红色:未下载
- 点击"下载模型"按钮
- 等待下载完成(约 10-20 分钟,取决于网速)
模型信息
SoulX-FlashTalk-14B
- 大小:约 28GB
- 用途:主要生成模型
- 路径:
models/SoulX-FlashTalk-14B/
chinese-wav2vec2-base
- 大小:约 1.2GB
- 用途:音频特征提取
- 路径:
models/chinese-wav2vec2-base/
4. 设置页面
查看系统信息和调整推理参数。
系统信息
- Python 版本
- PyTorch 版本
- CUDA 版本
- GPU 列表和显存信息
- 模型路径状态
推理参数(高级)
可以调整以下参数(仅会话级生效):
- 帧数(frame_num):默认 33
- 目标帧率(fps):默认 25
- 采样步数(steps):默认 4
- 分辨率:默认 768x448
⚠️ 注意:修改这些参数可能影响生成质量,建议保持默认值。
💻 命令行使用
单 GPU 推理
python generate_video.py \
--ckpt_dir models/SoulX-FlashTalk-14B \
--wav2vec_dir models/chinese-wav2vec2-base \
--input_prompt "A person is talking. Only the foreground characters are moving, the background remains static." \
--cond_image examples/man.png \
--audio_path examples/test.mp3 \
--audio_encode_mode stream \
--cpu_offload
多 GPU 推理
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 torchrun --nproc_per_node=8 generate_video.py \
--ckpt_dir models/SoulX-FlashTalk-14B \
--wav2vec_dir models/chinese-wav2vec2-base \
--input_prompt "A person is talking..." \
--cond_image examples/man.png \
--audio_path examples/test.mp3 \
--audio_encode_mode stream
输出位置
生成的视频保存在:
- WebUI:
outputs/outputs_YYYYMMDDHHMMSS.mp4 - 命令行:
sample_results/res_YYYYMMDD-HH:MM:SS-XXX.mp4
❓ 常见问题
Q1: WebUI 启动失败,提示端口被占用
解决方案:
# 方法1:使用启动脚本(会自动释放端口)
bash start_app.sh
# 方法2:手动释放端口
lsof -ti:7860 | xargs kill -9
Q2: 推理时显存不足(OOM)
解决方案:
- 确保勾选了"CPU Offload"选项
- 关闭其他占用显存的程序
- 使用更短的音频进行测试
显存需求:
- 不使用 CPU Offload:>64GB
- 使用 CPU Offload:40-48GB
Q3: 生成的视频没有声音
原因:音频合并失败
解决方案:
- 检查 FFmpeg 是否正确安装:
ffmpeg -version - 确保音频文件格式正确(推荐 WAV 或 MP3)
- 查看日志中的错误信息
Q4: 模型下载速度很慢
解决方案:
# 使用国内镜像
export HF_ENDPOINT=https://hf-mirror.com
# 然后重新下载
huggingface-cli download Soul-AILab/SoulX-FlashTalk-14B --local-dir ./models/SoulX-FlashTalk-14B
Q5: 推理卡住不动
排查步骤:
- 检查 GPU 利用率:
nvidia-smi - 查看日志输出
- 确认模型是否完整下载
- 重启 WebUI
Q6: 生成的视频质量不好
优化建议:
- 使用高质量的输入图片(清晰、正面、光线充足)
- 使用清晰的音频文件
- 尝试调整随机种子
- 确保使用了正确的文本提示词
📊 参数说明
核心参数
| 参数 | 说明 | 默认值 | 推荐值 |
|---|---|---|---|
input_prompt | 文本提示词 | "A person is talking..." | 保持默认 |
cond_image | 条件图像路径 | - | 清晰正面照 |
audio_path | 音频文件路径 | - | 16kHz WAV/MP3 |
seed | 随机种子 | -1(随机) | -1 或固定值 |
cpu_offload | CPU 卸载 | True | True(48GB显存) |
audio_encode_mode | 音频编码模式 | stream | stream |
高级参数
| 参数 | 说明 | 默认值 | 范围 |
|---|---|---|---|
frame_num | 每次生成帧数 | 33 | 20-50 |
tgt_fps | 目标帧率 | 25 | 24-30 |
sample_steps | 采样步数 | 4 | 4-8 |
height | 输出高度 | 768 | 512-1024 |
width | 输出宽度 | 448 | 384-768 |
⚠️ 注意:修改高级参数可能影响生成质量和速度,建议保持默认值。
🎯 最佳实践
输入素材准备
图片要求:
- ✅ 清晰的正面照
- ✅ 光线充足
- ✅ 背景简单
- ✅ 人物居中
- ❌ 避免侧脸或低头
- ❌ 避免复杂背景
- ❌ 避免模糊照片
音频要求:
- ✅ 清晰的人声
- ✅ 16kHz 采样率(会自动转换)
- ✅ 单声道或立体声均可
- ❌ 避免背景噪音过大
- ❌ 避免音量过小
推理优化
-
首次使用:
- 使用默认样例测试
- 确认环境配置正确
- 熟悉生成流程
-
正式使用:
- 准备高质量素材
- 使用合适的随机种子
- 监控显存使用
-
批量生成:
- 使用命令行脚本
- 避免同时运行多个任务
- 定期清理输出目录
📞 获取帮助
如遇到问题,可以:
- 查看本手册的"常见问题"部分
- 查看项目的
CLAUDE.md文档 - 查看
todo.md了解已知问题 - 提交 GitHub Issue
📝 更新日志
2026-03-03
- ✅ 添加样例预览功能
- ✅ 优化默认参数(随机种子、CPU Offload)
- ✅ 改进用户体验
2026-03-02
- ✅ 完善 WebUI 功能
- ✅ 添加模型管理页面
- ✅ 优化启动脚本
祝您使用愉快! 🎉
@鸡你太美 认证作者
认证作者
认证作者
镜像信息
已使用13 次
运行时长
31 H
 支持自启动
支持自启动镜像大小
100GB
最后更新时间
2026-05-09
支持卡型
48G RTX40系A800H20A100RTX40系3090
+6
框架版本
CUDA版本
12.8
应用
JupyterLab: 8888
版本
v1.0
2026-05-09