MOSS TTSD + Qwen3,自动生成完整语音播客(PodCast)
MOSS-TTSD结合Qwen3-30B-A3B-Instruct-2507,自动生成完整语音播客(PodCast),初始化之后,等待服务启动,大概2分钟左右,然后点击 SD-WEBUI 按钮即可
 51
510元/小时
v1.0
MOSS-TTSD自动生成语音播客
镜像简介
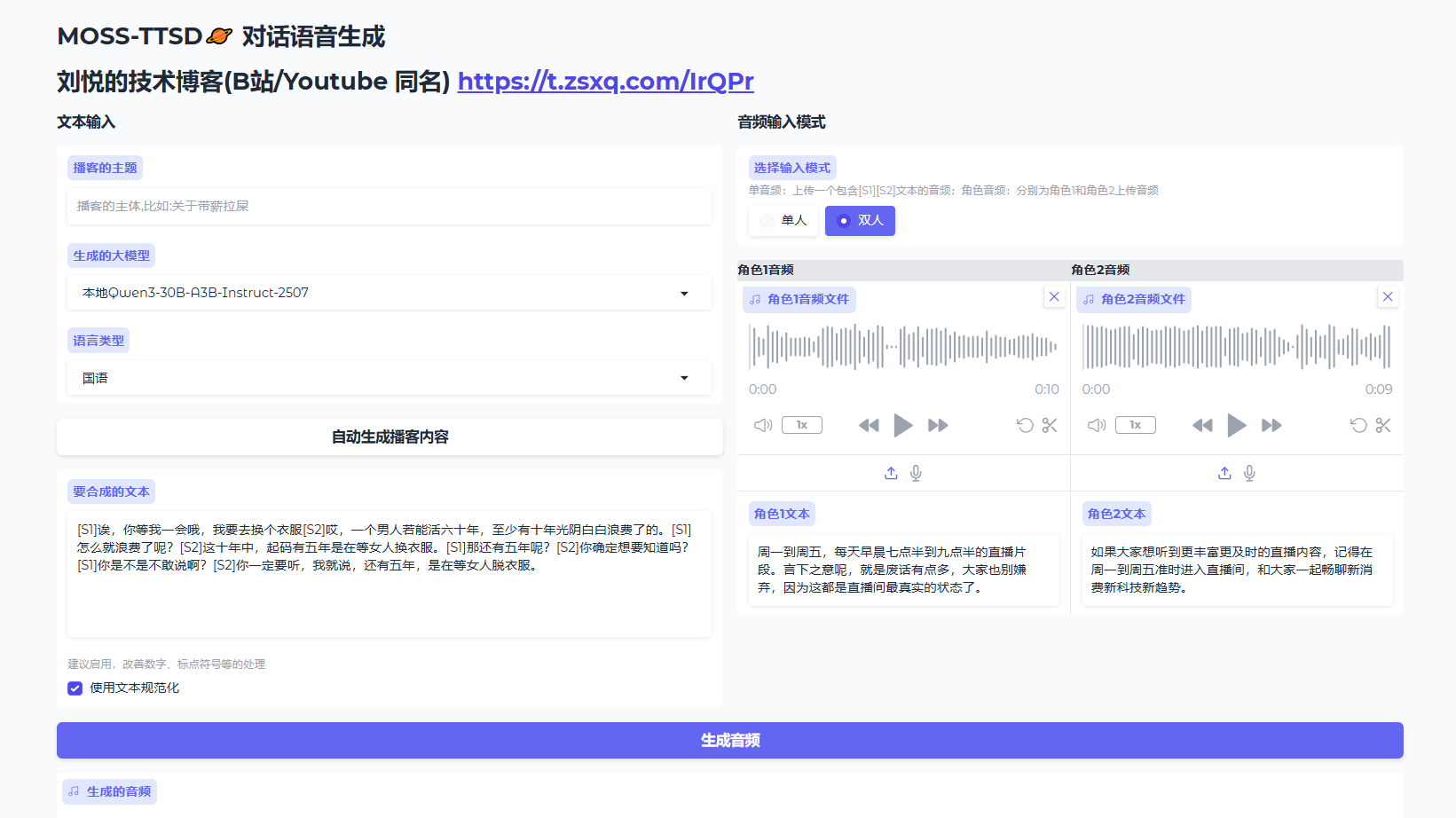
本镜像集成MOSS-TTSD语音合成与Qwen3-30B大语言模型,支持从主题构思、文稿生成到高质量语音合成的完整播客自动化生产。适用于个人创作者、媒体机构及内容团队快速制作专业级播客节目,显著降低内容制作门槛与时间成本,提供高效、拟真的一站式AI播客生成体验。 MOSS-TTSD结合Qwen3-30B-A3B-Instruct-2507,自动生成完整语音播客(PodCast)
使用教程
1、该镜像支持自启动,实例部署后,等待服务启动,大概2分钟。然后在控制台点击 SD-WebUI 按钮即可访问

2、可以直接点击生成音频按钮,生成播客音频。也可以输入播客主体,由大模型生成对应的播客内容,然后点击生成音频按钮
刘悦的镜像交流官方社群

@刘悦的技术博客 认证作者
认证作者
认证作者
镜像信息
已使用161 次
运行时长
256 H
 支持自启动
支持自启动镜像大小
80GB
最后更新时间
2026-02-02
支持卡型
RTX40系20803080Ti309048G RTX40系2080TiH20A800P40A100RTX50系V100S
+12
框架版本
CUDA版本
12.8
应用
JupyterLab: 8888
版本
v1.0
2026-02-02