VoxCPM1.5雨落版整合包
VoxCPM1.5的雨落版整合包
 7
70元/小时
v1.0
镜像名称
VoxCPM1.5的雨落版整合包。
镜像简介
- 功能1: 基于VoxCPM1.5进行推理,包括单角色、多角色和Excel表格。
- 功能2: LoRA训练,包括训练逻辑、数据集处理的多个工具。
- 功能3: 内部原理查看,包括文本正则化、Token查看、语音降噪、长句切分等。
- 特点: 所有环境都已经处理好,点击即可运行。需要说明的是,在机器启动后可能需要1-2分钟的服务启动时间,具体可以从Jupyter进入,查看log.txt即可。
环境与依赖
本镜像构建和运行所需的基础环境。
- 框架及版本: (例如:PyTorch 2.8.0)
- CUDA版本: (例如:CUDA 12.8)
- 其他依赖: 具体可参考rainfall这个虚拟环境。
环境验证代码
- **方式1:**支持开机自启动,启动后,可以去访问对应的7860端口。
- **方式2:**也可以直接从JupyterLab进入,然后在命令行执行python app.py即可。
有问题也可以加入右侧官方群里咨询
常见问题
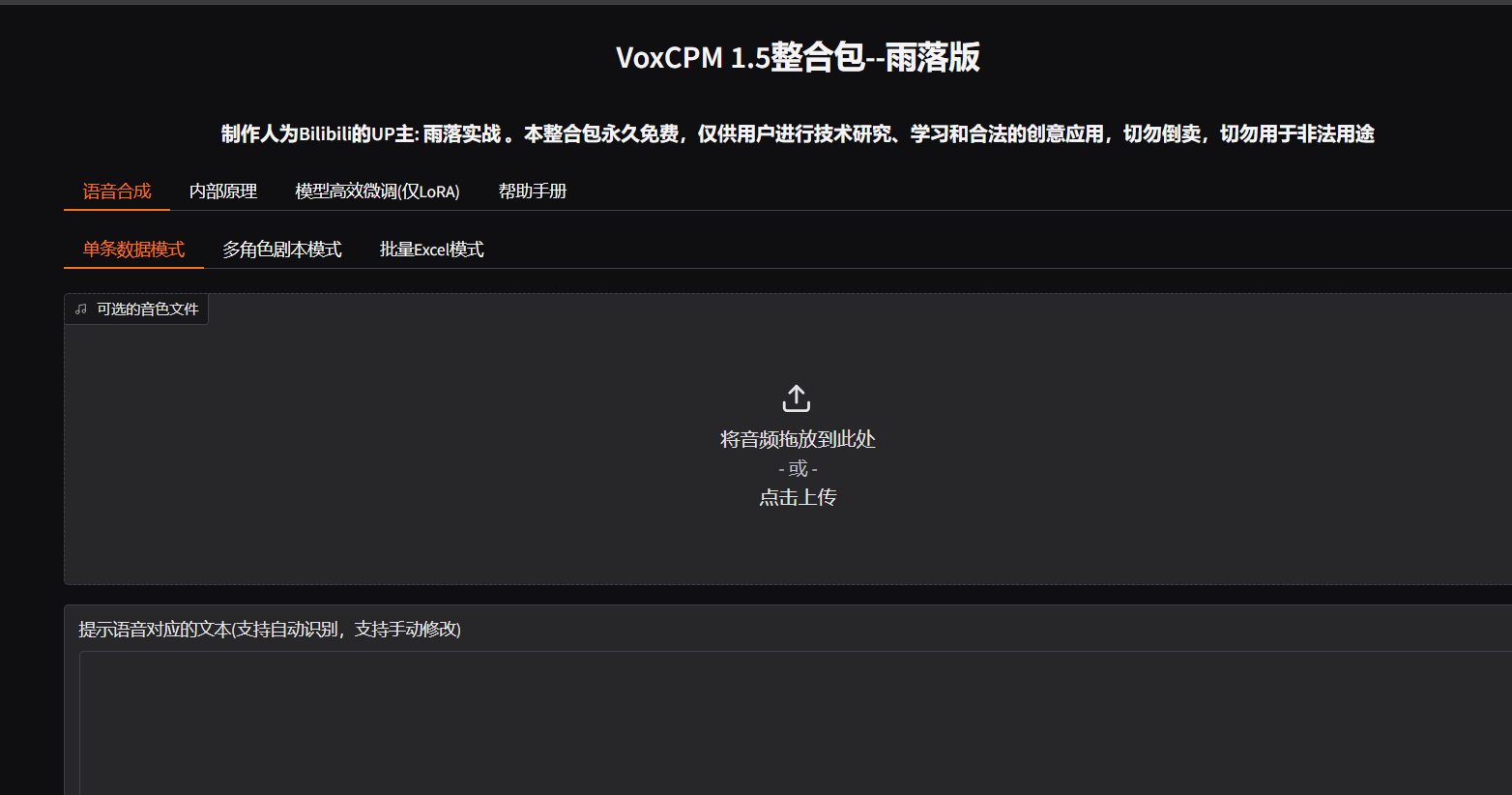
Q1: 在合成语音的单条数据中,参考音频一般建议多长?
A1: 通常的建议是10秒左右,最好是wav格式。
Q2: 在语音合成的多角色对话中,能给写个例子吗?
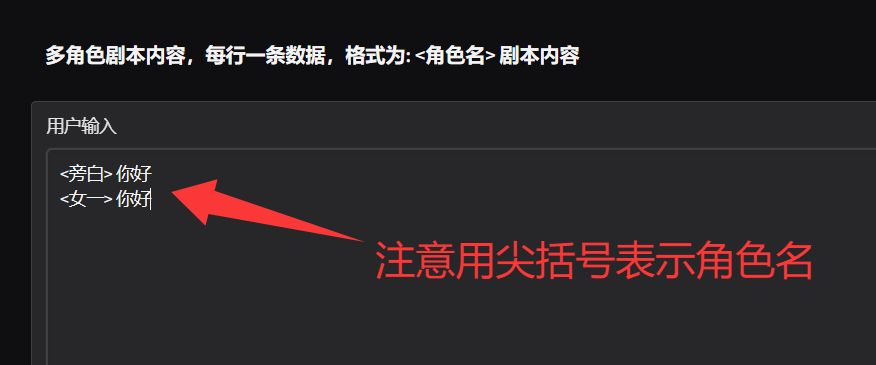
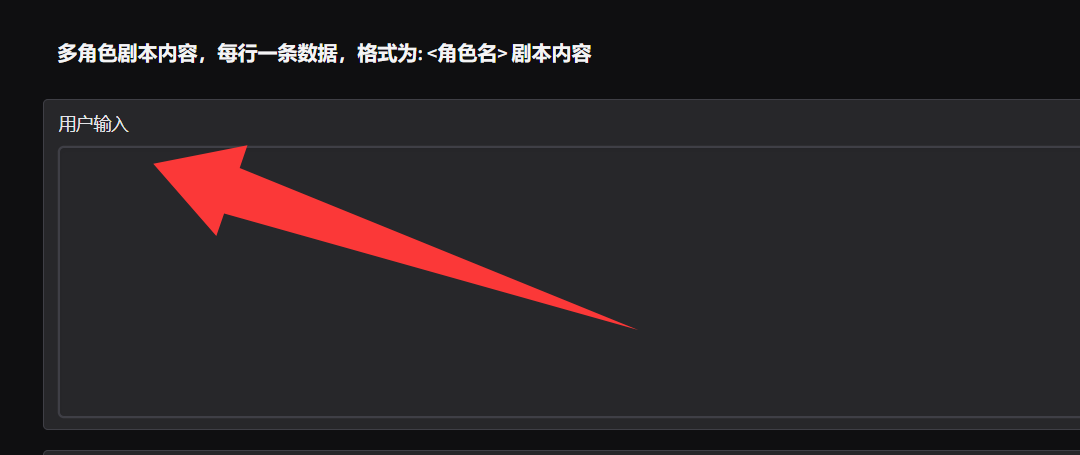 A2: 假如已经配置了"旁白"和"女一"这两个参考音频,那么就可以这么写:
A2: 假如已经配置了"旁白"和"女一"这两个参考音频,那么就可以这么写:
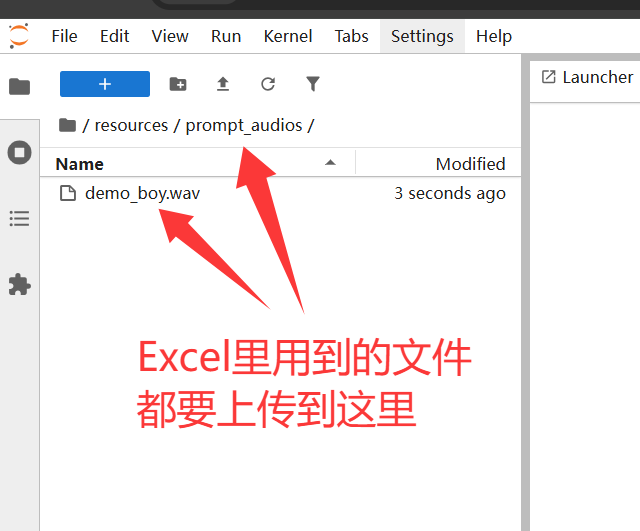
Q3: Excel这里的音频地址要怎么上传进去?
A3: 要上传到 路径 resources/prompt_audios这个目录下才能够被识别。
Q4: 关于LoRA微调这里功能有点复杂,具体怎么用呢?
A4: 这个确实有点复杂,细节很多,所以参考视频: https://www.bilibili.com/video/BV1vHqxB9ELk ,这个视频中使用的是本地版,但是使用体验上和云端版很相似。而且很快UP就会发布具体云端版的使用方法,可以去他的主页去搜索"VoxCPM 云端版"这样的关键字找到对应的讲解视频。
@雨落实战 认证作者
认证作者
认证作者

镜像信息
已使用97 次
运行时长
200 H
 支持自启动
支持自启动镜像大小
50GB
最后更新时间
2025-12-24
支持卡型
RTX40系RTX50系48G RTX40系3080Ti3090
+5
框架版本
CUDA版本
128
应用
JupyterLab: 8888
版本
v1.0
2025-12-24