StableAvatar快速生成对口型数字人视频 12gb显卡爆改by科哥
对口型数字人视频wan2.1优化项目 12gb显卡爆改by科哥
 9
90元/小时
v1.1
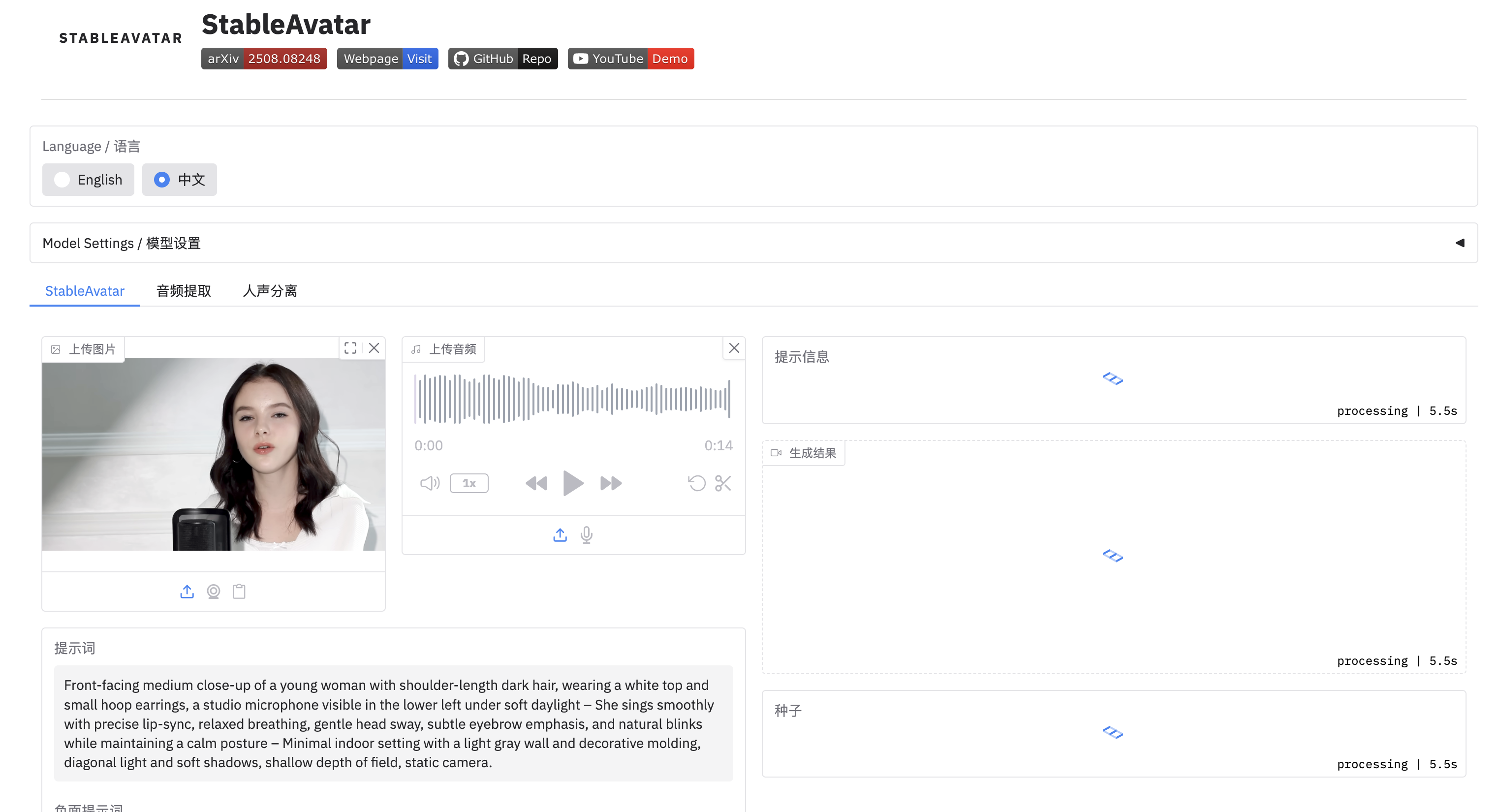
StableAvatar快速生成对口型数字人视频
模型介绍:
StableAvatar 是复旦大学、微软亚洲研究院等推出的创新音频驱动虚拟形象视频生成模型。 模型通过端到端的视频扩散变换器,结合时间步感知音频适配器、音频原生引导机制和动态加权滑动窗口策略,能生成无限长度的高质量虚拟形象视频。模型解决了现有模型在长视频生成中出现的身份一致性、音频同步和视频平滑性问题,显著提升生成视频的自然度和连贯性,适用虚拟现实、数字人创建等场景。
使用教程
创建实例
1、选择本镜像创建实例,推荐选择4090 GPU进行部署
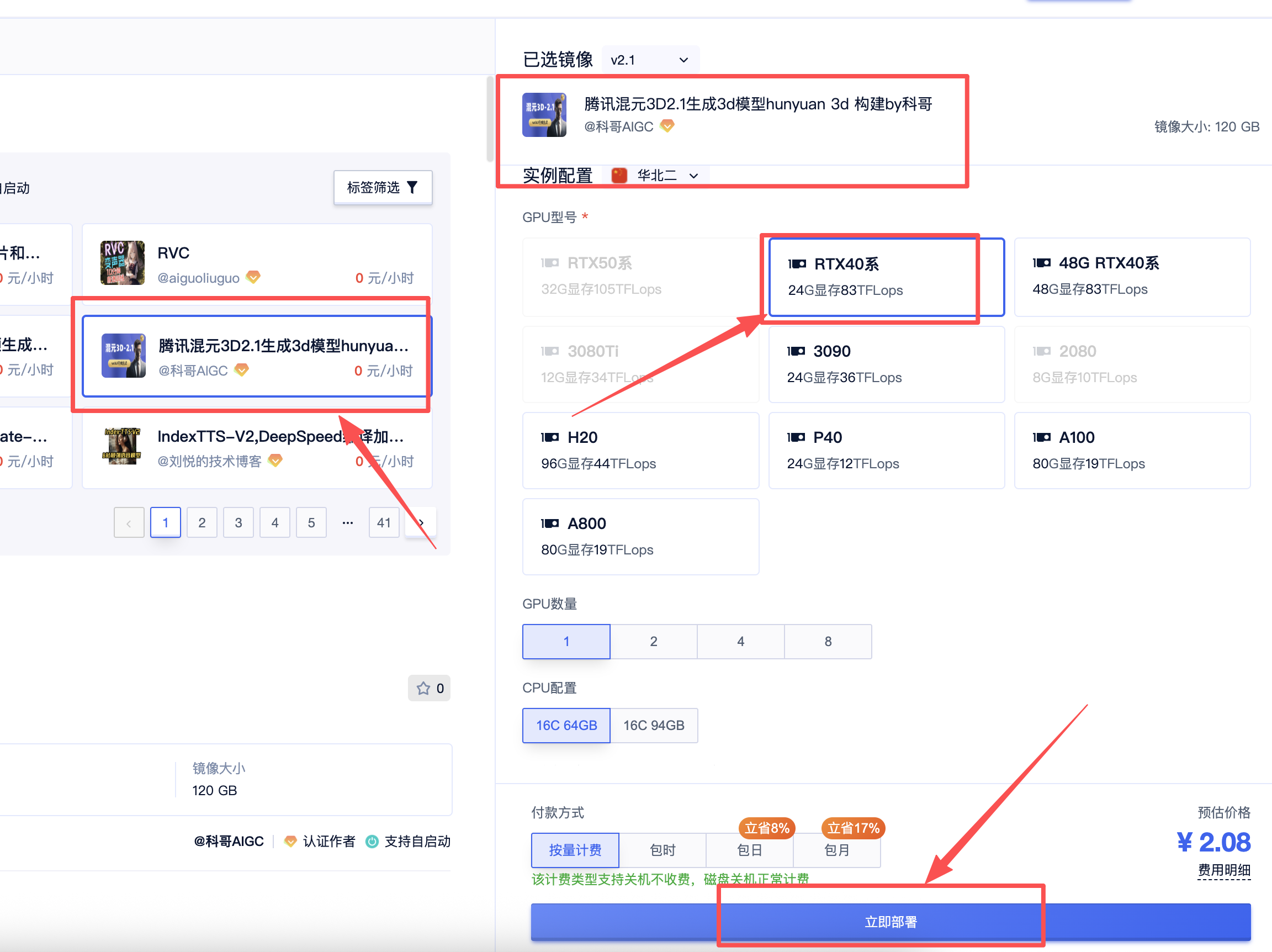
2、实例创建后,选择Jupyterlab打开

启动应用
1、打开jupyter左侧的启动器:
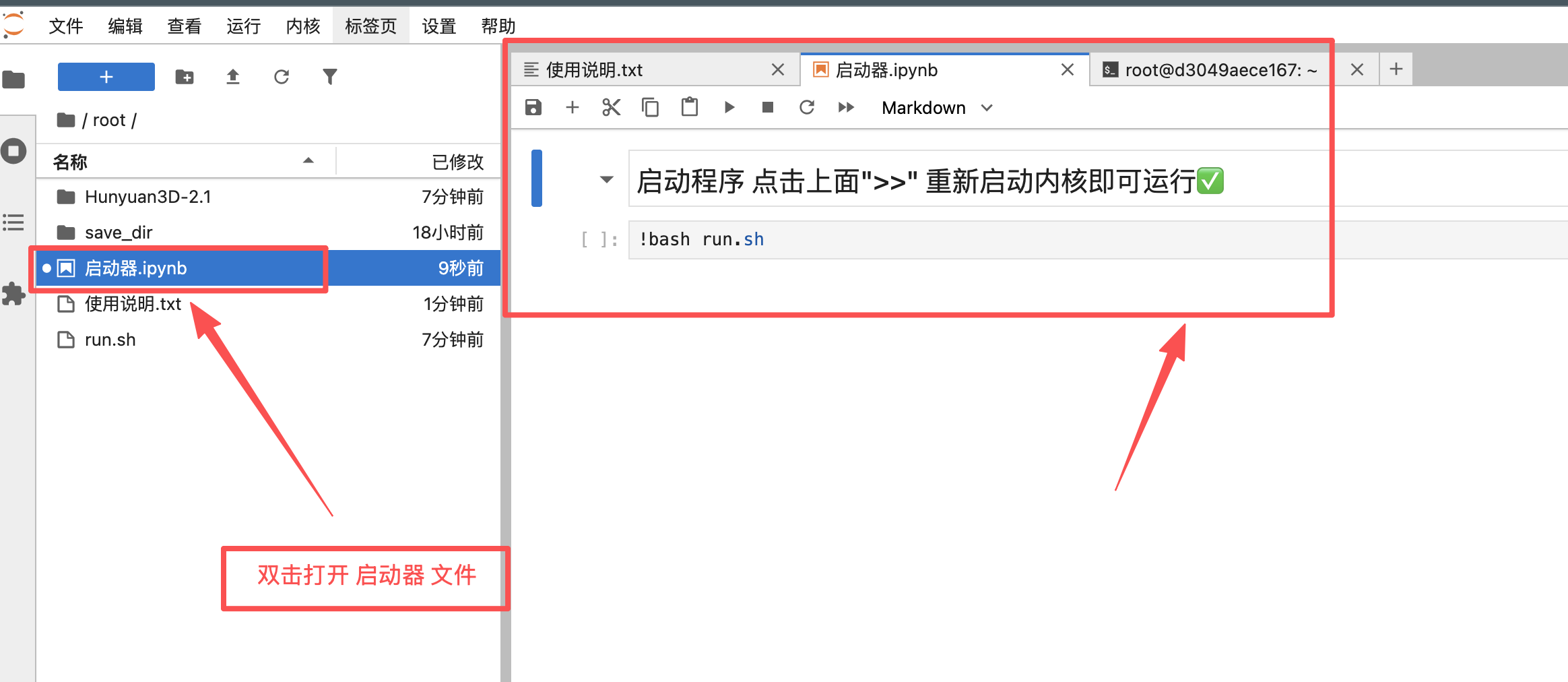
2、点击启动双箭头启动按钮:
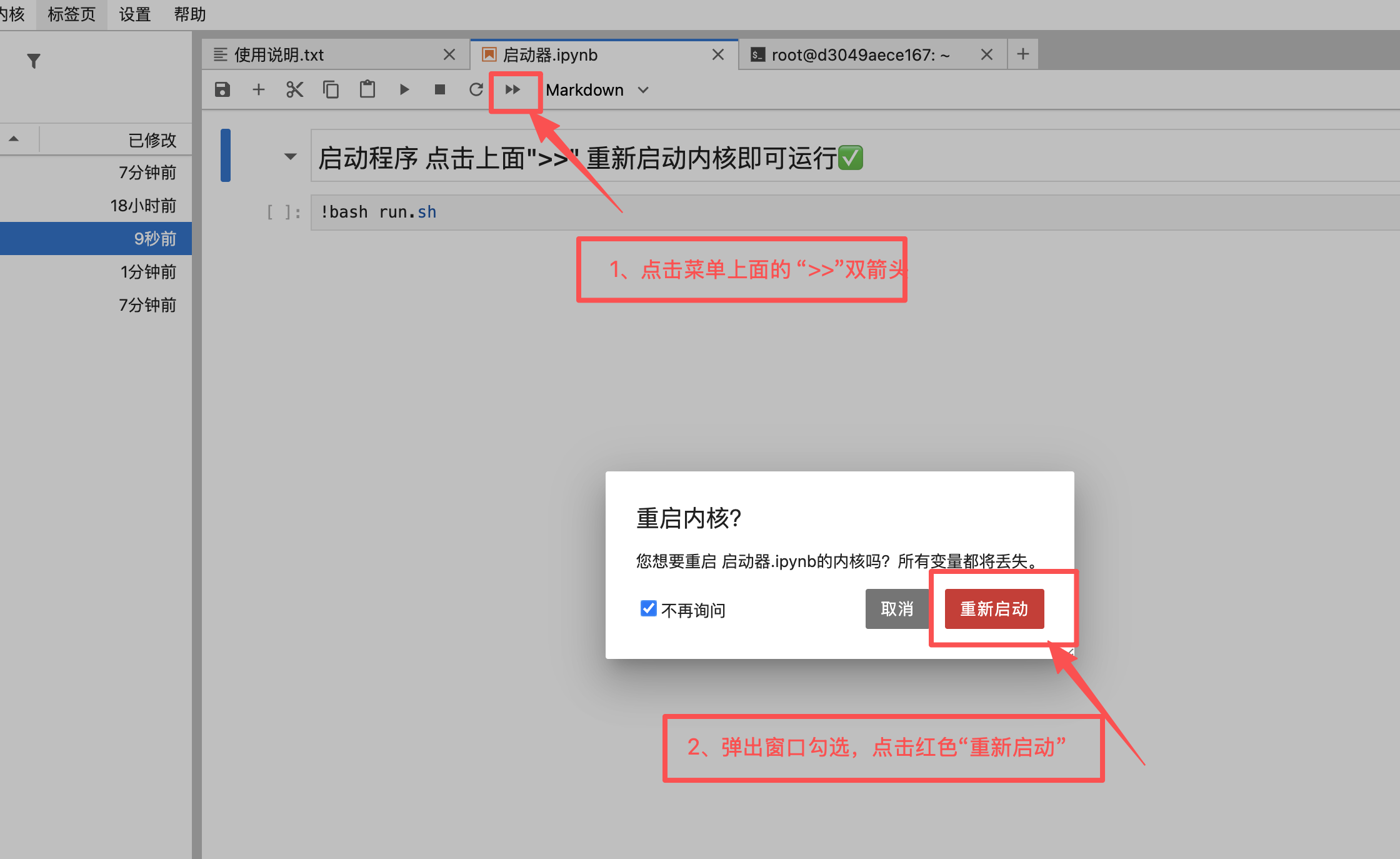
3、查看启动进度,运行完成后返回控制台打开SD-WebUI
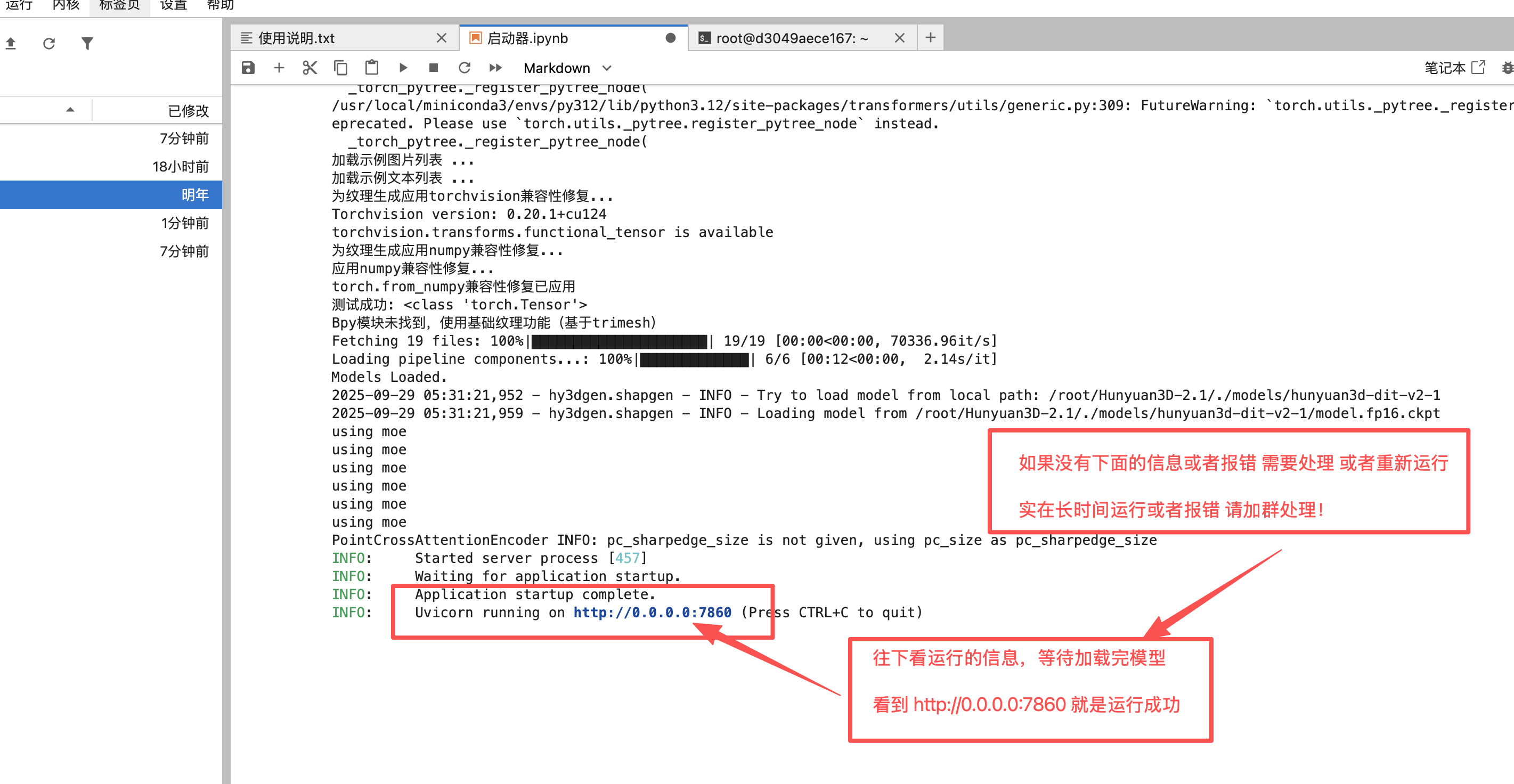
4、返回控制面板打开“SD-WebUI”
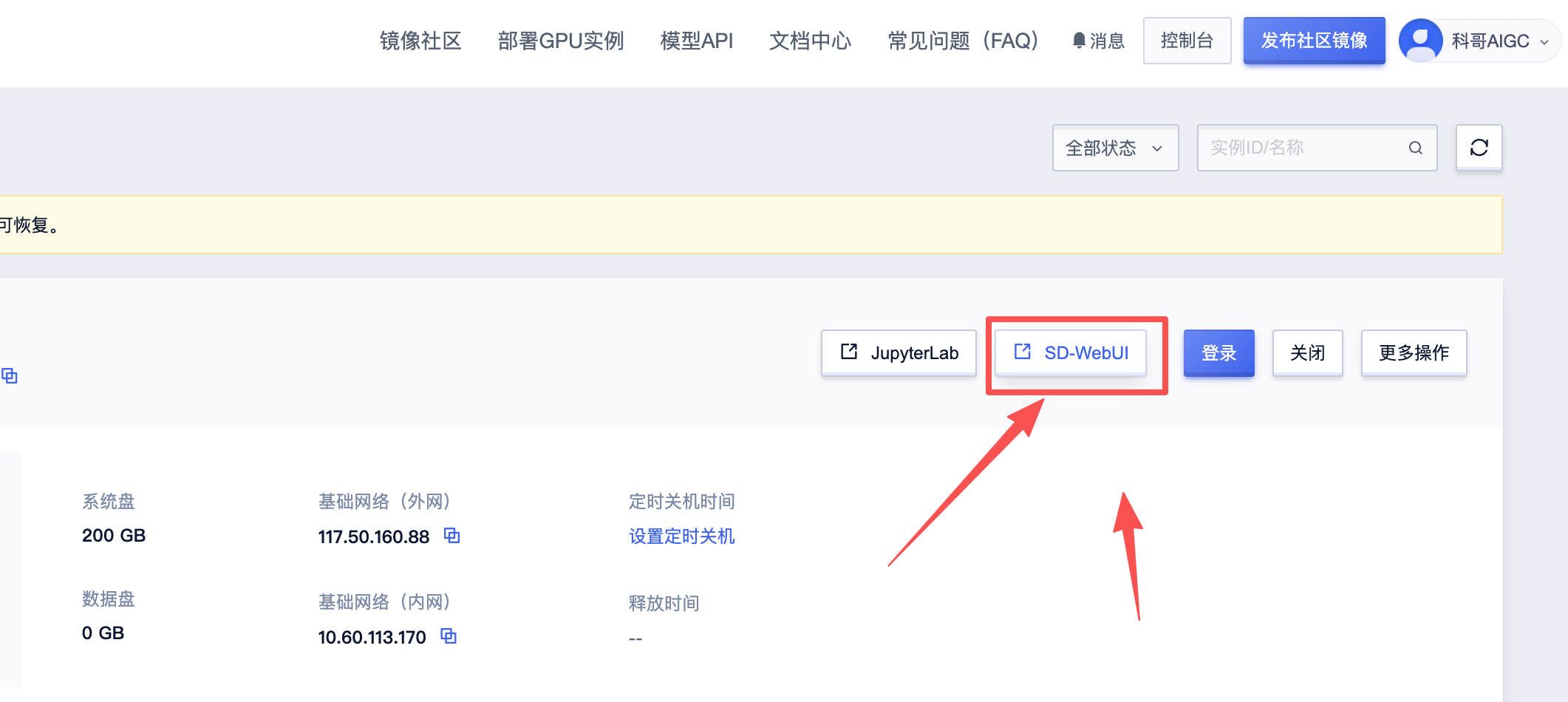
SD-WebUI运行使用界面截图
bug反馈可以加入科哥专属群交流➕ 广告勿进!

更多高级指令,可以进入jupyterlab,自行操作,例如:
- 查看进程:
ps -ef |grep python
- 终止进程:
kill -9 pid
- 重启程序:
cd /root && bash run.sh
有bug请微信科哥或加群: 312088415
科哥在UCloud镜像列表【不断更新中】:
-
https://kege-aigc.feishu.cn/docx/L3FVdQl7kom8Ckx7QiicQj2VnEd
-
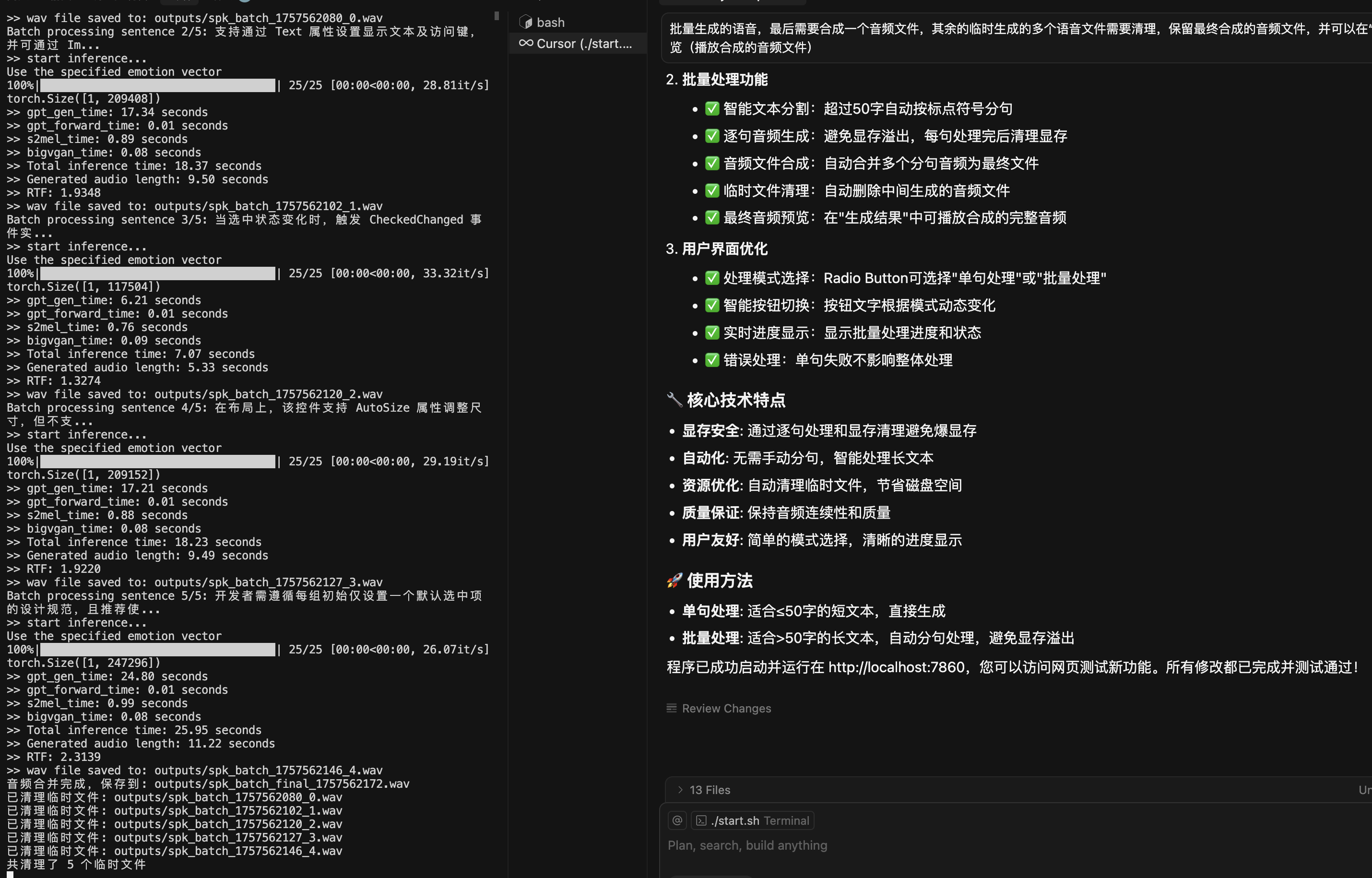
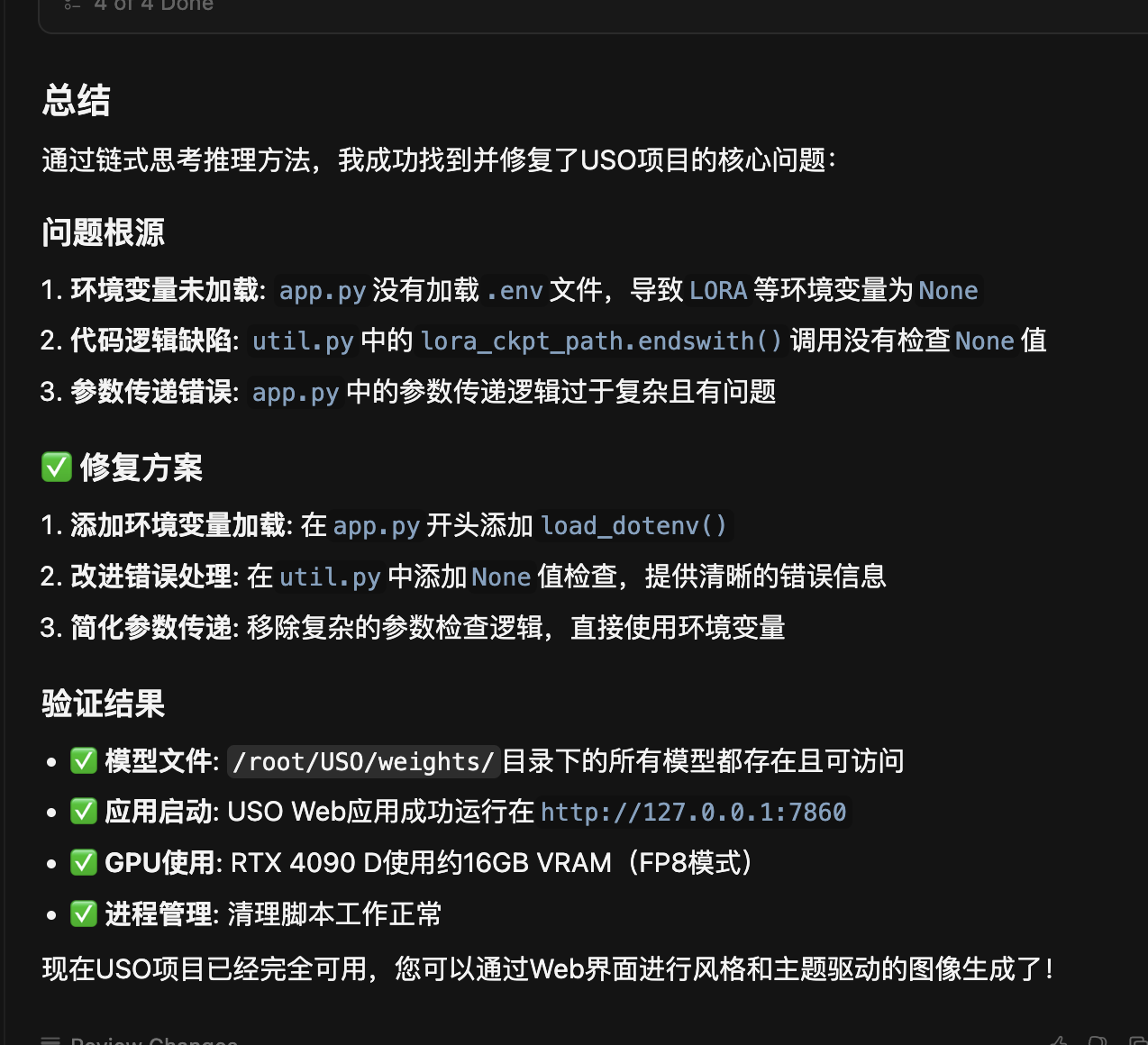
科哥已经借助ai工具【claude code cli】,在线云端和本地修复,重写很多ai开源应用
-
效率非常给力!
-
修复一般的开源应用简直就是开挂了一样,需要修复和搭建ai应用欢迎联系!
- AI数字人直播卖货欢迎来了解: https://kege-aigc.feishu.cn/docx/G271dgZr1o8CvMx9KKrcRuuonDf
@鸡你太美 认证作者
认证作者
认证作者

镜像信息
已使用95 次
运行时长
126 H
镜像大小
130GB
最后更新时间
2026-04-27
支持卡型
RTX40系20803080Ti309048G RTX40系2080TiH20A800P40A100RTX50系V100S
+12
框架版本
CUDA版本
12.8
应用
JupyterLab: 8888
版本
v1.1
2026-04-27