Qwen3-ASR-1.7B,语音转文字字幕,视频转字幕,支持50系显卡,批量任务,支持热词控制
Qwen3-ASR-1.7B,语音转文字字幕,视频转字幕,支持50系显卡,批量任务,支持热词控制
 8
80元/小时
v2.0
v1.0
Qwen3-ASR-1.7B 0.6B,官方原版,支持超长音视频转文字字幕,视频转字幕,4G显存可用,支持50系显卡,批量任务,支持热词控制
v2.0 使用官方原版模型,修复超长音视频无法全部转写问题,增加一键批量任务
镜像简介
本镜像搭载基于通义千问Qwen3的ASR语音识别模型(1.7B参数),提供高效、精准的语音转文字及视频字幕生成服务。仅需4G显存即可运行,支持50系显卡、批量任务处理与热词控制优化,适用于视频制作、会议记录、内容审核及多语种字幕生成等场景,为用户提供轻量且专业的本地化语音识别解决方案。
镜像使用指南
1、该镜像支持自启动,初始化后,需要等待服务启动,大概2分钟左右,可以输入命令 tail -50f /root/wan/log.txt 查看启动日志
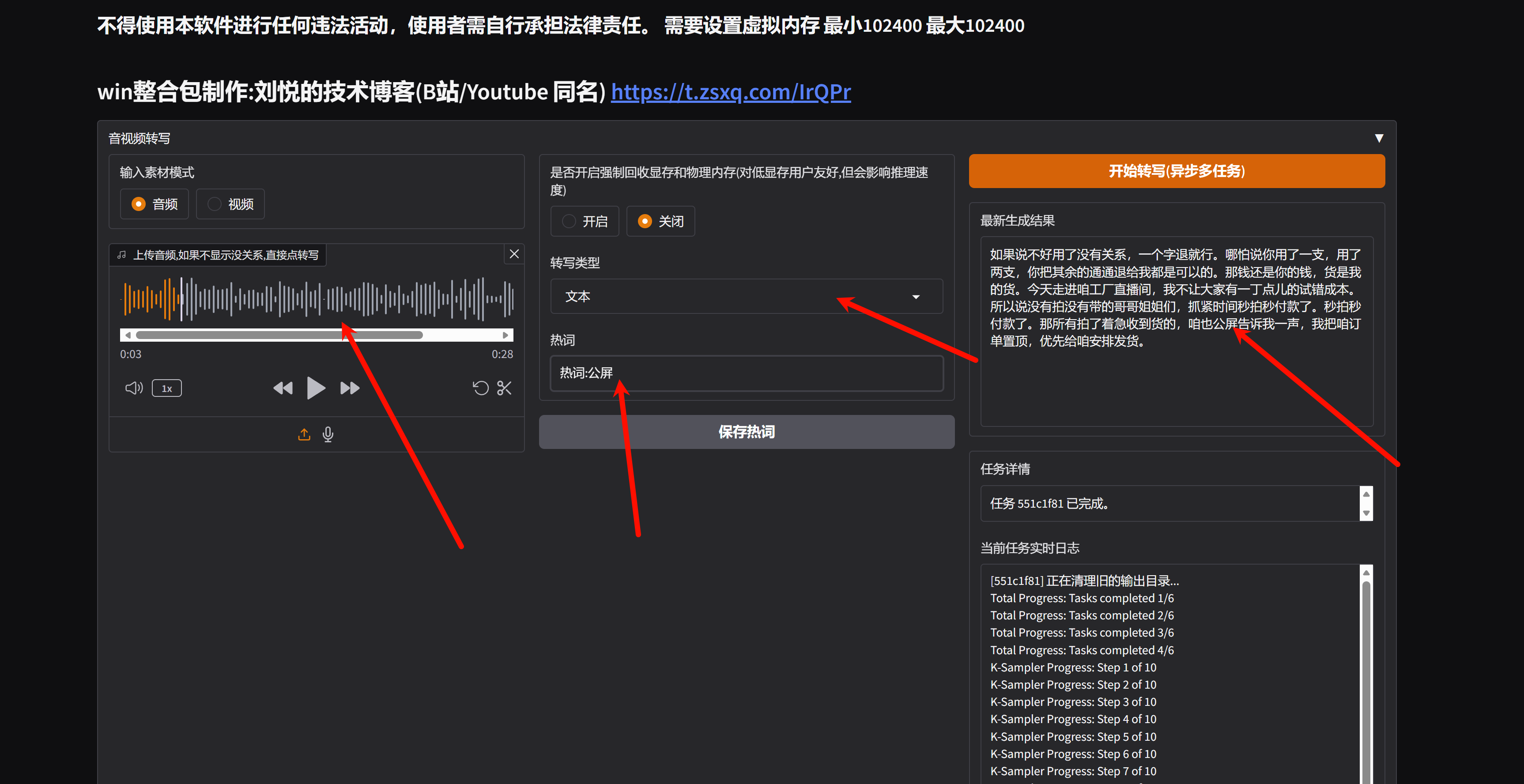
 2、随后点击 SD-WEBUI 按钮即可,上传音频或者视频,点击转写按钮即可,支持批量任务
2、随后点击 SD-WEBUI 按钮即可,上传音频或者视频,点击转写按钮即可,支持批量任务
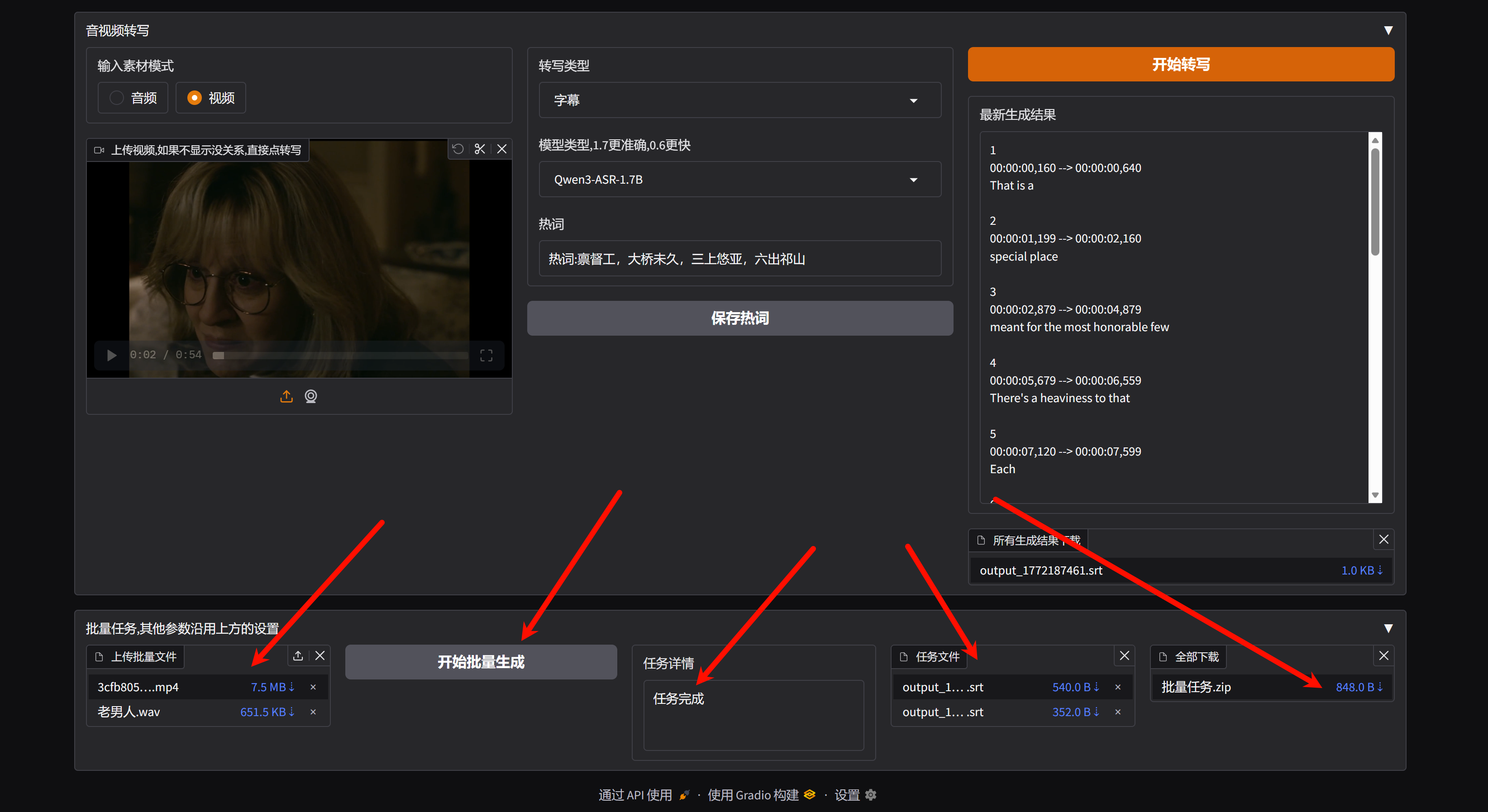
支持一键批量任务
@刘悦的技术博客 认证作者
认证作者
认证作者

镜像信息
已使用90 次
运行时长
885 H
 支持自启动
支持自启动镜像大小
70GB
最后更新时间
2026-06-05
支持卡型
RTX40系RTX50系48G RTX40系3080Ti2080Ti30902080A800V100S
+9
框架版本
CUDA版本
2.8
应用
JupyterLab: 8888
版本
v2.0
2026-06-05
v1.0
2026-02-25