AI动漫配音—VoxCPM2一键语音克隆、配音、训练、支持LoRA
VoxCPM2支持AI动漫配音等多种应用场景,一键语音克隆、配音、训练、支持LoRA
 27
270元/小时
v2.0
v1.0
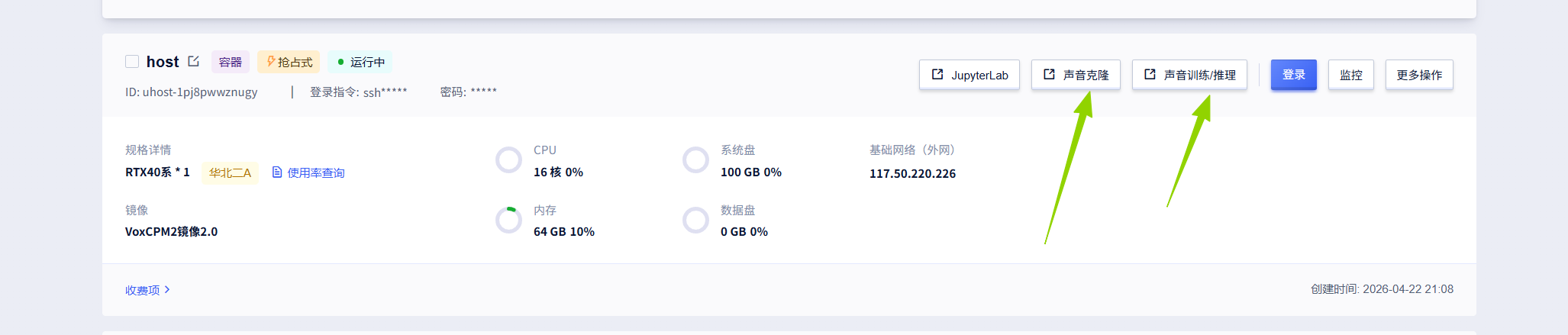
一键部署后等加载2-3分钟左右点击如图按钮打开页面使用【声音克隆 | 声音训练/推理】:
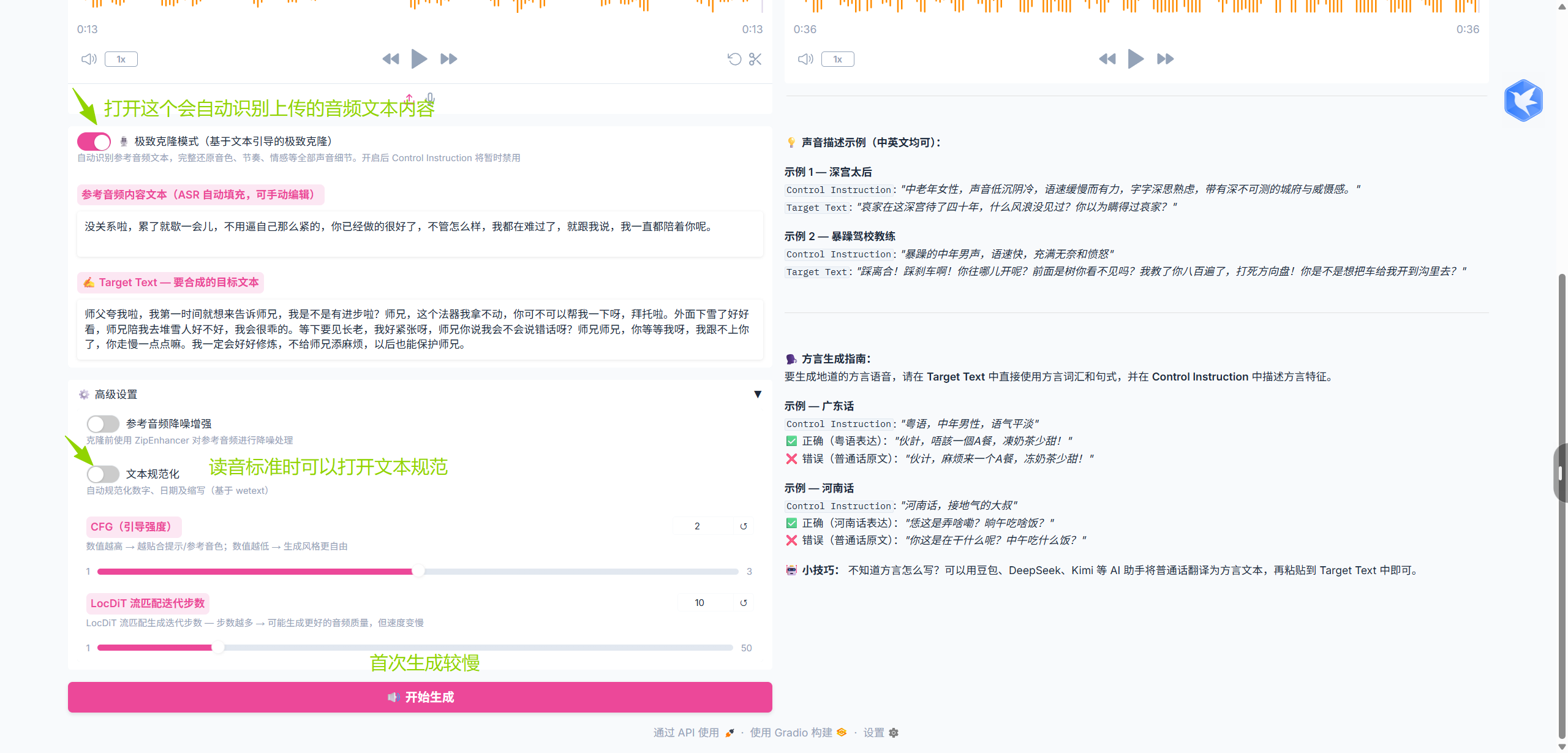
打开声音克隆后页面如下:
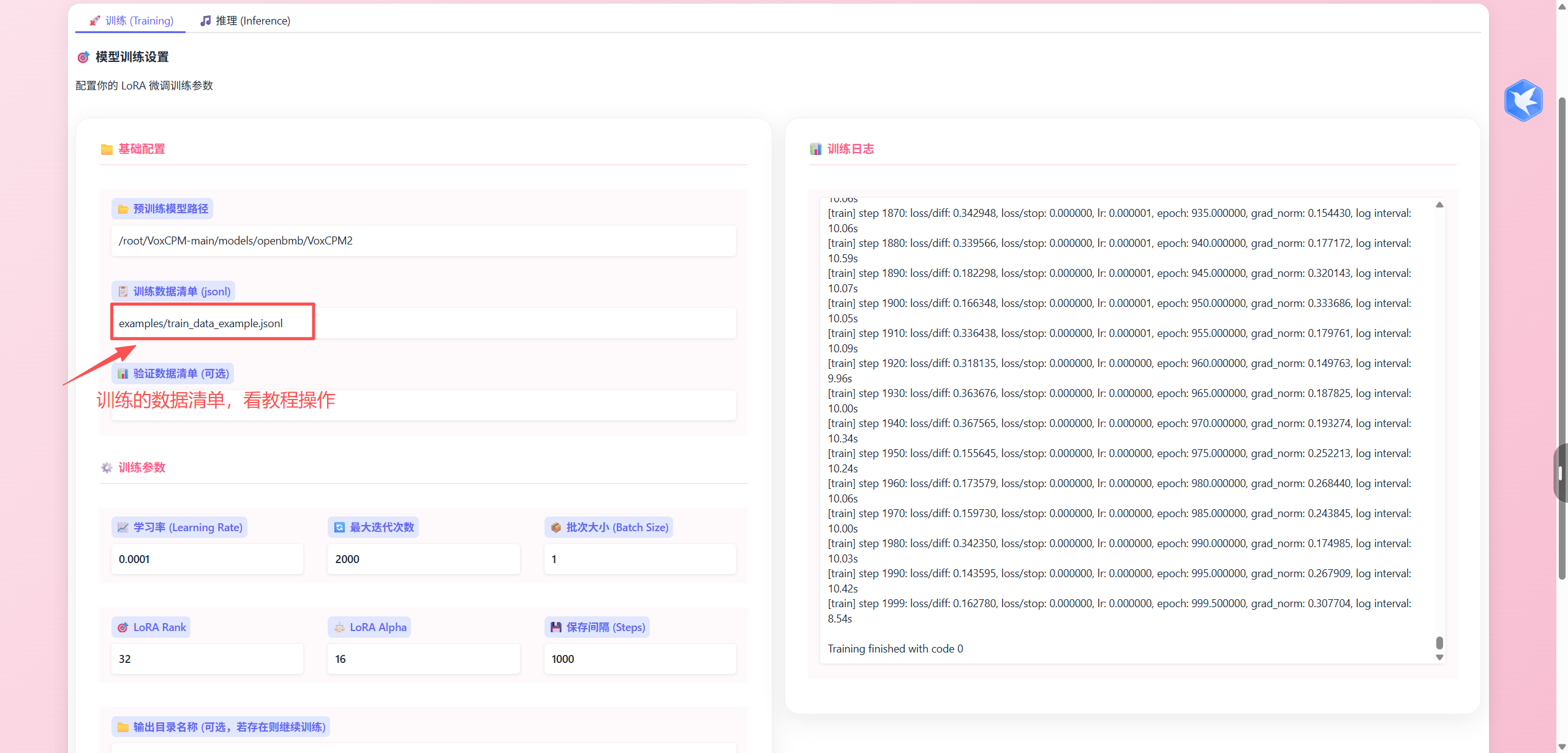
声音训练/推理:
训练:
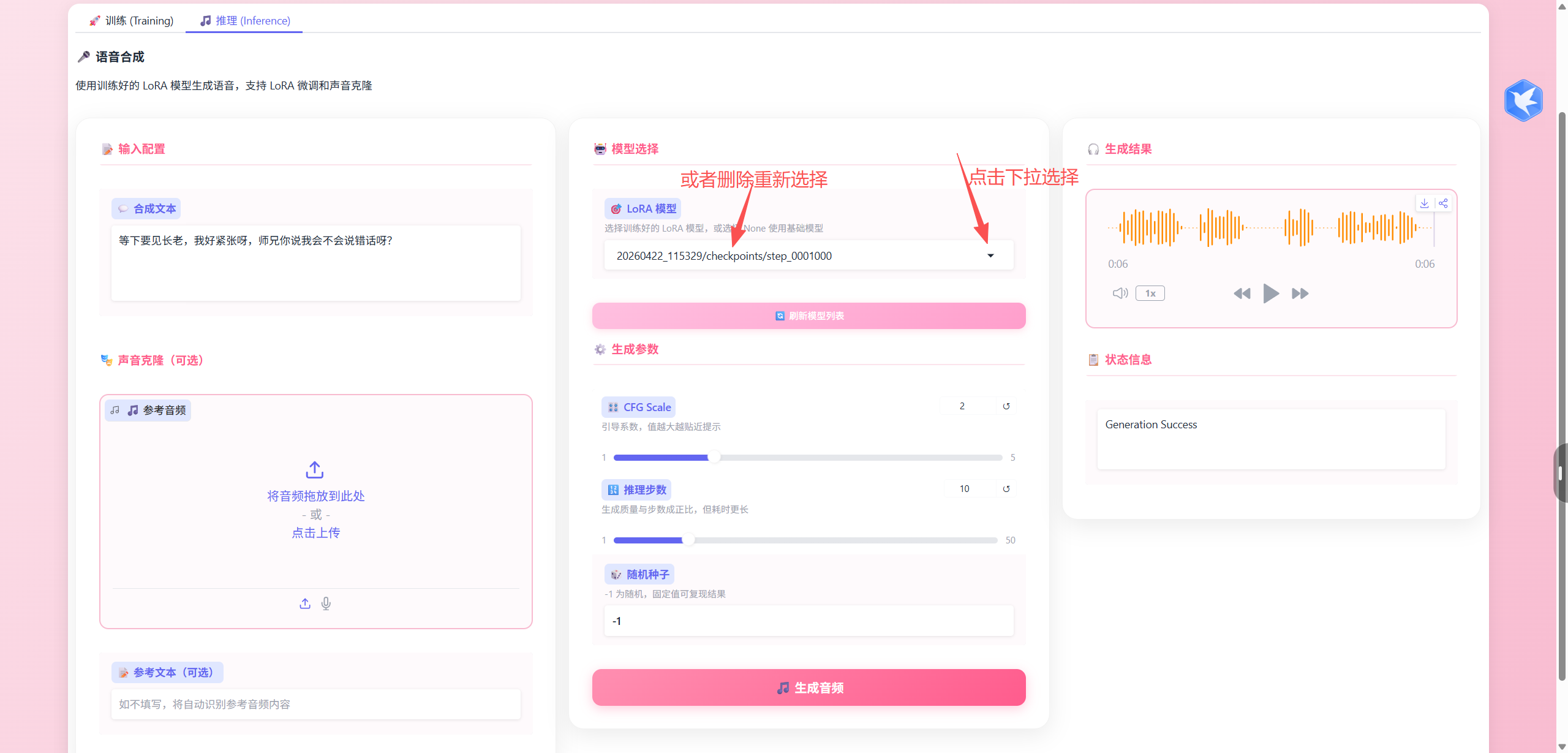
 推理:
推理:
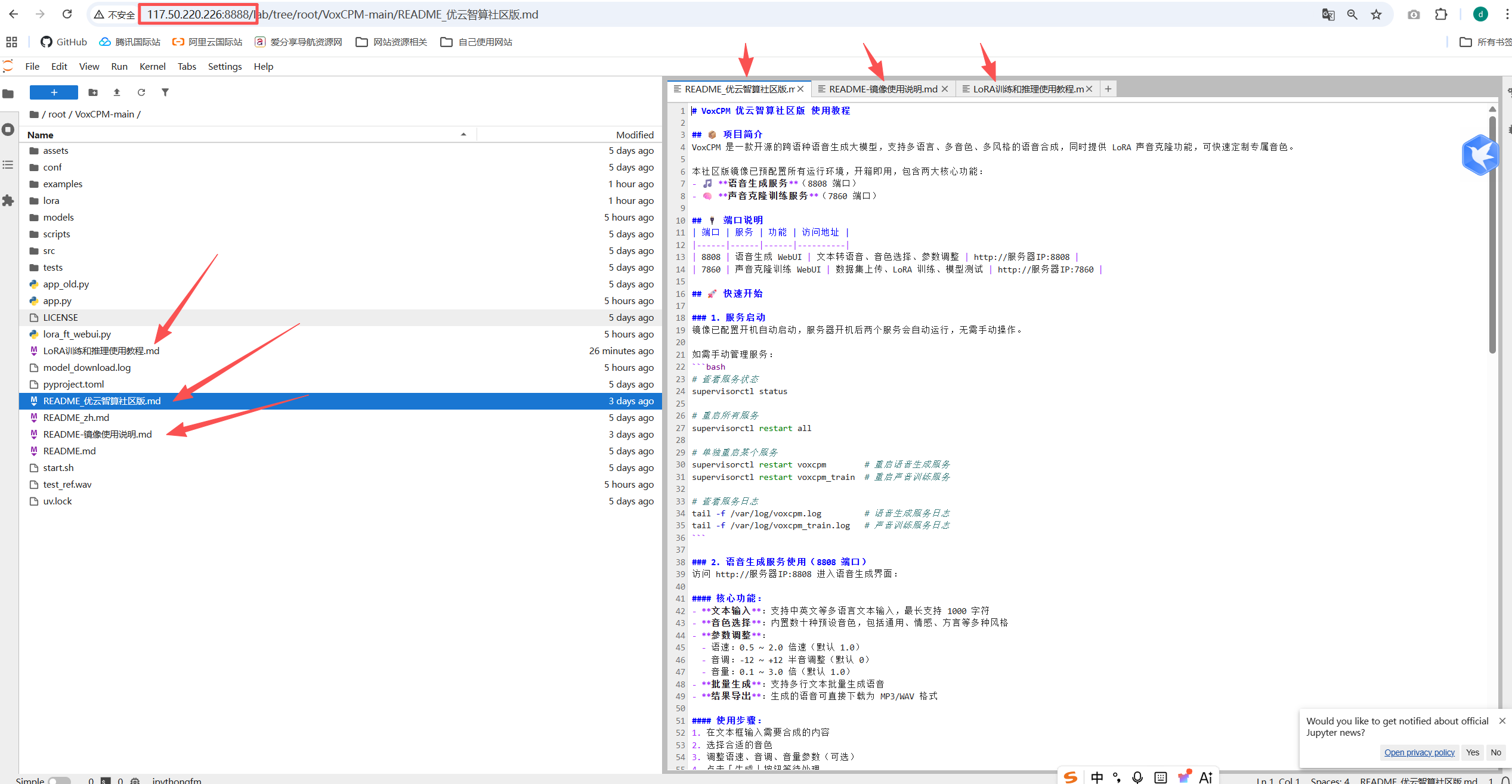
更多详细教程放这里了,小白也轻松上手:
打开这个JupyterLab案例来到这个目录/root/VoxCPM-main/里三个教程很全
如雨其他bug问题可以加Q群:1056612007提交bug
@星尘玩AI

镜像信息
已使用102 次
运行时长
254 H
 支持自启动
支持自启动镜像大小
50GB
最后更新时间
2026-05-20
支持卡型
RTX50系309048G RTX40系RTX40系
+4
框架版本
CUDA版本
12.8
应用
JupyterLab: 8888
版本
v2.0
2026-05-20
v1.0
2026-05-20