Musetalk训练专用
Musetalk训练专用
 0
00.3元/小时
v1.0
1. Musetalk训练进行
此镜像用于Musetalk的泛化模型训练,提供了完成的训练数据集HDTF,共包含403个视频素材
1.1 镜像简介
- 功能: Musetalk的泛化模型训练
- 特点: 提供了预处理环境与训练环境
1.2 环境与依赖
本镜像构建和运行所需的基础环境。
1.2.1 预处理环境
- 框架及版本: (例如:PyTorch 2.0.1)
- CUDA版本: (例如:CUDA 11.8)
- 其他依赖: (例如:Python 3.10)
1.2.2 训练环境
- 框架及版本: (例如:PyTorch 2.7.0)
- CUDA版本: (例如:CUDA 11.8)
- 其他依赖: (例如:Python 3.10)
2. 使用方法
2.1 预处理
- 激活预处理环境
# conda activate preprocess
# cd /root/MuseTalk
- 修改配置文件
/root/MuseTalk/configs/training/preprocess.yaml
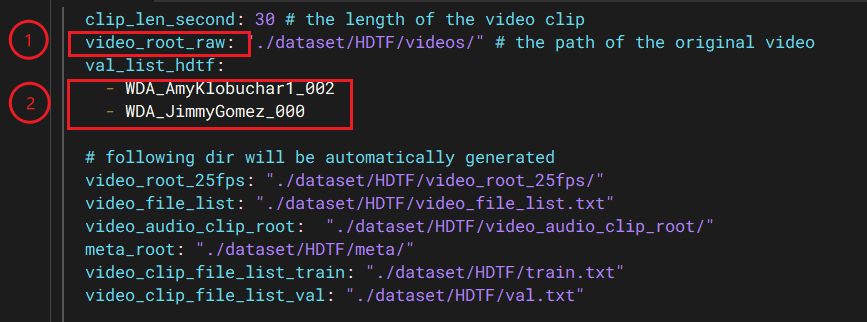 该配置文件需要修改两处:
该配置文件需要修改两处:
-
训练视频所在目录,videos文件夹中提供了几个视频素材可做快速验证。
/root/MuseTalk/dataset/HDTF目录下有一个videos.zip,是完整的训练视频,可解压后使用。 -
测试集文件列表,注意【不包括文件名的后缀 .mp4】,测试集自行在videos文件夹中进行挑选
-
配置文件
/root/MuseTalk/configs/training/.yaml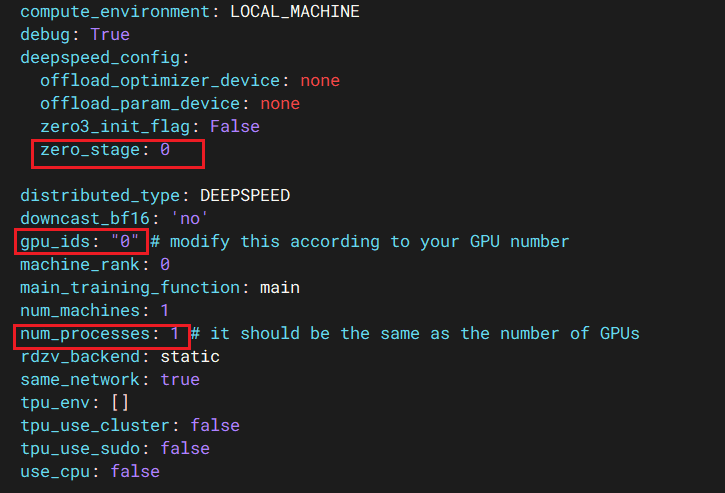
gpu_ids: 使用的GPU的id,如果电脑只有一张显卡,默认是 0num_processes: 只有一张显卡,则写1;应该与gpu_ids中的数量一致zero_stage: DeepSpeed 里的大模型显存优化技术。如果报错,需要改成 0
这个文件我已经修改好,无需修改
- 执行预训练
python -m scripts.preprocess --config ./configs/training/preprocess.yaml
2.2 第一阶段训练
- 激活训练环境
conda activate train
- 修改配置文件
configs/training/stage1.yaml
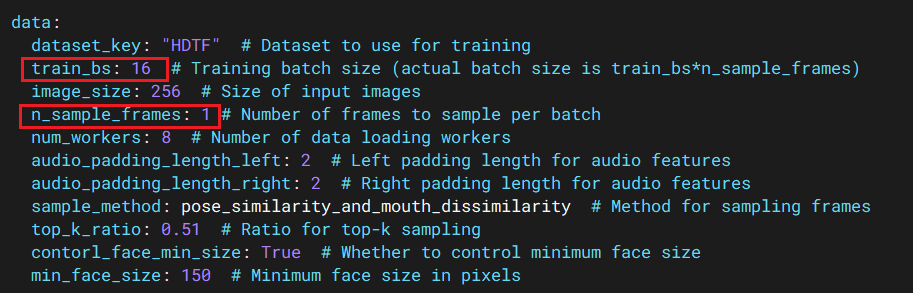
data.train_bs: Adjust batch size based on your GPU memory (default: 32)data.n_sample_frames: Number of sampled frames per video (default: 1)
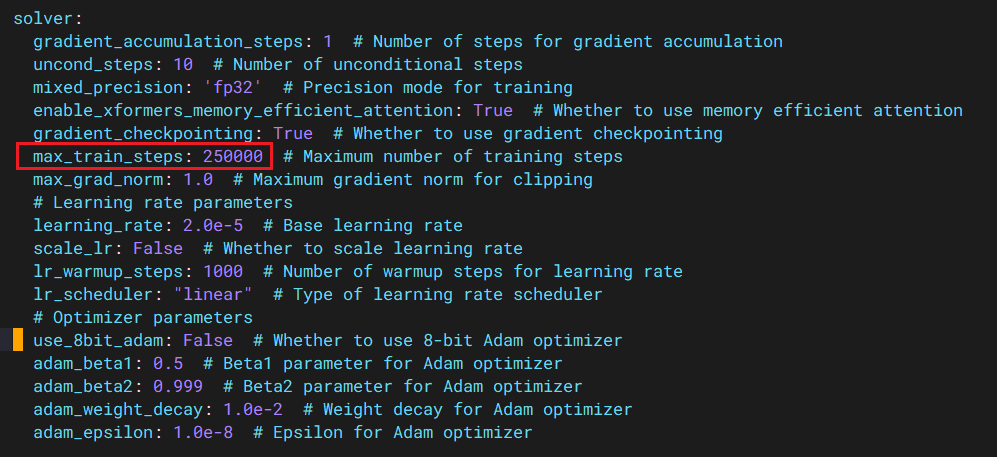
solver.max_train_steps: 最大训练步骤,如果希望快速验证,可调整此参数

total_limit: 保存 checkpoints 最大数量save_model_epoch_interval: 模型保存间隔checkpointing_steps: checkpoint 保存间隔val_freq: 验证频率
- 训练
sh train.sh stage1

2.3 第二阶段训练
- 激活训练环境
conda activate train
- 修改配置文件 -
configs/training/stage2.yaml

data.train_bs: Smaller batch size due to high GPU memory cost (default: 2)data.n_sample_frames: Higher value for temporal consistency (default: 16)

solver.gradient_accumulation_steps: Increase to simulate larger batch sizes (default: 8)solver.max_train_steps: 最大训练步骤,如果希望快速验证,可调整此参数

total_limit: 保存 checkpoints 最大数量save_model_epoch_interval: 模型保存间隔checkpointing_steps: checkpoint 保存间隔val_freq: 验证频率
==需要快速验证建议调小==
- 训练
sh train.sh stage2
2.4 显存使用说明
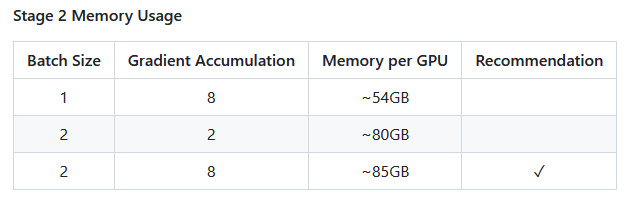
2.5 训练结果
训练的模型位置在 exp_out/stage2/test 目录中
~/MuseTalk# ls -l exp_out/stage2/test/
total 16601972
drwxr-xr-x 4 root root 4096 Apr 13 10:25 ./
drwxr-xr-x 3 root root 4096 Apr 13 10:18 ../
drwxr-xr-x 2 root root 4096 Apr 13 10:25 samples/
drwxr-xr-x 3 root root 4096 Apr 13 10:19 tensorboard/
-rw-r--r-- 1 root root 3400073943 Apr 13 10:21 unet-100.pth
-rw-r--r-- 1 root root 3400073943 Apr 13 10:23 unet-150.pth
-rw-r--r-- 1 root root 3400073943 Apr 13 10:24 unet-200.pth
-rw-r--r-- 1 root root 3400073943 Apr 13 10:25 unet-250.pth
-rw-r--r-- 1 root root 3400072675 Apr 13 10:20 unet-50.pth
@有黑眼圈的小竹熊

镜像信息
已使用4 次
运行时长
1 H
 支持自启动
支持自启动镜像大小
80GB
最后更新时间
2026-04-17
支持卡型
A80048G RTX40系A100H20
+4
框架版本
CUDA版本
11.8
应用
JupyterLab: 8888
版本
v1.0
2026-04-17