HunyuanVideo-1.5
一个领先的超轻量级视频生成模型
 6
60元/小时
v1.1
v1.0
HunyuanVideo-1.5
这是一个轻量级但功能强大的视频生成模型,仅用 83 亿参数就实现了最先进的视觉质量和运动连贯性,能够在消费级 GPU 上进行高效推理。这一成就基于几个关键组件,包括细致的数据管理、具有选择性滑动瓦片注意力的先进 DiT 架构(SSTA)、通过字形感知文本编码增强的双语理解、渐进式预训练和后训练,以及高效的视频超分辨率网络。利用这些设计,我们开发了一个统一的框架,能够在多个时长和分辨率下进行高质量的文本到视频和图像到视频生成。大量的实验表明,这个紧凑而专业的模型在开源模型中确立了新的最先进水平。通过发布 HunyuanVideo-1.5 的代码和权重,我们为社区提供了一个高性能的基础,显著降低了视频创作和研究的成本,使高级视频生成更加普及。
使用教程
0. 麻烦右上角点个收藏~

1. 在镜像详情界面点击“使用该镜像创建实例”
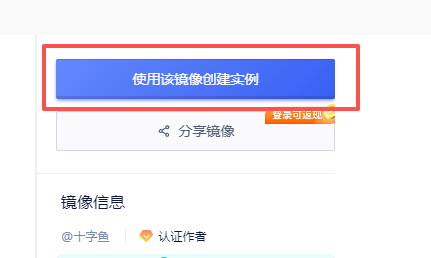
2. 选择GPU型号,再点击“立即部署”
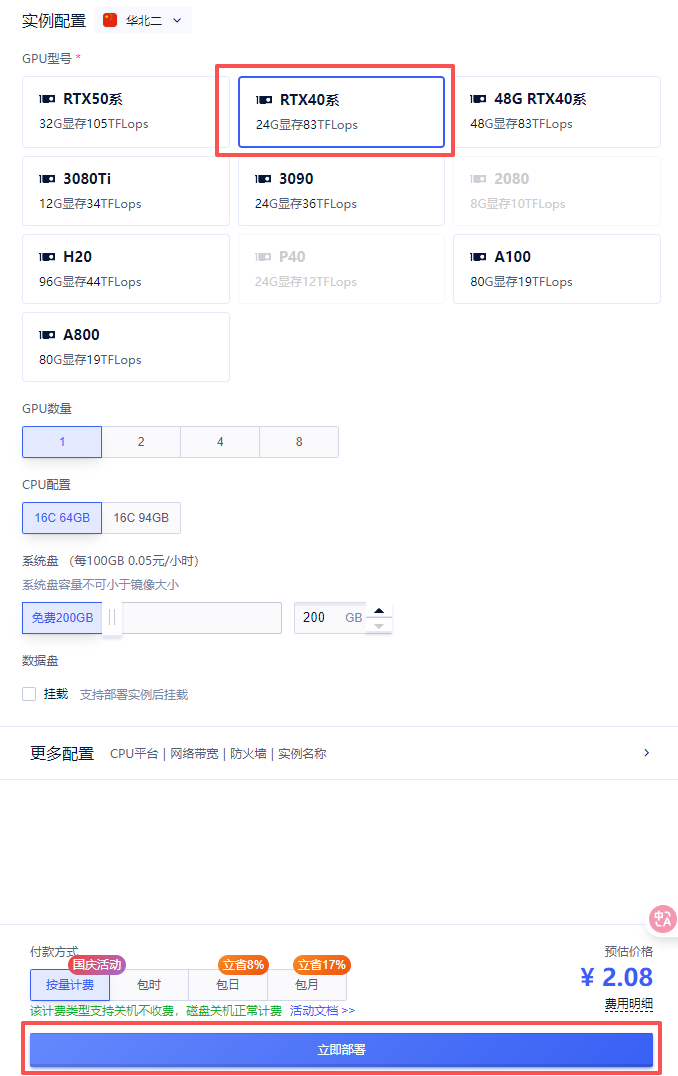
3. 实例启动后(此项目需要预加载模型和编译,启动时间较长,需等待5分钟),在控制台中点击“SD-WebUI”
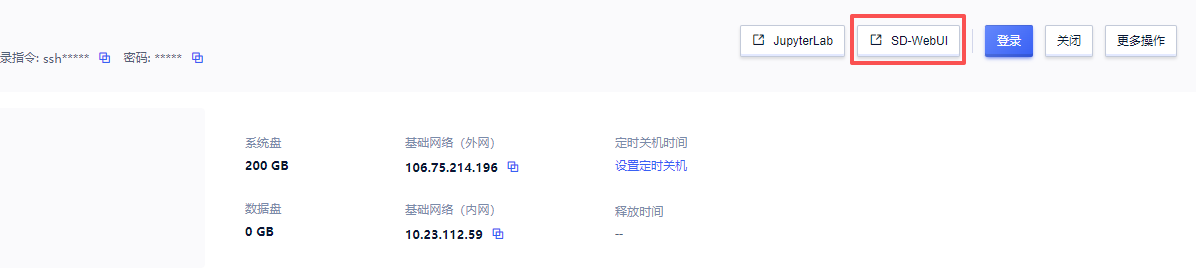
4.浏览器如图显示,就说明启动成功了
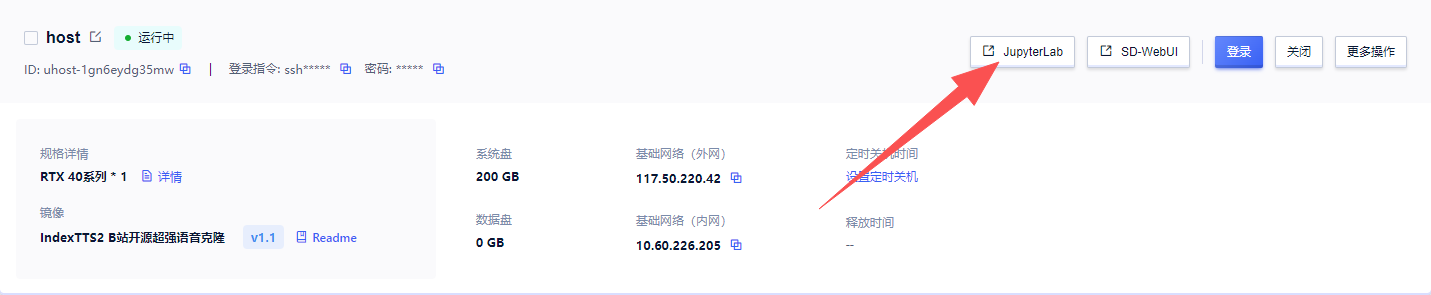
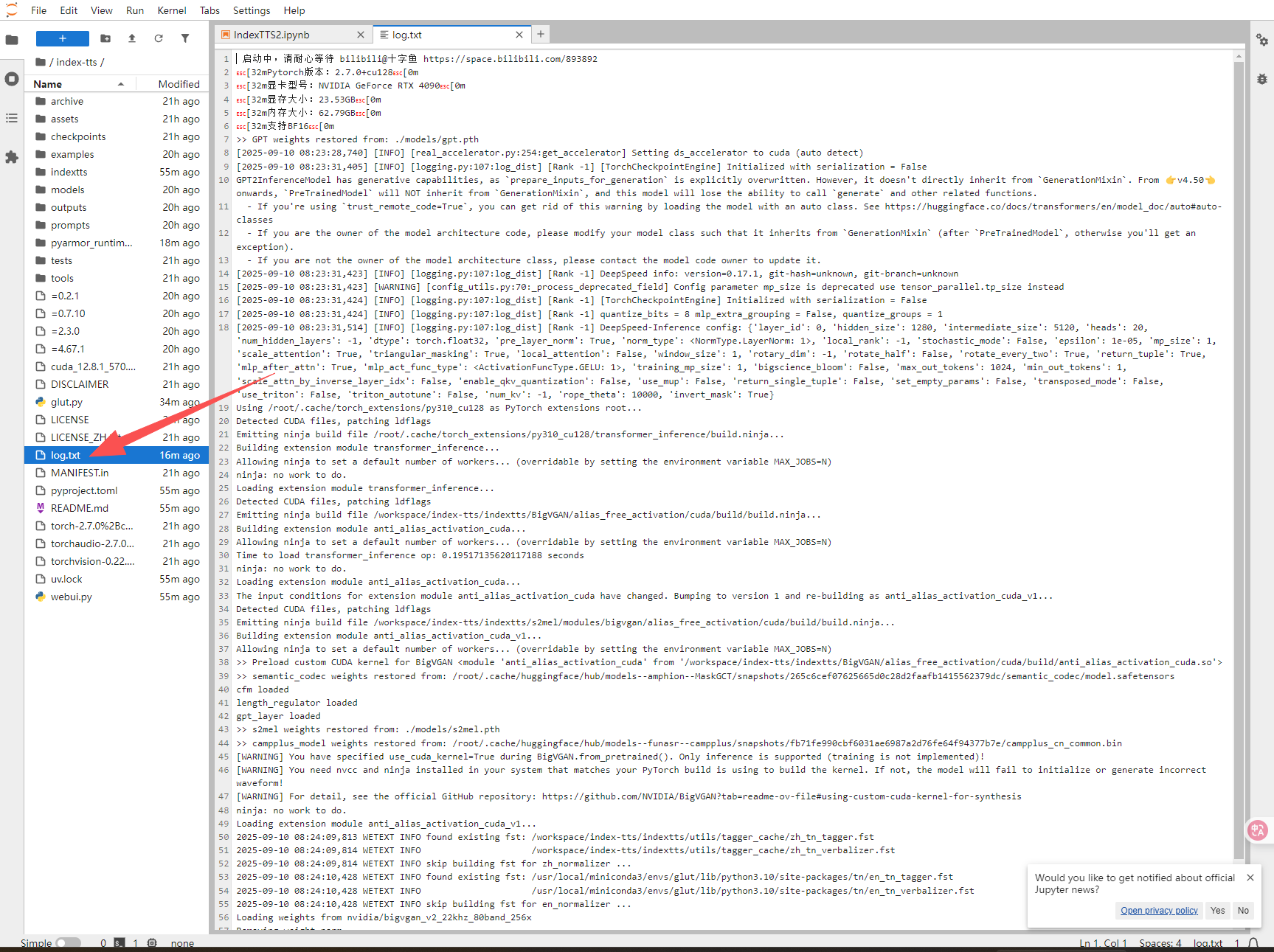
5.如果页面无响应(比如此项目需要预加载模型,启动时间较长),点击“JupyterLab”,再双击log.txt可查看启动进度
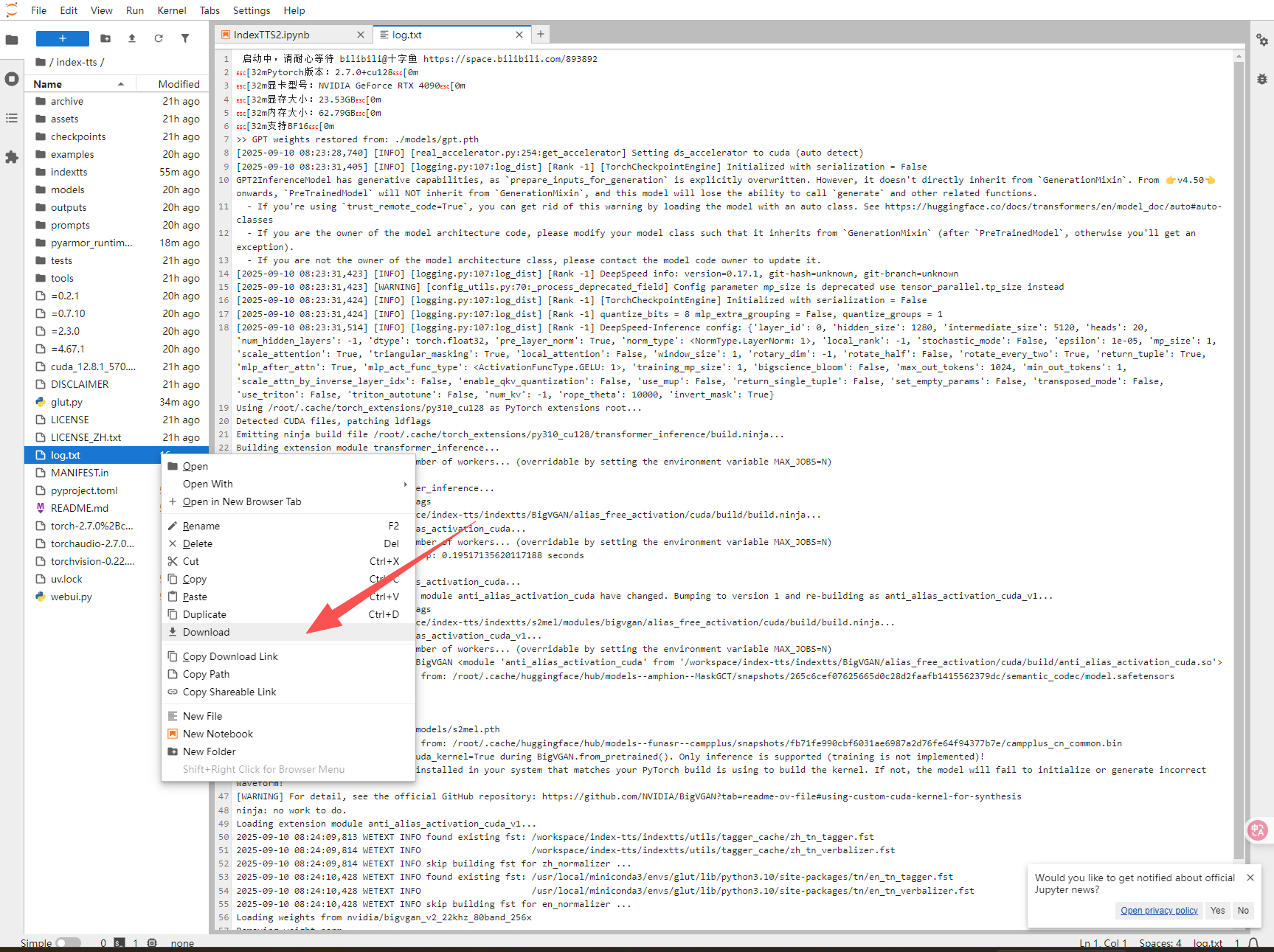
6.如果有报错的话,请下载log.txt发到下面的交流群中
十字鱼-镜像作者交流群

@十字鱼 认证作者
认证作者
认证作者
镜像信息
已使用24 次
运行时长
42 H
 支持自启动
支持自启动镜像大小
140GB
最后更新时间
2025-11-24
支持卡型
RTX40系48G RTX40系3090A800H20A100
+6
框架版本
CUDA版本
12.8
应用
JupyterLab: 8888
版本
v1.1
2025-11-24
v1.0
2025-11-21