MSST-更多模型
本镜像参考了[原MSST镜像作者大大bilibili@爱过_留过]老师的模型启动方法,添加了常用的分离伴奏、人声、和声、混响、降噪等模型
 16
160元/小时
v2.0
MSST-多模型部署使用教程
本镜像基于MSST云端使用教程,参考了原MSST镜像作者大大bilibili@爱过_留过老师的模型启动方法,添加了常用的分离伴奏、人声、和声、混响、降噪等模型,以及常用模型介绍
有任何疑问可以关注B站我就是五字, 我喜欢你们!
镜像作者教学视频
### Warning:请自行解决数据集授权问题,禁止使用非授权数据集进行训练!任何由于使用非授权数据集进行训练造成的问题,需自行承担全部责任和后果!与仓库、仓库维护者、MSST develop team 、镜像作者无关!本项目是基于学术交流目的建立,仅供交流与学习使用,并非为生产环境准备。
由输入源造成的侵权问题需自行承担全部责任和一切后果。使用其他商用歌声合成软件作为输入源时,请确保遵守该软件的使用条例,注意,许多歌声合成引擎使用条例中明确指明不可用于输入源进行转换!
禁止使用该项目从事违法行为与宗教、政治等活动,该项目维护者、镜像制作者坚决抵制上述行为,不同意此条则禁止使用该项目。
继续使用视为已同意上述条款
所有由使用者非法使用所产生的任何后果,均与镜像制作者,项目维护着,开发者 无任何关系
使用教程:启动webUI(推荐使用机器公网ip+7860访问)
创建实例后进入jupyter lab,进入root目录,选择quick_setup文件并运行,出现url地址后运行成功
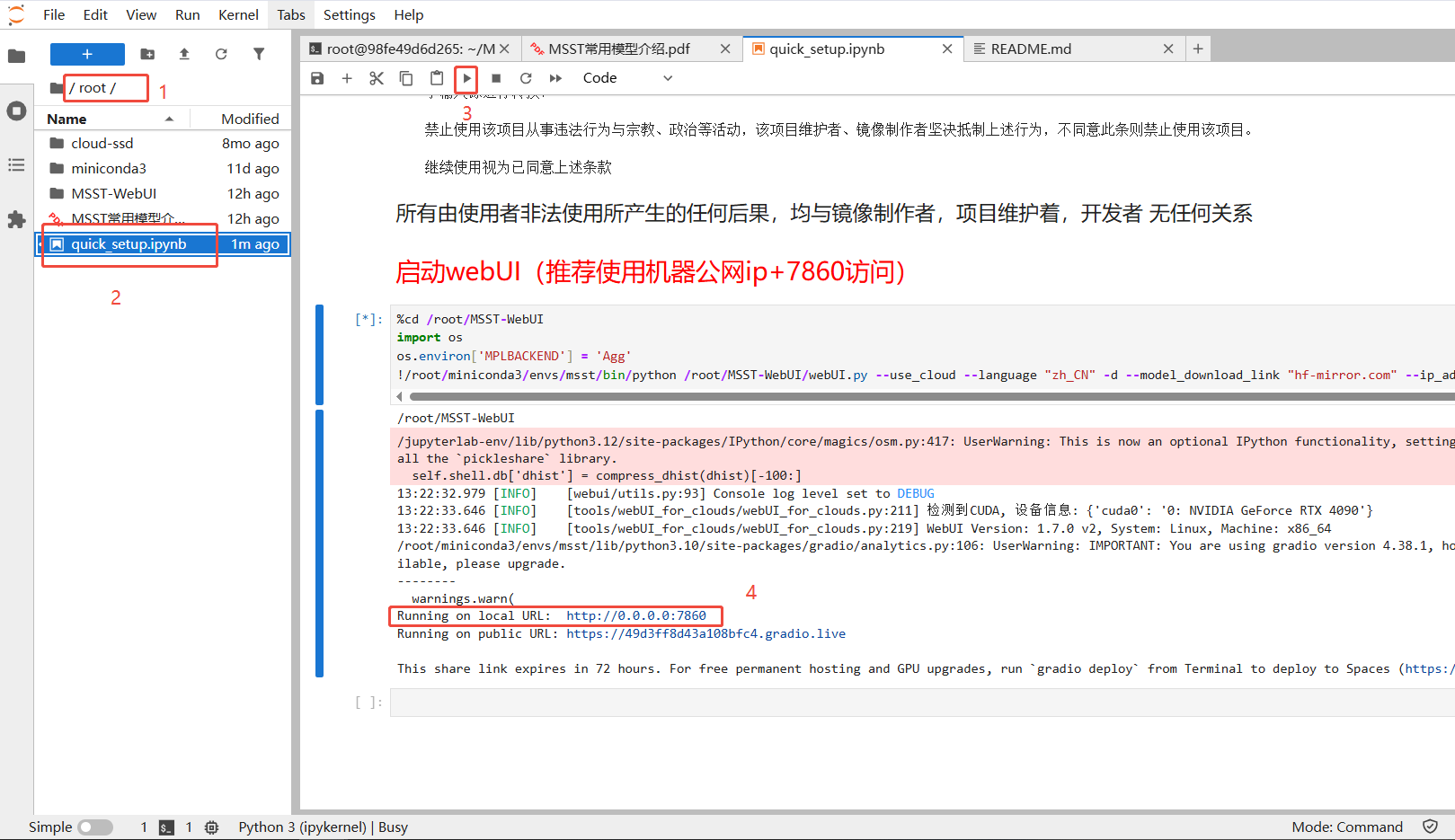
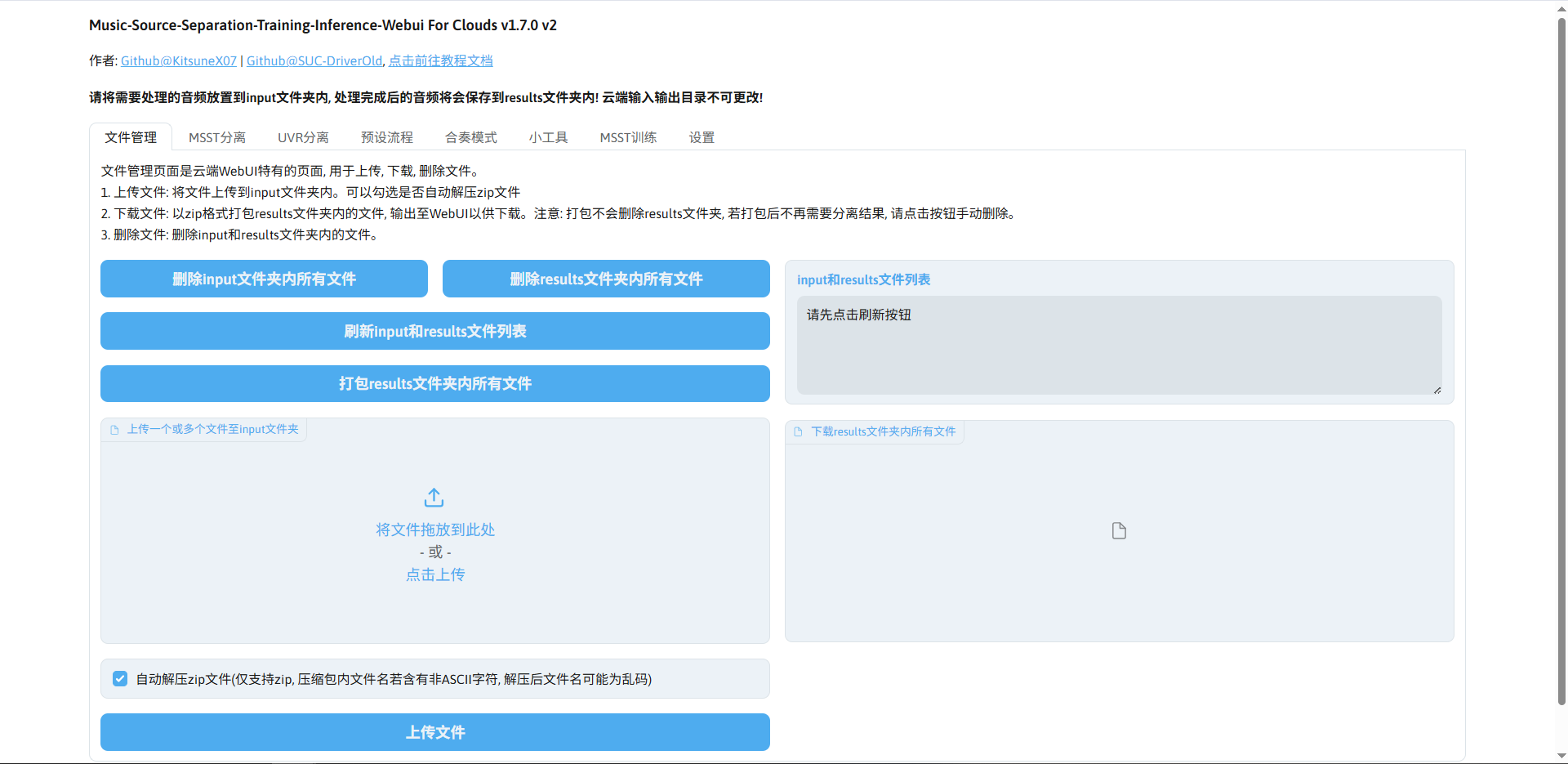
本地浏览器访问公网ip:7860
@我就是五字 认证作者
认证作者
认证作者
镜像信息
已使用475 次
运行时长
1134 H
镜像大小
70GB
最后更新时间
2025-09-05
支持卡型
RTX40系20803080Ti309048G RTX40系2080TiH20A800P40A100RTX50系V100SV100S
+13
框架版本
CUDA版本
12.4
应用
JupyterLab: 8888
版本
v2.0
2025-09-05