 1
1微软开源VibeVoice ASR TTS集合webui语音到文本 文本到语音模型 二次卡发构建by科哥
镜像简介
本镜像基于微软开源的VibeVoice模型,集成了ASR语音识别与TTS语音合成功能,并配备了友好的WebUI界面。用户可通过该工具实现语音到文本的精准转换,以及高质量文本到语音的生成。适用于语音助手开发、多语种内容创作、无障碍服务及语音交互系统等场景,提供高效、便捷的一站式语音AI解决方案。
镜像使用教程
创建实例后点击【SD-WebUI】即可进入操作页面
运行截图
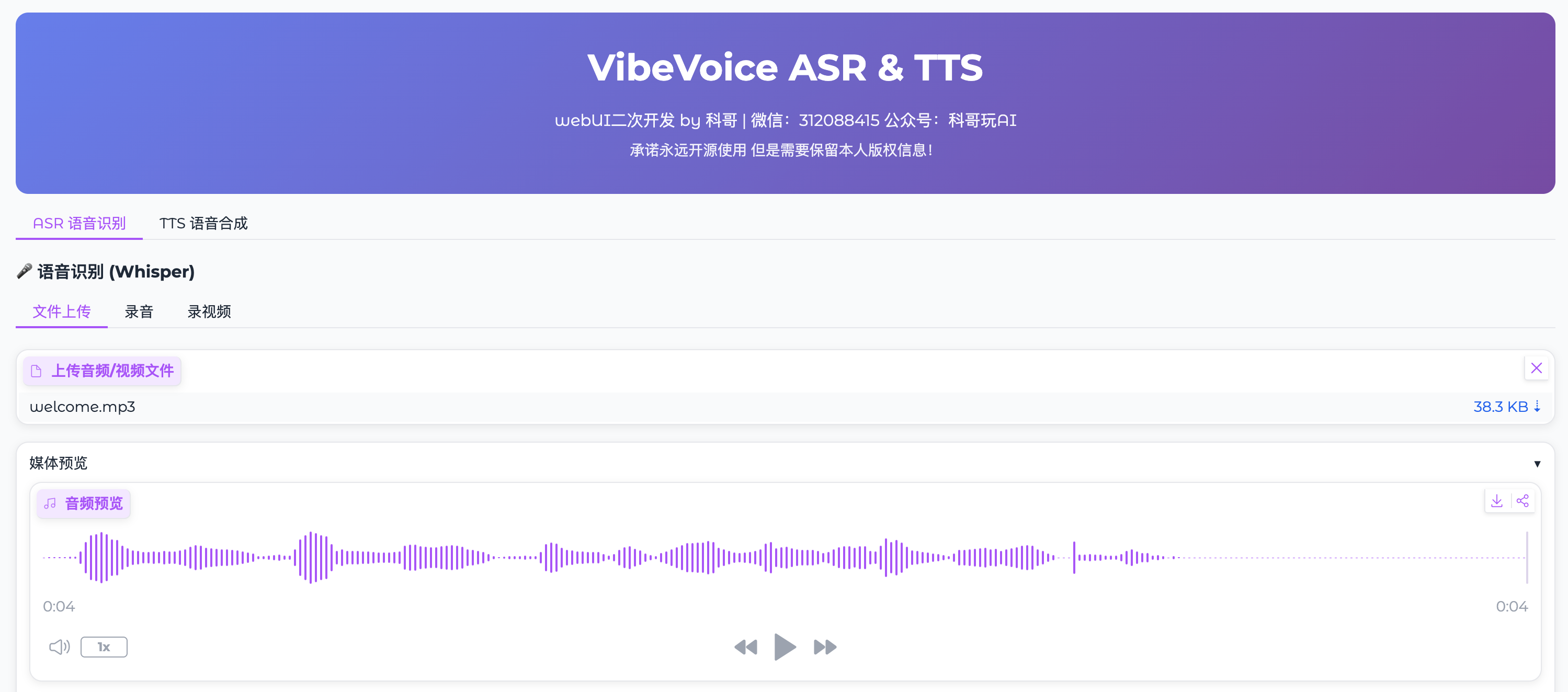
VibeVoice ASR & TTS 用户使用手册
系统简介
VibeVoice ASR & TTS 是一个集成了语音识别(ASR)和语音合成(TTS)功能的 WebUI 系统。
核心功能:
- 🎤 语音识别: 将音频转换为文字(支持中英文)
- 🔊 语音合成: 将文字转换为语音(支持多语言)
访问地址: http://localhost:7860
快速开始
启动系统
./start_app.sh
启动后,在浏览器中访问 http://localhost:7860
语音识别(ASR)使用指南
1. 上传音频
系统支持三种方式提供音频:
方式一:文件上传
- 点击 "文件上传" 标签
- 点击上传区域选择音频文件
- 支持格式:WAV, MP3, FLAC, M4A, MP4(视频)
方式二:录音
- 点击 "录音" 标签
- 点击麦克风图标开始录音
- 再次点击停止录音
方式三:录视频
- 点击 "录视频" 标签
- 允许浏览器访问摄像头和麦克风
- 点击录制按钮开始录制
- 系统会从视频中提取音频进行识别
2. 预览音频
上传或录制完成后,音频会自动显示在 "媒体预览" 区域:
- 可以播放预览音频
- 可以调整播放进度
- 确认音频正确后再进行识别
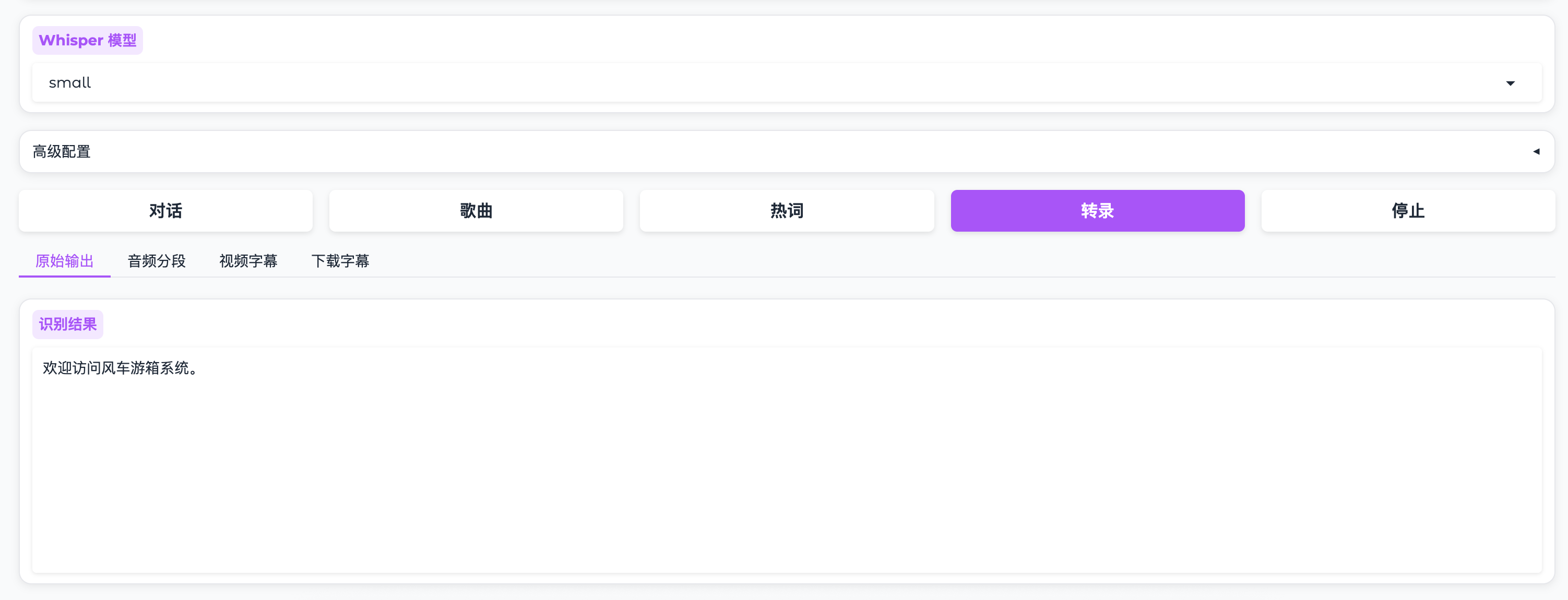
3. 选择模型
在 "Whisper 模型" 下拉框中选择识别模型:
| 模型 | 特点 | 推荐场景 |
|---|---|---|
| base | 轻量快速 | 快速测试、实时识别 |
| small | 平衡性能 | 日常使用(推荐) |
💡 提示: 下拉框只显示已下载的模型。如需使用其他模型,请先下载。
4. 高级配置(可选)
点击 "高级配置" 展开更多选项:
- 最大生成令牌数: 控制识别长度(默认 224,范围 1-400)
- 自定义上下文(热词): 输入专业术语,用逗号分隔
- 启用采样: 开启后可调整温度和 Top-p 参数
- 温度: 控制输出随机性(0-1,默认 0.7)
- Top-p 采样: 控制输出多样性(0-1,默认 0.9)
⚠️ 注意: 一般情况下使用默认设置即可,无需调整高级参数。
5. 开始识别
点击 "转录" 按钮开始识别。
识别过程中会显示进度,完成后结果会显示在输出区域。
6. 查看结果
系统提供四种输出方式:
原始输出
- 显示识别的文字内容
- 自动按句分行,方便阅读
- 可以直接复制文本
音频分段
- 显示带时间戳的分段结果
- 点击时间按钮可跳转到对应位置播放
- 适合查看详细的识别过程
视频字幕
- 如果上传的是视频,会显示带字幕的视频播放器
- 字幕会自动同步显示
下载字幕
- 下载 SRT 格式的字幕文件
- 可用于视频编辑软件
识别技巧
✅ 提升识别准确率的建议:
- 使用清晰的音频,避免背景噪音
- 音频音量适中,不要过大或过小
- 如有专业术语,在"自定义上下文"中添加
- 对于重要内容,建议使用 small 模型
语音合成(TTS)使用指南
1. 选择模型
在 "选择模型" 下拉框中选择 TTS 模型:
| 模型 | 特点 |
|---|---|
| 0.5B (Realtime) | 实时合成,速度快(推荐) |
2. 输入文本
在 "输入文本" 框中输入要合成的文字:
- 支持中文和英文
- 支持混合输入
- 建议每次输入不超过 200 字
示例文本:
你好,这是一段测试文本。
Hello, this is a test.
3. 声音克隆(开发中)
"声音克隆(可选)" 功能目前处于开发中状态:
- 该功能需要标准 VibeVoiceProcessor 支持
- 当前版本暂不可用
- 请使用系统预设的 voice presets
4. 开始合成
点击 "开始合成" 按钮。
合成过程:
- 系统加载模型(首次使用需要等待)
- 处理文本并生成音频
- 显示合成进度
- 完成后自动播放
5. 播放和下载
合成完成后:
- 播放: 点击播放按钮试听
- 下载: 点击下载按钮保存音频文件
- 格式: WAV 格式,24kHz 采样率
6. 查看状态
"状态" 区域会显示:
- 合成成功提示
- 文件保存路径
- 错误信息(如有)
合成技巧
✅ 获得更好音质的建议:
- 文本使用标准标点符号
- 避免过长的句子,适当分段
- 数字建议用中文表示(如"一百"而不是"100")
- 英文单词会自动识别并正确发音
常见问题
Q1: 识别结果不准确怎么办?
解决方法:
- 检查音频质量,确保清晰无噪音
- 尝试使用 small 模型
- 在"自定义上下文"中添加专业术语
- 如果是方言,识别效果可能不佳
Q2: 合成的语音听起来不自然?
解决方法:
- 检查文本标点符号是否正确
- 避免过长的句子
- 当前版本使用的是 0.5B 模型,音质已经较好
- 如需更高质量,可等待后续版本支持更大模型
Q3: 上传音频后一直 loading?
可能原因:
- 音频文件过大(建议小于 100MB)
- 网络连接问题
- 浏览器兼容性问题
解决方法:
- 尝试压缩音频文件
- 刷新页面重试
- 使用 Chrome 或 Firefox 浏览器
Q4: 选择模型后无响应?
可能原因:
- 选择的模型未下载
解决方法:
- 只选择下拉框中显示的模型
- 下拉框会自动过滤未下载的模型
Q5: 如何处理长音频?
建议方法:
- 将长音频分段处理
- 每段建议不超过 10 分钟
- 使用音频编辑软件(如 Audacity)分割音频
Q6: 支持哪些语言?
ASR(语音识别):
- 主要支持:中文、英文
- 其他语言识别效果可能不佳
TTS(语音合成):
- 支持:中文、英文
- 自动识别语言并使用对应发音
使用场景
场景一:会议记录
- 录制会议音频
- 上传到 ASR 进行识别
- 下载 SRT 字幕文件
- 整理成会议纪要
场景二:视频字幕制作
- 上传视频文件
- 使用 ASR 识别生成字幕
- 下载 SRT 文件
- 导入视频编辑软件
场景三:有声读物制作
- 准备文本内容
- 使用 TTS 合成语音
- 下载音频文件
- 制作成有声读物
场景四:语音备忘录
- 使用录音功能记录想法
- 立即识别为文字
- 保存或分享文字内容
性能参考
识别速度
- base 模型: 1 分钟音频约需 10-20 秒
- small 模型: 1 分钟音频约需 20-30 秒
合成速度
- 短文本(10 字): 约 3 秒
- 中等文本(50 字): 约 10 秒
- 长文本(200 字): 约 30 秒
文件大小
- 识别音频: 建议小于 100MB
- 合成文本: 建议每次不超过 200 字
- 输出音频: 约 1MB/分钟(24kHz WAV)
快捷操作
键盘快捷键
浏览器标准快捷键:
Ctrl + C: 复制识别结果Ctrl + V: 粘贴文本到输入框Space: 播放/暂停音频
批量处理建议
如需处理多个文件:
- 逐个上传处理
- 每次处理完成后复制结果
- 汇总到文档中
💡 提示: 未来版本可能支持批量处理功能。
注意事项
隐私和安全
⚠️ 重要提示:
- 所有处理都在本地服务器进行
- 音频和文本不会上传到外部服务器
- 生成的文件保存在
outputs/目录 - 建议定期清理输出文件
使用限制
- 仅供研究使用: VibeVoice 目前仅用于研究目的
- AI 生成声明: TTS 生成的音频包含 AI 生成声明
- 音频水印: 生成的音频包含不可感知的水印
- 版权: 请遵守相关法律法规,不要用于非法用途
系统要求
推荐配置:
- CPU: 4 核心以上
- 内存: 8GB 以上
- GPU: NVIDIA GPU(可选,显著提升速度)
- 显存: 4GB 以上(使用 GPU 时)
- 浏览器: Chrome, Firefox, Edge(最新版本)
技术支持
获取帮助
如遇到问题:
- 查看本使用手册
- 查看
README.md了解技术细节 - 查看
todo.md了解已知问题
反馈建议
欢迎提供使用反馈和改进建议。
版权信息
webUI 二次开发 by 科哥 | 微信:312088415 公众号:科哥玩AI
承诺永远开源使用,但需要保留版权信息!
文档版本: 1.0.0 最后更新: 2026-01-22
 认证作者
认证作者

 支持自启动
支持自启动