 7
7Qwen3.5-35B-A3B 高性能推理服务 (llama.cpp + RTX 5090)
镜像简介
本镜像提供了一个基于 llama.cpp 的高效推理服务,专为 Qwen3.5-35B-A3B 混合专家(MoE)模型优化,可在 NVIDIA RTX 5090 32GB 显卡上实现 160+ tokens/s 的极致生成速度。
- 功能: 一键启动 HTTP API 服务,支持多用户并发、长上下文(16k)和高吞吐量推理。
- 特点: 预编译 CUDA 加速版
llama-server,开启 Flash Attention,针对 MoE 架构优化批处理参数,充分利用 32GB 显存。
快速开始
注:已编译好llama.cpp(针对5090显卡),可以直接启动,其他显卡可参考自行编译,编译位置:
cd ~/llama-workspace/llama.cpp/build
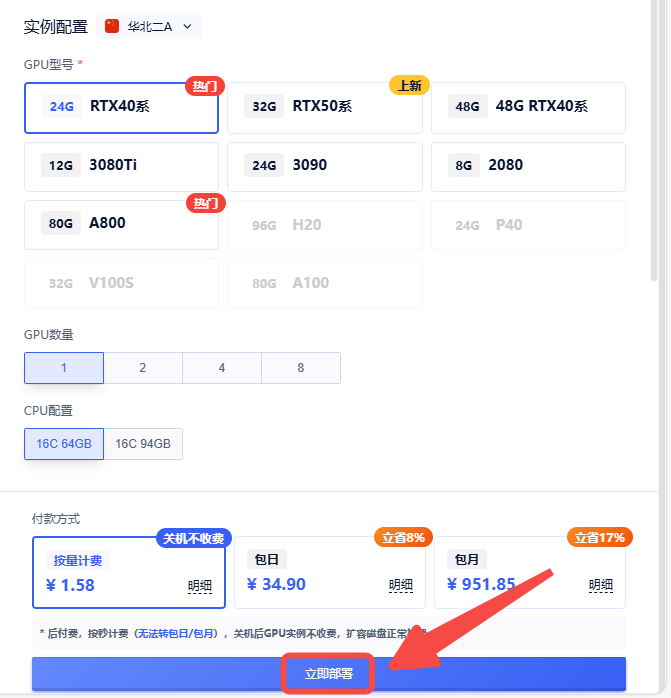
1.创建实例
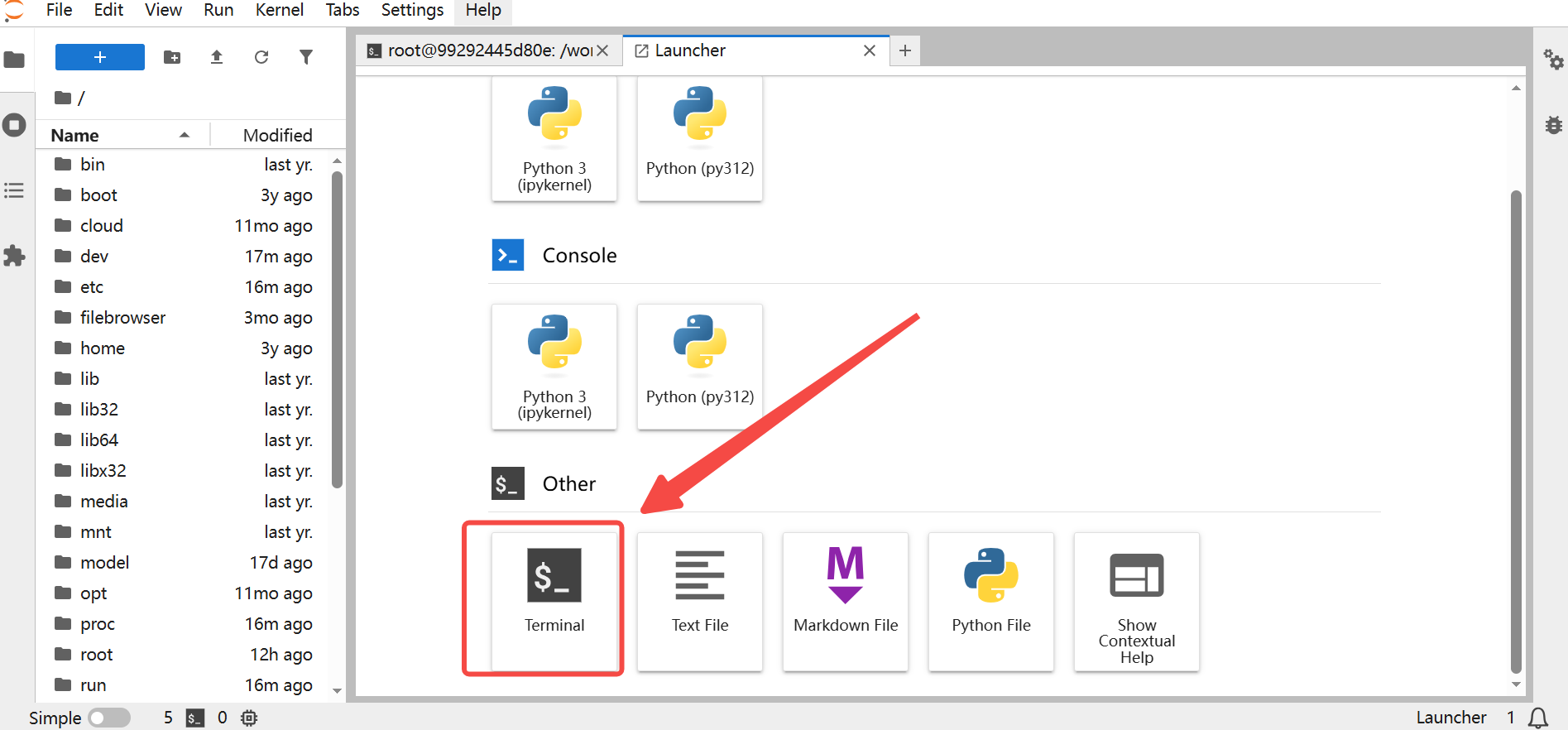
2.点击jupyerlab,进入终端,输入以下代码进入build目录
cd ~/llama-workspace/llama.cpp/build

3.在build目录下启动脚本:
./bin/llama-server -m ~/llama-workspace/models/Qwen3.5-35B-A3B-UD-Q4_K_M.gguf -ngl 999 -fa on -c 16384 -b 2048 -ub 512 -np 4 --temp 0.7 --port 8080 --host 0.0.0.0 --mlock
4.访问8080端口即可(开启防火墙),测试速度约160t/s
您的网络ip:8080
环境与依赖
本镜像构建和运行所需的基础环境。
- 框架及版本: llama.cpp (CUDA 加速版,commit b8183 或更新)
- CUDA版本: CUDA 12.2+ (推荐 12.4,支持 RTX 5090 Blackwell 架构)
- 其他依赖: Linux 系统 (Ubuntu 22.04 测试通过),NVIDIA 驱动程序 550+,
mlock权限(可选)
配置方法
-
下载模型文件
将 Qwen3.5-35B-A3B 的 Q4_K_M 量化版 GGUF 模型放置于工作目录(例如~/llama-workspace/models/):mkdir -p ~/llama-workspace/models # 假设模型已下载为 Qwen3.5-35B-A3B-UD-Q4_K_M.gguf # 若未下载,可从 Hugging Face 等渠道获取 -
获取 llama-server 可执行文件
从官方发布页下载预编译的 CUDA 版本,或自行编译:git clone https://github.com/ggerganov/llama.cpp cd llama.cpp mkdir build && cd build cmake .. -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES="native" cmake --build . --config Release -j $(nproc) cp bin/llama-server ~/llama-workspace/ -
启动服务
使用以下单行命令启动服务器(请根据实际路径调整模型位置):~/llama-workspace/llama-server -m ~/llama-workspace/models/Qwen3.5-35B-A3B-UD-Q4_K_M.gguf -ngl 999 -fa -c 16384 -b 2048 -ub 1024 -np 8 --temp 0.7 --port 8080 --host 0.0.0.0 --mlock
环境验证代码
服务启动后,在另一终端执行以下 curl 命令测试推理是否正常:
curl http://localhost:8080/completion \
-H "Content-Type: application/json" \
-d '{
"prompt": "Hello, how are you?",
"n_predict": 50,
"temperature": 0.7
}'
若返回包含生成的文本的 JSON 响应,则环境配置成功。
相关链接
- 项目源码: ggerganov/llama.cpp (GitHub)
- 模型来源: Qwen/Qwen2.5-35B-A3B-GGUF (Hugging Face)
- llama.cpp 编译指南: Build llama.cpp with CUDA
常见问题
Q1:启动后 GPU 占用为 0,推理速度极慢(10 tokens/s 左右)怎么办?
A1: 这通常是因为使用的 llama-server 未编译 CUDA 支持。请确认你下载或编译的是带有 CUDA 后端的版本(可执行 llama-server --help 查看是否包含 -ngl 选项)。重新按照“配置方法”第2步获取正确的 CUDA 版可执行文件即可。
Q2:显存不足或服务崩溃,如何调整并发数?
A2: 当前配置 -np 8 约占用 20GB 显存,若需降低并发可减少 -np 值(如 -np 4)。若显存仍有剩余,可尝试 -np 12,同时注意 KV 缓存量化(-ctk q8_0 -ctv q8_0)可进一步释放显存。
Q3:如何修改模型温度、上下文长度等参数?
A3: 直接在启动命令中修改对应的参数即可,例如 --temp 0.8,-c 32768。更多参数说明请参考 llama.cpp 文档。
