 4
4Voice Sculptor捏声音基于LLaSA和CosyVoice2的指令化语音合成语音模型 二次开发构建by科哥
镜像简介
本镜像搭载基于LLaSA和CosyVoice2的指令化语音合成模型“Voice Sculptor”,支持通过自然语言指令精细调控音色、情感与语调,实现高度自定义的语音生成。适用于虚拟角色配音、有声内容创作、个性化语音助手等场景,为用户提供灵活、直观的“捏声音”体验与高质量的语音合成效果。
镜像操作指南
- 1、开机自动运行,等1-2分钟后,打开 【sd-webui】即可进入使用界面;


bug反馈可以加入科哥专属群交流➕ 广告勿进!

科哥在UCloud镜像列表【不断更新中】:
VoiceSculptor 用户使用手册
通过自然语言指令定制你的专属语音风格
📖 目录
🚀 快速启动
启动 WebUI
在终端中执行以下命令:
/bin/bash /root/VoiceSculptor/scripts/start_app.sh
启动成功后,会看到类似以下输出:
Running on local URL: http://0.0.0.0:7860
访问界面
在浏览器中打开以下任一地址:
如果在远程服务器上运行,请将
127.0.0.1替换为服务器的 IP 地址
重启应用
如需重启应用,再次执行启动命令即可,脚本会自动:
- 检测并终止占用 7860 端口的旧进程
- 清理 GPU 显存
- 启动新的应用实例
🖥️ 界面介绍
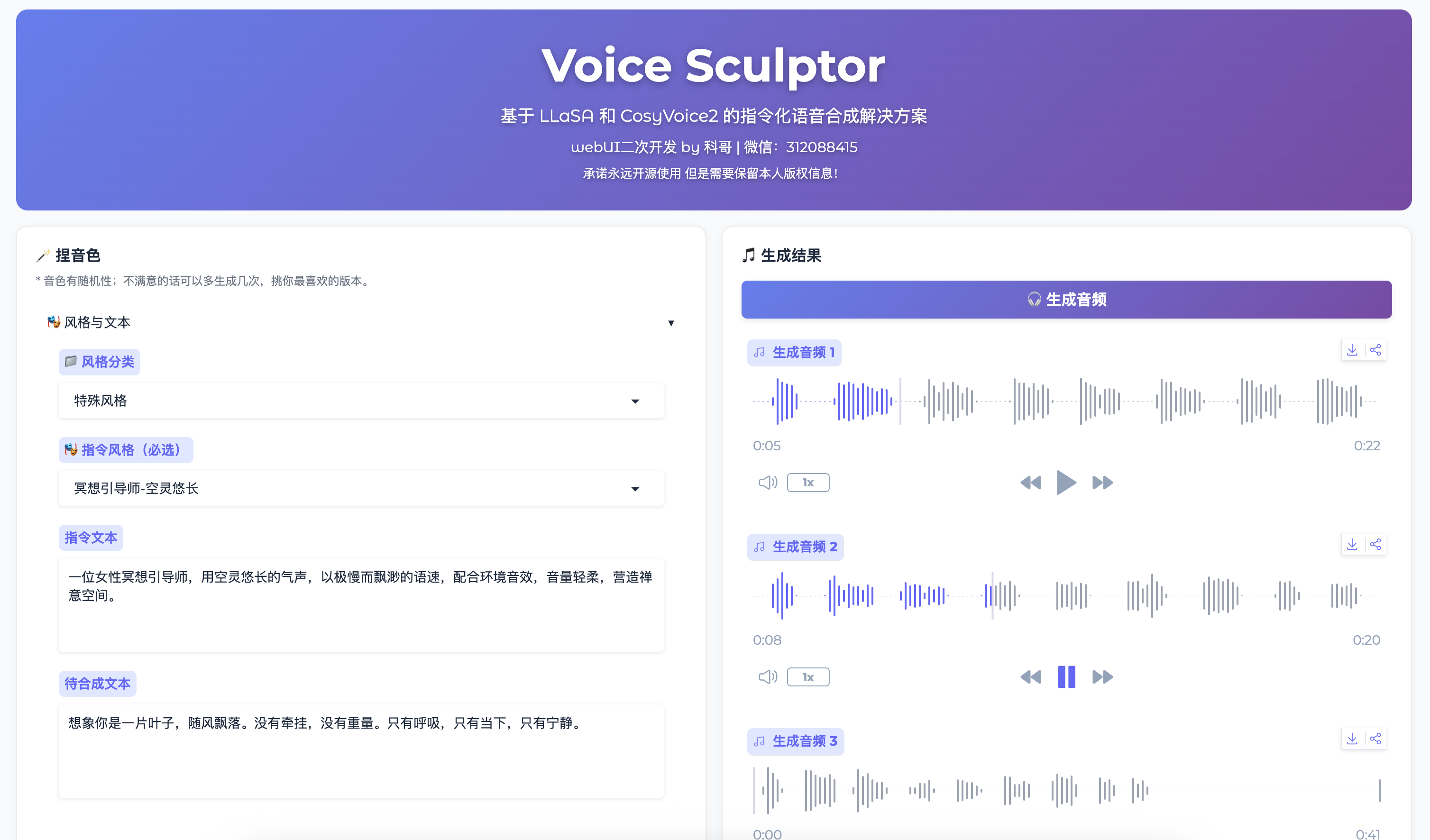
VoiceSculptor WebUI 分为左右两个主要区域:
左侧:音色设计面板
1. 风格与文本(默认展开)
| 组件 | 说明 |
|---|---|
| 风格分类 | 选择声音风格的大类(角色/职业/特殊) |
| 指令风格 | 选择具体的声音风格模板 |
| 指令文本 | 描述你想要的声音特质(≤200字) |
| 待合成文本 | 输入要合成的文字内容(≥5字) |
2. 细粒度声音控制(可选,默认折叠)
可以精确控制以下参数:
- 年龄:小孩 / 青年 / 中年 / 老年
- 性别:男性 / 女性
- 音调高度:音调很高 → 音调很低
- 音调变化:变化很强 → 变化很弱
- 音量:音量很大 → 音量很小
- 语速:语速很快 → 语速很慢
- 情感:开心 / 生气 / 难过 / 惊讶 / 厌恶 / 害怕
建议:细粒度控制应与指令描述保持一致
3. 最佳实践指南(默认折叠)
包含音色设计的建议和约束条件
右侧:生成结果面板
| 组件 | 说明 |
|---|---|
| 生成音频按钮 | 点击开始合成音频 |
| 生成音频 1/2/3 | 显示生成的 3 个音频结果 |
📝 基本使用流程
方式一:使用预设模板(推荐新手)
-
选择风格分类
- 点击"风格分类"下拉菜单
- 选择:角色风格 / 职业风格 / 特殊风格
-
选择具体模板
- 点击"指令风格"下拉菜单
- 选择你想要的声音风格
-
查看自动填充的内容
- "指令文本"会自动填充声音描述
- "待合成文本"会自动填充示例文本
-
(可选)修改内容
- 可以修改指令文本,自定义声音风格
- 可以修改待合成文本,输入你想说的内容
-
生成音频
- 点击"🎧 生成音频"按钮
- 等待约 10-15 秒
-
试听并下载
- 聆听 3 个音频版本
- 点击下载图标保存喜欢的版本
方式二:完全自定义
- 在"风格分类"中选择任意分类
- 在"指令风格"中选择"自定义"
- 在"指令文本"中输入你的声音描述(参考下节写法建议)
- 在"待合成文本"中输入要合成的文字
- 点击"🎧 生成音频"
🎭 声音风格说明
18 种内置风格速查
角色风格(9 种)
| 风格 | 特点 | 适用场景 |
|---|---|---|
| 幼儿园女教师 | 甜美明亮、极慢语速、温柔鼓励 | 儿童故事、睡前故事 |
| 电台主播 | 音调偏低、微哑、平静忧伤 | 深夜情感节目 |
| 成熟御姐 | 磁性低音、慵懒暧昧、掌控感 | 情感配音、角色扮演 |
| 年轻妈妈 | 柔和偏低、温暖安抚、轻柔哄劝 | 儿歌、安抚内容 |
| 小女孩 | 天真高亢、快节奏、尖锐清脆 | 儿童配音、活泼内容 |
| 老奶奶 | 沙哑低沉、极慢温暖、怀旧神秘 | 民间故事、传说 |
| 诗歌朗诵 | 深沉磁性、顿挫有力、激昂澎湃 | 诗歌、演讲、宣言 |
| 童话风格 | 甜美夸张、跳跃变化、奇幻 | 童话、动画配音 |
| 评书风格 | 传统说唱、变速节奏、江湖气 | 武侠故事、传统评书 |
职业风格(7 种)
| 风格 | 特点 | 适用场景 |
|---|---|---|
| 新闻风格 | 标准普通话、平稳专业、客观中立 | 新闻播报、正式内容 |
| 相声风格 | 夸张幽默、时快时慢、起伏大 | 相声、喜剧内容 |
| 悬疑小说 | 低沉神秘、变速节奏、悬念感 | 悬疑故事、恐怖小说 |
| 戏剧表演 | 夸张戏剧、忽高忽低、充满张力 | 戏剧独白、表演 |
| 法治节目 | 严肃庄重、平稳有力、法律威严 | 法治栏目、严肃内容 |
| 纪录片旁白 | 深沉磁性、缓慢画面感、敬畏诗意 | 纪录片、自然类内容 |
| 广告配音 | 沧桑浑厚、缓慢豪迈、历史底蕴 | 商业广告、品牌宣传 |
特殊风格(2 种)
| 风格 | 特点 | 适用场景 |
|---|---|---|
| 冥想引导师 | 空灵悠长、极慢飘渺、禅意 | 冥想、放松、助眠 |
| ASMR | 气声耳语、极慢细腻、极度放松 | ASMR、助眠内容 |
如何写好指令文本
✅ 好的指令示例
这是一位男性评书表演者,用传统说唱腔调,以变速节奏和韵律感极强的语速讲述江湖故事,音量时高时低,充满江湖气。
分析:
- 明确人设:男性评书表演者
- 具体特质:传统说唱腔调、变速节奏、韵律感强
- 情绪氛围:江湖气
- 多维度覆盖:人设 + 音色 + 节奏 + 情感
❌ 不好的指令示例
声音很好听,很不错的风格。
问题:
- "好听""不错"太主观,无法感知
- 缺少具体的声音特质描述
- 没有人设和场景
写法建议
| 原则 | 说明 |
|---|---|
| 具体 | 用可感知特质词:低沉/清脆/沙哑/明亮、语速快慢、音量大小 |
| 完整 | 覆盖 3-4 个维度:人设/场景 + 性别/年龄 + 音调/语速 + 音质/情绪 |
| 客观 | 描述声音特征,避免"我喜欢""很棒" |
| 不做模仿 | 不要说"像某某明星",只描述声音特质本身 |
| 精炼 | 每个词都承载信息,避免重复(如"非常非常") |
🎛️ 细粒度控制
参数说明
| 参数 | 可选值 | 说明 |
|---|---|---|
| 年龄 | 不指定/小孩/青年/中年/老年 | 控制说话者的年龄感 |
| 性别 | 不指定/男性/女性 | 控制说话者的性别 |
| 音调高度 | 不指定/音调很高→很低 | 控制声音的音高 |
| 音调变化 | 不指定/变化很强→很弱 | 控制语调的起伏程度 |
| 音量 | 不指定/音量很大→很小 | 控制音量大小 |
| 语速 | 不指定/语速很快→很慢 | 控制说话速度 |
| 情感 | 不指定/开心/生气/难过/惊讶/厌恶/害怕 | 控制情绪倾向 |
使用建议
-
保持一致
- 细粒度控制应与指令文本描述一致
- 避免矛盾(如指令说"低沉",细粒度选"音调很高")
-
不必全部填写
- 大部分情况保持"不指定"即可
- 只在需要微调时填写特定参数
-
组合示例
想要的效果:年轻女性激动地说好消息
指令文本:一位年轻女性,用明亮高亢的嗓音,以较快的语速兴奋地宣布好消息。 细粒度控制: - 年龄:青年 - 性别:女性 - 语速:语速较快 - 情感:开心
❓ 常见问题
Q1:生成音频需要多久?
A: 通常 10-15 秒,具体取决于:
- 文本长度
- GPU 性能
- 当前显存占用情况
Q2:为什么同样的输入生成的音频不一样?
A: 这是模型的正常特性,存在一定随机性。建议:
- 多生成几次(3-5次)
- 选择最满意的版本
Q3:音频质量不满意怎么办?
A: 尝试以下方法:
- 多生成几次,挑选最佳版本
- 优化指令文本描述,参考《声音风格.md》中的模板
- 检查细粒度控制是否与指令矛盾
Q4:可以合成多长的文本?
A:
- 单次建议不超过 200 字
- 超长文本建议分段合成
Q5:支持哪些语言?
A: 当前版本仅支持中文。英文及其他语言正在开发中。
Q6:生成音频保存在哪里?
A:
- 网页中可点击下载图标直接下载
- 自动保存到
outputs/目录,按时间戳命名 - 包含 3 个音频文件和 metadata.json
Q7:提示 CUDA out of memory 怎么办?
A: 执行以下清理步骤:
# 清理 Python 进程
pkill -9 python
# 清理 GPU 设备占用
fuser -k /dev/nvidia*
# 等待 3 秒
sleep 3
# 检查显存状态
nvidia-smi
然后重新启动应用。
Q8:端口被占用怎么办?
A: 启动脚本会自动处理。如需手动处理:
# 查找占用进程
lsof -i :7860
# 终止进程
lsof -ti:7860 | xargs kill -9
# 等待 2 秒后重启
sleep 2
📚 相关文档
💡 使用技巧
技巧 1:快速试错
不要指望一次生成就完美,多尝试不同的指令描述,找到最佳效果。
技巧 2:组合使用
- 先用预设模板生成基础效果
- 再根据需要微调指令文本
- 最后用细粒度控制精确调节
技巧 3:保存好配置
生成满意的效果后:
- 记录指令文本
- 记录细粒度控制参数
- 保存 metadata.json 便于复现
📞 技术支持
如遇问题或需要帮助,请联系:
- 微信: 312088415
- 开发者: 科哥
VoiceSculptor | 基于 LLaSA 和 CosyVoice2 的指令化语音合成解决方案 承诺永远开源使用,保留原作者版权信息
VoiceSculptor 声音风格参考手册
本文档整理了 VoiceSculptor 内置的 18 种声音风格样例,按分类组织,供用户参考使用。
📋 目录
🎭 角色风格
1. 幼儿园女教师 - 温柔甜美
提示词:
这是一位幼儿园女教师,用甜美明亮的嗓音,以极慢且富有耐心的语速,带着温柔鼓励的情感,用标准普通话给小朋友讲睡前故事,音量轻柔适中,咬字格外清晰。
待合成文本:
月亮婆婆升上天空啦,星星宝宝都困啦。小白兔躺在床上,盖好小被子,闭上眼睛。兔妈妈轻轻地唱着摇篮曲:睡吧睡吧,我亲爱的宝贝。
2. 电台主播 - 平静温柔
提示词:
深夜电台主播,男性、音调偏低、语速偏慢、音量小;情绪平静带点忧伤,语气温柔;音色微哑
待合成文本:
大家好,欢迎收听你的月亮我的心,好男人就是我,我就是:曾小贤。
3. 成熟御姐 - 温柔暧昧
提示词:
成熟御姐风格,语速偏慢,音量适中,情绪慵懒暧昧,语气温柔笃定带掌控感,磁性低音,吐字清晰,尾音微挑,整体有贴近感与撩人的诱惑。
待合成文本:
小帅哥,今晚有空吗?陪姐姐喝一杯,聊点有意思的。
4. 年轻妈妈 - 温暖安抚
提示词:
年轻妈妈哄孩子入睡,女性、音调柔和偏低、语速偏慢、音量偏小但清晰;情绪温暖安抚、充满耐心与爱意,语气轻柔哄劝、像贴近耳边低声说话;音色软糯,吐字清晰、节奏舒缓。
待合成文本:
从前有座山,山里有座庙,庙里面有个小和尚,小和尚在给老和尚讲故事,他说:从前有座山,山里有座庙,庙里面有一个小和尚。
5. 小女孩 - 尖锐清脆
提示词:
一位7岁的小女孩,用天真高亢的童声,以不稳定的快节奏,充满兴奋和炫耀地背诵乘法口诀,音调忽高忽低,带着儿童特有的尖锐清脆。
待合成文本:
一一得一!一二得二!一三得三!我会背乘法口诀啦!老师今天表扬我啦!妈妈说我最棒!
6. 老奶奶 - 沙哑低沉
提示词:
一位慈祥的老奶奶,用沙哑低沉的嗓音,以极慢而温暖的语速讲述民间传说,音量微弱但清晰,带着怀旧和神秘的情感。
待合成文本:
很久很久以前,在山的那边,住着一只会说话的狐狸。它常常在月圆之夜,变成美丽的姑娘,来到村子里。
7. 诗歌朗诵 - 雄浑有力
提示词:
一位男性现代诗朗诵者,用深沉磁性的低音,以顿挫有力的节奏演绎艾青诗歌,音量洪亮,情感激昂澎湃。
待合成文本:
为什么我的眼里常含泪水?因为我对这土地爱得深沉。这土地,这河流,这吹刮着的暴风。
8. 童话风格 - 甜美夸张
提示词:
这是一位女性童话旁白朗诵者,用甜美夸张的童声,以跳跃变化的语速讲述《安徒生童话》,音调偏高,充满奇幻色彩。
待合成文本:
在一个很冷很冷的夜晚,小女孩擦亮了一根火柴。突然,温暖的火炉出现了!她觉得自己好像坐在火炉旁。
9. 评书风格 - 抑扬顿挫
提示词:
这是一位男性评书表演者,用传统说唱腔调,以变速节奏和韵律感极强的语速讲述江湖故事,音量时高时低,充满江湖气。
待合成文本:
话说那武松,提着哨棒,直奔景阳冈。天色将晚,酒劲上头,只听一阵狂风,老虎来啦!
💼 职业风格
1. 新闻风格 - 平静专业
提示词:
这是一位女性新闻主播,用标准普通话以清晰明亮的中高音,以平稳专业的语速播报时事新闻,音量洪亮,情感客观中立。
待合成文本:
本台讯,今日凌晨,我国成功发射新一代载人飞船试验船。此次任务验证了多项关键技术,为后续空间站建设奠定基础。
2. 相声风格 - 夸张幽默
提示词:
这是一位男性相声表演者,用夸张幽默的嗓音,以时快时慢的节奏抖包袱,音调起伏大,充满喜感和节奏感。
待合成文本:
我这个人啊,最大的优点就是太谦虚。谦虚到什么程度?连谦虚本身都觉得我太谦虚了!
3. 悬疑小说 - 低沉神秘
提示词:
一位男性悬疑小说演播者,用低沉神秘的嗓音,以时快时慢的变速节奏营造紧张氛围,音量忽高忽低,充满悬念感。
待合成文本:
深夜,他独自走在空无一人的小巷。脚步声,回声,还有……另一个人的呼吸声。他猛地回头——什么也没有。
4. 戏剧表演 - 夸张戏剧
提示词:
这是一位男性戏剧表演者,用夸张戏剧化的嗓音,以忽高忽低的音调和时快时慢的语速表演独白,充满张力。
待合成文本:
我疯了!彻底疯了!你们都说我疯了!可疯的是这个世界!清醒的人反而被当成疯子!
5. 法治节目 - 庄严庄重
提示词:
这是一位男性法治节目主持人,用严肃庄重的嗓音,以平稳有力的语速讲述案件,音量适中,体现法律的威严。
待合成文本:
天网恢恢,疏而不漏。任何触犯法律的行为,终将受到公正的审判。正义或许会迟到,但绝不会缺席。
6. 纪录片旁白 - 低沉磁性
提示词:
这是一位男性纪录片旁白,用深沉磁性的嗓音,以缓慢而富有画面感的语速讲述自然奇观,音量适中,充满敬畏和诗意。
待合成文本:
在这片广袤的非洲草原上,生命与死亡每天都在上演。猎豹的速度,羚羊的敏捷,都是生存的代价。
7. 广告配音 - 沧桑浑厚
提示词:
这是一位男性白酒品牌广告配音,用沧桑浑厚的嗓音,以缓慢而豪迈的语速,音量洪亮,传递历史底蕴和男人情怀。
待合成文本:
一杯敬过往,一杯敬远方。传承千年的酿造工艺,只在每一滴醇香。老朋友,值得好酒。
🌟 特殊风格
1. 冥想引导师 - 空灵悠长
提示词:
一位女性冥想引导师,用空灵悠长的气声,以极慢而飘渺的语速,配合环境音效,音量轻柔,营造禅意空间。
待合成文本:
想象你是一片叶子,随风飘落。没有牵挂,没有重量。只有呼吸,只有当下,只有宁静。
2. ASMR - 气声耳语
提示词:
一位女性ASMR主播,用气声耳语,以极慢而细腻的语速,配合唇舌音,音量极轻,营造极度放松的氛围。
待合成文本:
现在,让我在你耳边轻声细语。听到我的声音了吗?放松你的头皮,感受每一个毛孔都在呼吸。
📚 音色设计指南
关键约束
- 指令文本 ≤ 200 字
- 当前仅支持中文
- 待合成文本长度 ≥ 5 个字
写法建议
| 原则 | 说明 |
|---|---|
| 具体 | 用可感知特质词(低沉/清脆/沙哑/明亮、语速快慢、音量大小等),避免"好听/不错" |
| 完整 | 建议覆盖 3–4 个维度(人设/场景 + 性别/年龄 + 音调/语速 + 音质/情绪) |
| 客观 | 描述声音特征与表达方式,避免"我喜欢/很棒" |
| 不做模仿 | 禁止"像某明星/某演员",只描述声音特质本身 |
| 尽量精炼 | 每个词都承载信息,避免重复强调(如"非常非常") |
细粒度控制提示
细粒度控制(年龄/性别/音调/语速/音量/情感等)建议与指令描述保持一致,尽量避免相互矛盾(如指令写"低沉慢速",细粒度却选"音调很高/语速很快")。
控制选项参考
| 控制项 | 可选值 |
|---|---|
| 年龄 | 不指定 / 小孩 / 青年 / 中年 / 老年 |
| 性别 | 不指定 / 男性 / 女性 |
| 音调高度 | 不指定 / 音调很高 / 音调较高 / 音调中等 / 音调较低 / 音调很低 |
| 音调变化 | 不指定 / 音调变化很强 / 音调变化较强 / 音调变化一般 / 音调变化较弱 / 音调变化很弱 |
| 音量 | 不指定 / 音量很大 / 音量较大 / 音量中等 / 音量较小 / 音量很小 |
| 语速 | 不指定 / 语速很快 / 语速较快 / 语速中等 / 语速较慢 / 语速很慢 |
| 情感 | 不指定 / 开心 / 生气 / 难过 / 惊讶 / 厌恶 / 害怕 |
📌 使用说明
- 在 WebUI 中选择对应的风格分类
- 选择具体的指令风格模板
- 系统会自动填充指令文本和待合成文本
- 可根据需要调整细粒度控制参数
- 点击生成音频按钮开始合成
音色有随机性,不满意的话可以多生成几次,挑你最喜欢的版本。
完整指南请见: Voice Design README
本文档由 VoiceSculptor 自动生成 | webUI二次开发 by 科哥 | 微信:312088415
 认证作者
认证作者
 支持自启动
支持自启动