 6
6CosyVoice2-0.5B镜像使用教程
镜像简介
本镜像基于阿里云开源的轻量级语音模型CosyVoice2-0.5B,专注于高拟真的语音合成与音色克隆。用户可通过少量音频样本快速复刻目标音色,生成自然流畅的个性化语音。适用于虚拟助手配音、有声内容创作、语音交互开发等场景,提供高效、便捷且完全免费的本地化语音AI解决方案。
镜像由科哥构建 微信:312088415
使用教程
已经设置开机运行,默认使用:CosyVoice2-0.5B 1.创建实例
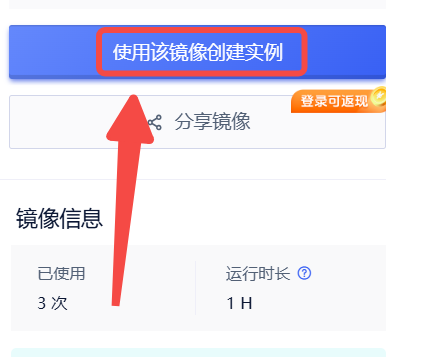
2.选择合适的机型,立即部署
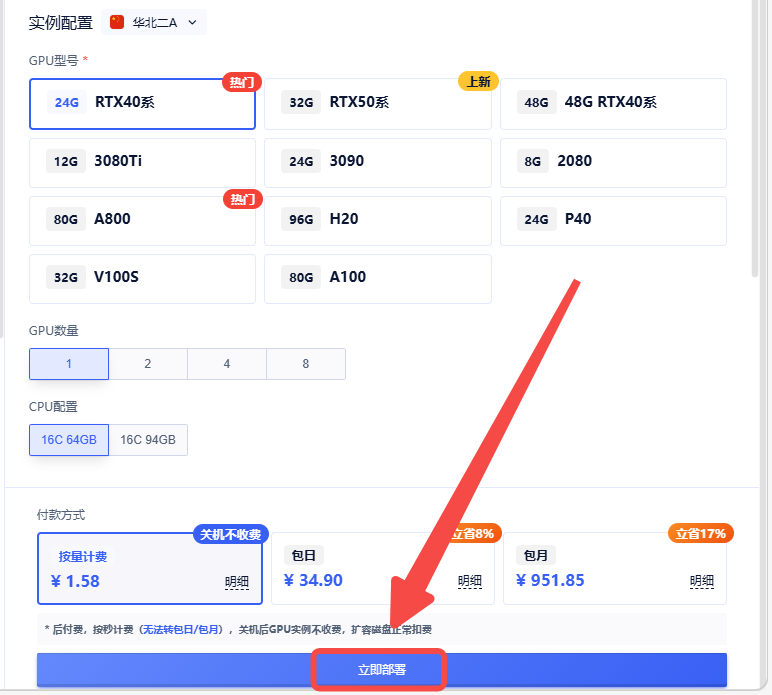 3.一切环境已经就绪,开机已经启动应用,等待1-2分钟即可打开webUI进入使用页面:
3.一切环境已经就绪,开机已经启动应用,等待1-2分钟即可打开webUI进入使用页面:
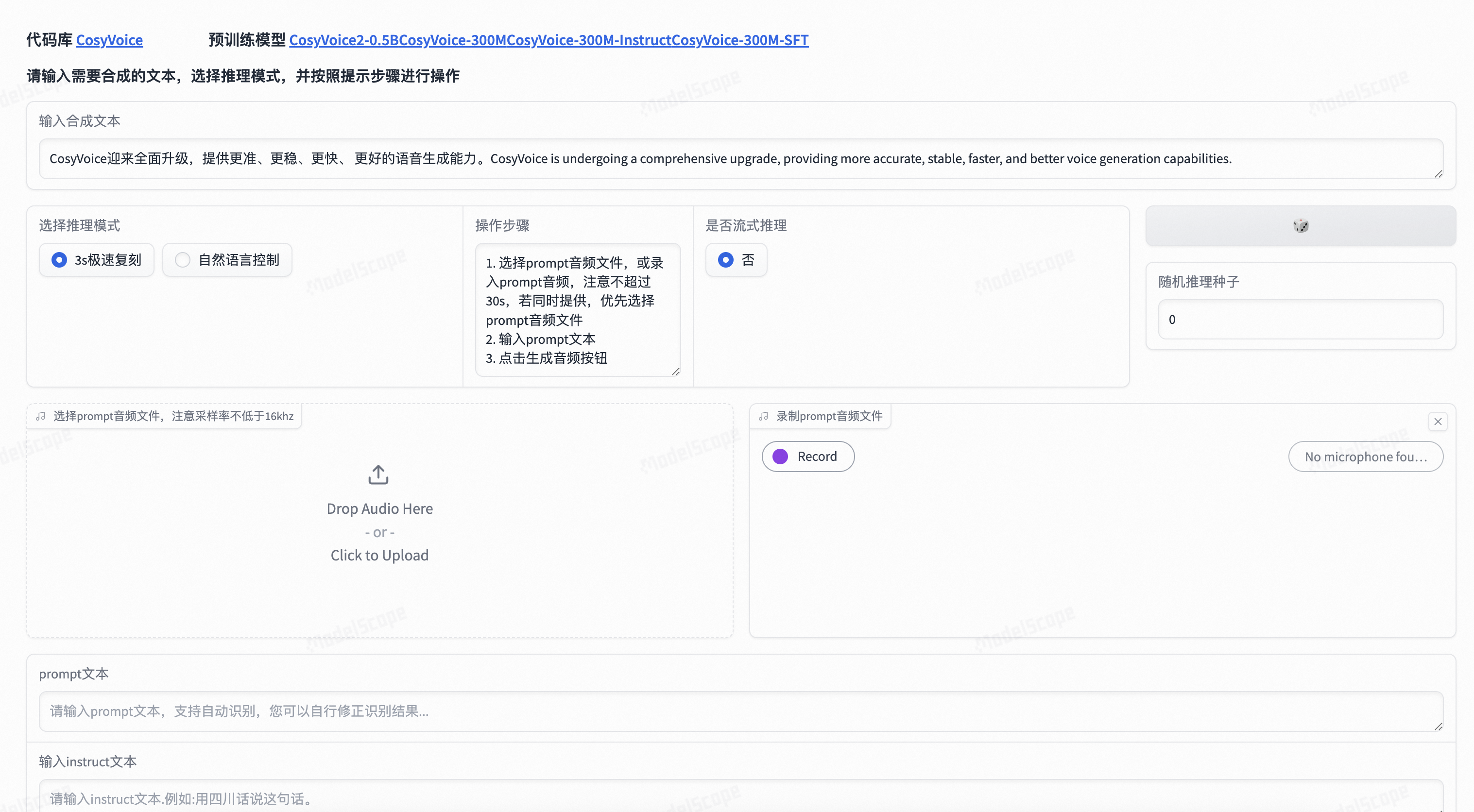
如果需要重启程序,进入jupyterlab,终端命令行中输入:
cd /root && run.sh
并回车,等待1-2分钟即可打开webUI进入使用页面.
如何更换不同的模型运行?
模型存放目录: /root/CosyVoice/pretrained_models
共四个模型:相关说明看:https://github.com/FunAudioLLM/CosyVoice/blob/main/README.md
CosyVoice-300M
CosyVoice-300M-Instruct
CosyVoice-300M-SFT
CosyVoice2-0.5B
需要运行其他模型:
手动修改 /root/run.sh文件的第10行这个参数:
--model_dir pretrained_models/CosyVoice2-0.5B
比如使用【CosyVoice-300M】这个模型:将 run.sh文件第10行修改成这样,然后再执行即可:
nohup bash -l -c 'source /root/miniconda3/etc/profile.d/conda.sh; conda activate cosyvoice; python webui.py --model_dir pretrained_models/CosyVoice-300M' > /root/logs.log 2>&1
官方更新源码在这里: https://github.com/FunAudioLLM/CosyVoice
使用视频及教程参考:B站搜索“F5-tts”相关视频教程
使用教程更新地址:https://kege-aigc.feishu.cn/docx/G5G1dcRUForkdnxhuQLcmsuknTb
有bug请微信科哥: 312088415 科哥目前在研究AI数字人直播卖货很成功,欢迎来了解一起玩: https://kege-aigc.feishu.cn/docx/G271dgZr1o8CvMx9KKrcRuuonDf
科哥在UCLoud的镜像列表【不断更新中】: https://kege-aigc.feishu.cn/docx/L3FVdQl7kom8Ckx7QiicQj2VnEd
免责声明 本项目仅用于学习、研究和技术交流目的。使用者必须遵守中华人民共和国相关法律法规,尊重他人知识产权和合法权益。
本项目基于 Apache 2.0 协议开源
关于项目中的音频素材:
项目中包含的示例音频仅用于技术测试和演示目的 音频素材的版权归原作者所有,不适用于本项目遵循的 Apache 2.0 协议 如果您是音频素材的版权所有者且不希望被使用,请联系我们删除 关于 AI 生成语音:
模型生成的语音内容可能存在版权风险 生成的语音可能被用于制作误导性内容 请谨慎使用和传播 AI 生成的语音内容 建议在使用生成的语音内容时注明其 AI 生成的属性 严禁将本项目用于以下用途:
任何违法违规行为 侵犯他人知识产权或其他合法权益 传播不良或有害信息 使用限制:
请勿用于制作违法违规内容 请勿用于制作虚假信息或误导性内容 使用本项目所产生的一切后果由使用者自行承担,项目开发者不承担任何法律责任
如果本项目有任何侵犯您权益的地方,请及时联系我们,我们将立即处理
使用本项目即表示您已阅读并同意以上声明
 认证作者
认证作者

 支持自启动
支持自启动