NovaSR一个开源的音频超分辨率模型低音质转高清音质声音修复模型 webui开发构建by科哥
NovaSR一个开源的音频超分辨率模型低音质转高清音质声音修复模型 webui开发构建by科哥
 0
00元/小时
v1.1
NovaSR一个开源的音频超分辨率模型低音质转高清音质声音修复模型 webui开发构建by科哥
镜像简介
本镜像基于开源的NovaSR音频超分辨率模型,专注于将低音质音频转为高清音质,支持人声增强与音频修复。内置直观的WebUI界面,方便用户一键上传并处理音频文件,适用于老旧录音修复、语音清晰化及音质提升等场景,操作简单,效果显著。
镜像使用教程
创建实例后点击【SD-WebUI】即可进入操作页面
运行截图
NovaSR WebUI 用户使用手册
快速开始
启动应用
在项目根目录执行:
./start_app.sh
启动成功后,浏览器访问: http://localhost:7860
使用步骤
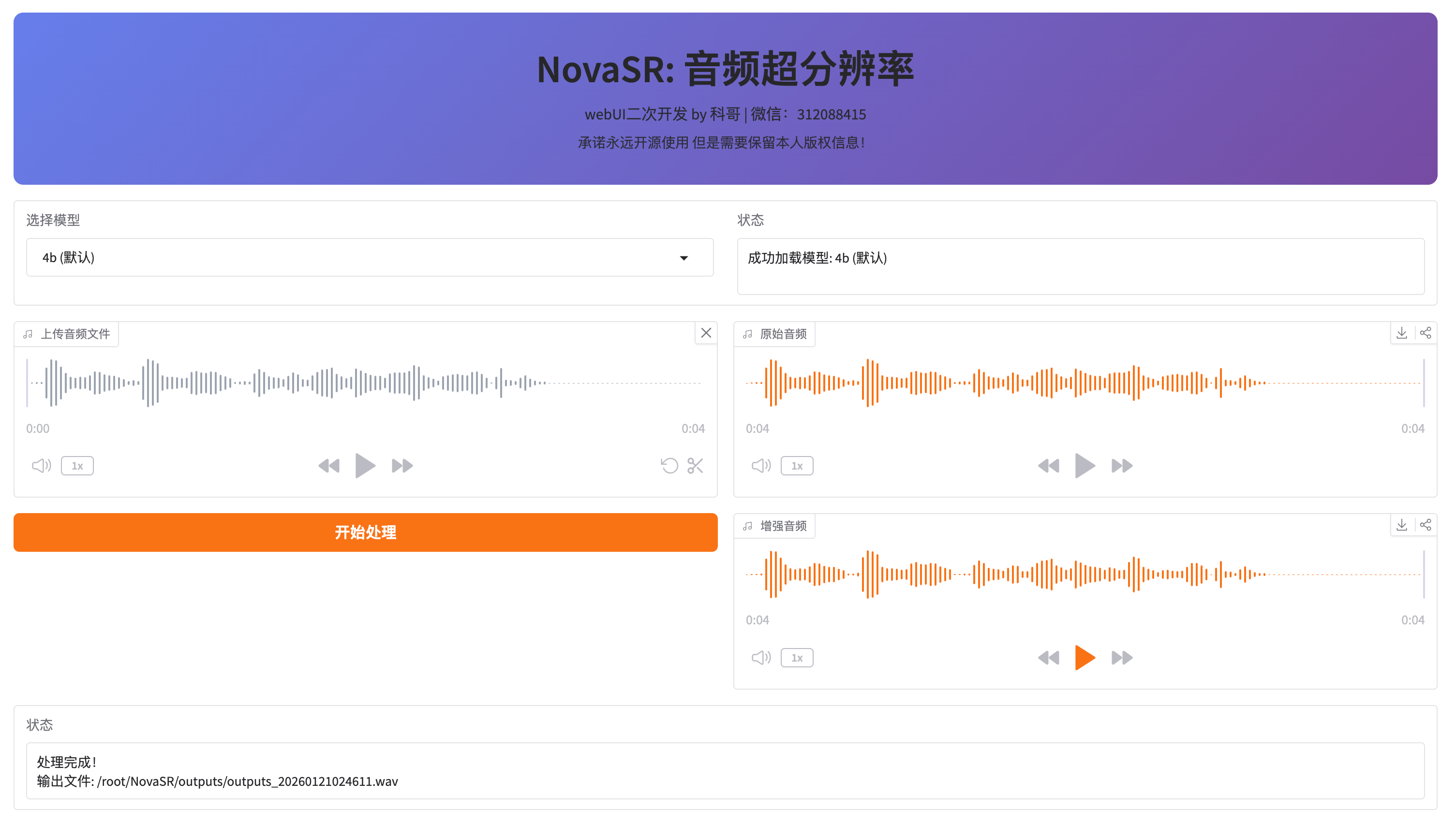
1. 上传音频文件
- 点击「上传音频文件」区域
- 选择要增强的音频文件 (支持
.wav和.mp3格式) - 上传后可以播放预览原始音频
2. 选择模型 (可选)
- 默认使用 4b (默认) 模型
- 如需切换模型,在「选择模型」下拉菜单中选择
- 切换后会显示加载状态
3. 开始处理
- 点击「开始处理」按钮
- 等待处理完成 (通常几秒钟)
- 处理完成后会显示状态信息
4. 查看结果
- 原始音频: 左侧播放器显示上传的原始音频
- 增强音频: 右侧播放器显示处理后的高清音频
- 可以对比播放,感受音质提升效果
5. 下载输出
- 点击增强音频播放器下方的下载按钮
- 或者在项目的
outputs/目录查看所有输出文件 - 文件命名格式:
outputs_YYYYMMDDHHMMSS.wav
功能说明
音频超分辨率
- 输入: 16kHz 或更低采样率的音频
- 输出: 48kHz 高采样率音频
- 效果: 提升音频清晰度和细节
模型切换
- 切换模型时会自动清理显存
- 首次加载模型需要几秒钟
- 后续使用同一模型无需重新加载
常见问题
Q: 支持哪些音频格式?
A: 支持 .wav 和 .mp3 格式
Q: 处理一个文件需要多久?
A: 通常几秒钟,具体取决于音频长度和硬件配置
Q: 输出文件保存在哪里?
A: 保存在项目根目录的 outputs/ 文件夹
Q: 如何停止应用?
A: 在终端按 Ctrl + C
Q: 端口被占用怎么办?
A: 启动脚本会自动检测并释放 7860 端口
技术参数
- 模型大小: 52KB
- 推理速度: 3600x realtime (A100)
- 输入采样率: 16kHz
- 输出采样率: 48kHz
- 默认端口: 7860
版权信息
webUI二次开发 by 科哥 | 微信:312088415
承诺永远开源使用 但是需要保留本人版权信息!
bug反馈可以加入科哥专属群交流➕ 广告勿进!

科哥在UCloud镜像列表【不断更新中】:
@鸡你太美 认证作者
认证作者
认证作者
镜像信息
已使用11 次
运行时长
3 H
 支持自启动
支持自启动镜像大小
30GB
最后更新时间
2026-04-27
支持卡型
3080TiRTX40系RTX50系48G RTX40系2080Ti30902080A800H20P40V100SA100
+12
框架版本
CUDA版本
12.8
应用
JupyterLab: 8888
版本
v1.1
2026-04-27