mega-tts3无须官方npy文件 几秒音频克隆情感一致的声音字节开源 构建by科哥
mega-tts3无须官方npy文件 几秒音频克隆情感一致的声音
 4
40元/小时
v3.0
mega-tts3镜像使用教程
镜像简介
本镜像搭载开源的Mega-TTS3语音克隆系统,无需官方NPY文件,仅凭几秒钟的音频样本即可快速复刻目标音色,并保持情感表达的一致性。适用于虚拟人配音、个性化语音生成、有声内容创作及语音交互开发等场景,为用户提供便捷、高效且高拟真的本地化语音克隆解决方案。
已经设置开机运行,【全部模型已经离线,开机即用!】加载运行需要一定时间
bug反馈可以入科哥专属群交流!

使用流程
1、创建实例,实例启动完成,加载完毕模型后,在控制台打开【webui】

2、进入【webui】使用界面;
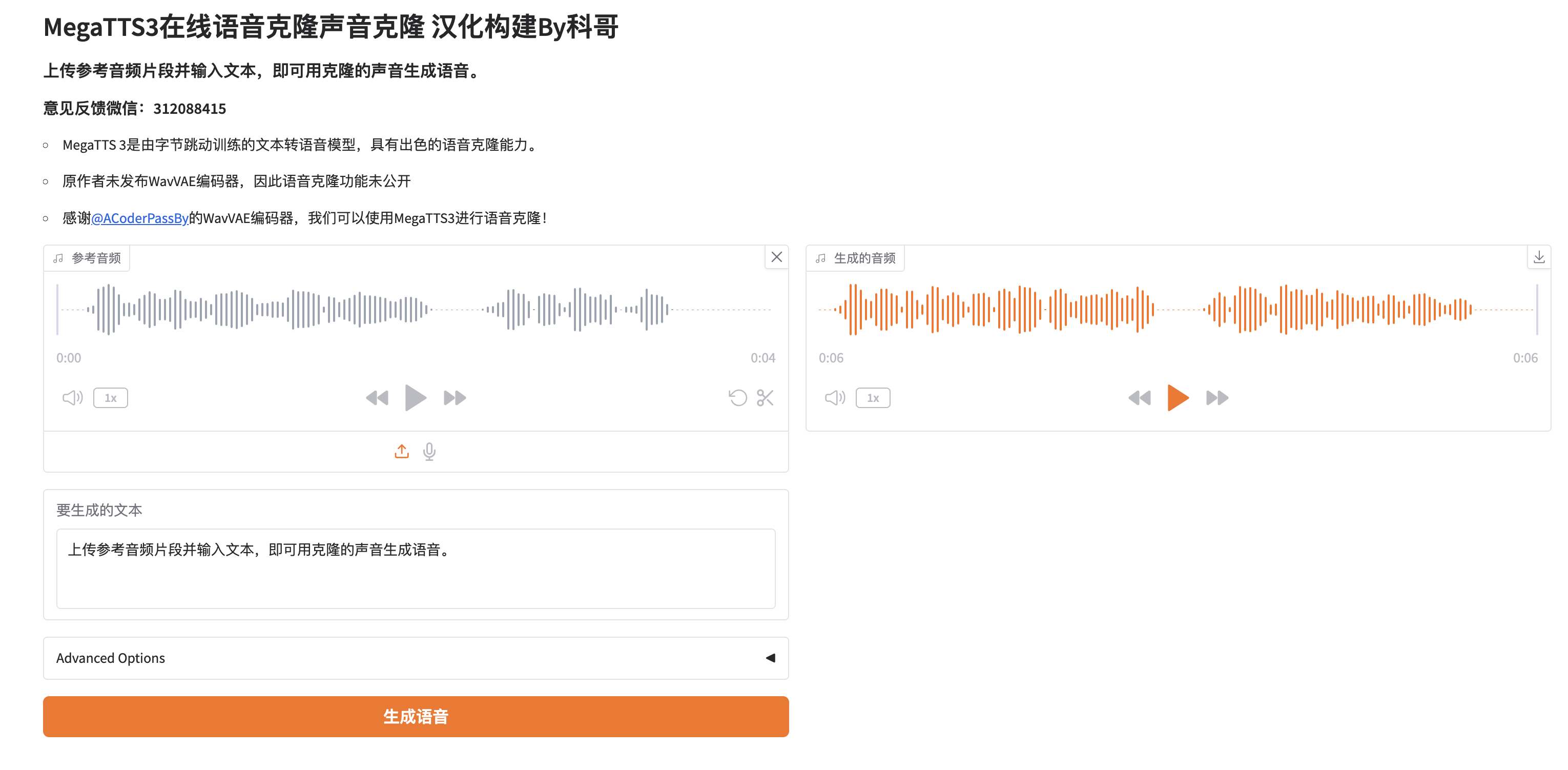
2、卡顿时候,在控制台,实例【..】那里,点击【重启】,释放资源,等待完成启动,再次打开 【webui】即可进入使用界面;
3、更多高级指令,可以进入jupyterlab,自行操作,例如:
查看进程:
ps -ef |grep python
终止进程:
kill -9 pid
官方更新源码在这里: https://huggingface.co/spaces/mrfakename/MegaTTS3-Voice-Cloning https://github.com/bytedance/MegaTTS3
WavVAE模型: https://modelscope.cn/models/ACoderPassBy/MegaTTS-SFT
有bug请微信科哥: 312088415
mega-tts3通过几秒音频克隆声音 字节开源
@鸡你太美 认证作者
认证作者
认证作者

镜像信息
已使用58 次
运行时长
436 H
 支持自启动
支持自启动镜像大小
60GB
最后更新时间
2026-04-27
支持卡型
RTX40系20803080Ti309048G RTX40系2080TiH20A800P40A100RTX50系V100SV100S
+13
框架版本
CUDA版本
12.4
应用
JupyterLab: 8888
版本
v3.0
2026-04-27