 6
6需要48gb及以上显存运行
运行界面截图
LongCat-Video WebUI 用户使用手册
本文只讲怎么使用,不讲安装搭建。
1. 启动 WebUI
在项目根目录运行:
bash start_app.sh
脚本会自动做这些事:
- 激活
py312环境。 - 检查端口
7860。 - 如果
7860已被旧 WebUI 占用,直接结束旧进程。 - 等待端口释放。
- 启动 Gradio WebUI。
- 使用
0.0.0.0:7860对外监听。 - 使用默认档位
quality_48gb。
启动后浏览器访问:
http://服务器IP:7860
本机访问:
http://127.0.0.1:7860
2. 默认运行档位
默认档位是 quality_48gb。
这个档位用于单卡 48GB 生产运行:
- 分辨率:
480p - 文生视频尺寸:
480x832 - 视频帧数:
77 - 采样步数:
30 - CFG:
4.0 - 关闭
torch.compile - 启用模型分阶段 CPU offload
- 基础视频默认不启用 Distill
- Avatar v1.5 默认启用 Distill + INT8
注意:
- 这个档位会检查总显存和空闲显存。
- 显存判断带少量容差。
- 例如 48GB 显卡在系统中显示为约 47GB,总显存 47GB、空闲 46GB 这类情况会放行。
- 容差只解决显存显示误差,不保证所有生产参数都不 OOM。
- 部分参数在界面中不可编辑,这是生产档固定行为。
legacy_full才保留原始93帧流程。
实测经验:
- 单卡 RTX 4090 上,
480x832 / 93帧 / 50步原始流程可能达到显存峰值并 OOM;当前默认生产档已改为480x832 / 77帧 / 30步。 - 当前默认生产档已降为
77帧,并启用分阶段 CPU offload,优先规避 48GB 单卡 OOM。 - 如果生产档 OOM,优先停止其他 GPU 任务,再点击“释放模型显存”。
- 仍然 OOM 时,建议使用快速预览/冒烟参数确认链路,或改用更大显存/多 GPU。
3. 页面结构
WebUI 顶部是功能标签页:
- 文生视频
- 图生视频
- 视频续写
- 长视频生成
- 交互式分段视频
- Avatar 单音频
- Avatar 多音频
- 模型下载/环境状态
每个生成页右侧都有:
- 输出视频预览
- 下载文件
- 状态信息
生成结果默认保存到:
outputs/
文件名格式类似:
outputs_20260524153022_t2v.mp4
4. 模型缓存与显存释放
WebUI 会缓存当前正在使用的推理模型。
规则:
- 下一次点击生成时,如果模型配置相同,直接复用已加载模型。
- 如果模型配置不同,先等待当前推理结束。
- 当前推理结束后,WebUI 会卸载旧模型、清理 CUDA 缓存,再加载新模型。
- Base 视频模型和 Avatar 模型互相切换时,也会触发旧模型卸载。
- 推理过程中不会卸载正在使用的模型,避免 device mismatch 或生成失败。
会触发重新加载的常见情况:
- 从基础视频任务切到 Avatar 任务。
- 从 Avatar 单音频切到 Avatar 多音频。
- 切换 Avatar v1.0 / v1.5。
- 切换 INT8、Distill、模型目录或 compile 配置。
“释放模型显存”按钮:
- 会手动释放当前 WebUI 缓存模型。
- 释放后下一次生成会重新加载模型。
- 显存紧张或切换任务后想强制清空时使用。
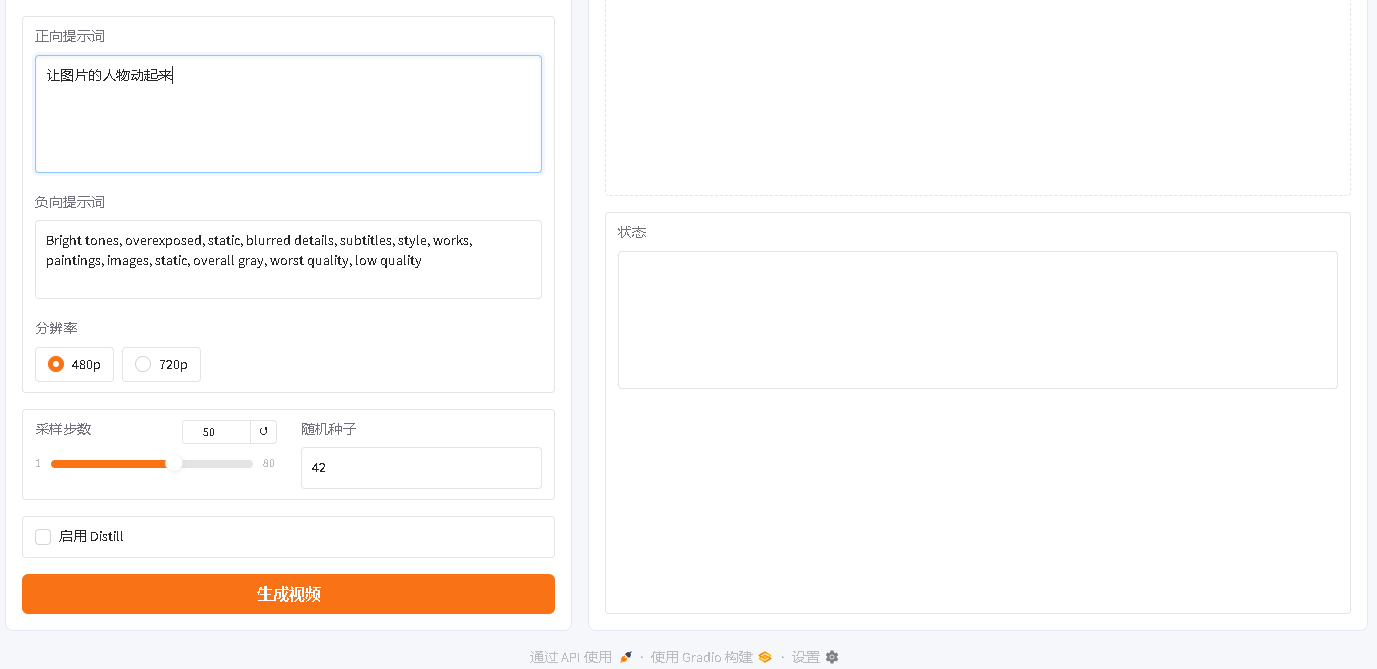
5. 文生视频
用途:只输入文字,生成视频。
操作:
- 打开“文生视频”。
- 填写“正向提示词”。
- 负向提示词可以保留默认值。
- 设置随机种子,默认
42。 - 点击“生成视频”。
- 等待右侧状态显示完成。
- 在右侧预览或下载视频。
提示词建议:
- 写清主体。
- 写清动作。
- 写清场景。
- 写清镜头风格。
- 写清光线和氛围。
示例:
一名年轻女性站在雨后的城市街道上,手持透明雨伞,慢慢转身看向镜头,霓虹灯反射在地面,电影感,真实摄影风格。
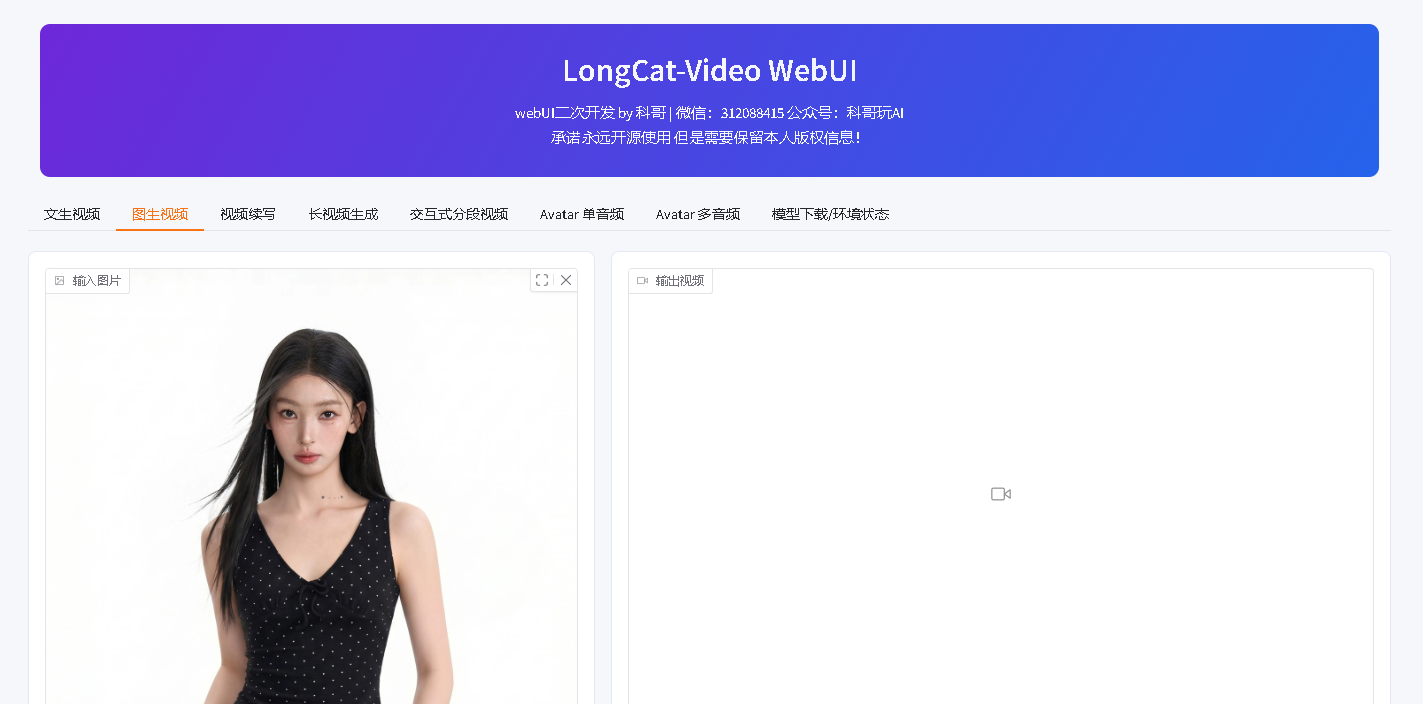
6. 图生视频
用途:上传一张图片,让图片动起来。
操作:
- 打开“图生视频”。
- 上传输入图片。
- 填写正向提示词,描述图片里的人物、物体和动作。
- 负向提示词可以保留默认值。
- 设置随机种子。
- 点击“生成视频”。
- 在右侧预览或下载结果。
建议:
- 图片主体清晰。
- 人物脸部不要太小。
- 提示词里的动作不要过猛。
- 想保持原图风格时,提示词要描述原图场景。
7. 视频续写
用途:上传一段已有视频,继续生成后续内容。
操作:
- 打开“视频续写”。
- 上传输入视频。
- 填写续写提示词。
- 负向提示词可以保留默认值。
- 设置随机种子。
- 点击“生成视频”。
说明:
- 系统会读取输入视频帧率。
- 内部会按约 15fps 采样输入视频。
- 默认使用前后文缓存增强连续性。
建议:
- 输入视频不要太长。
- 画面主体要稳定。
- 提示词要承接原视频,不要突然换主体。
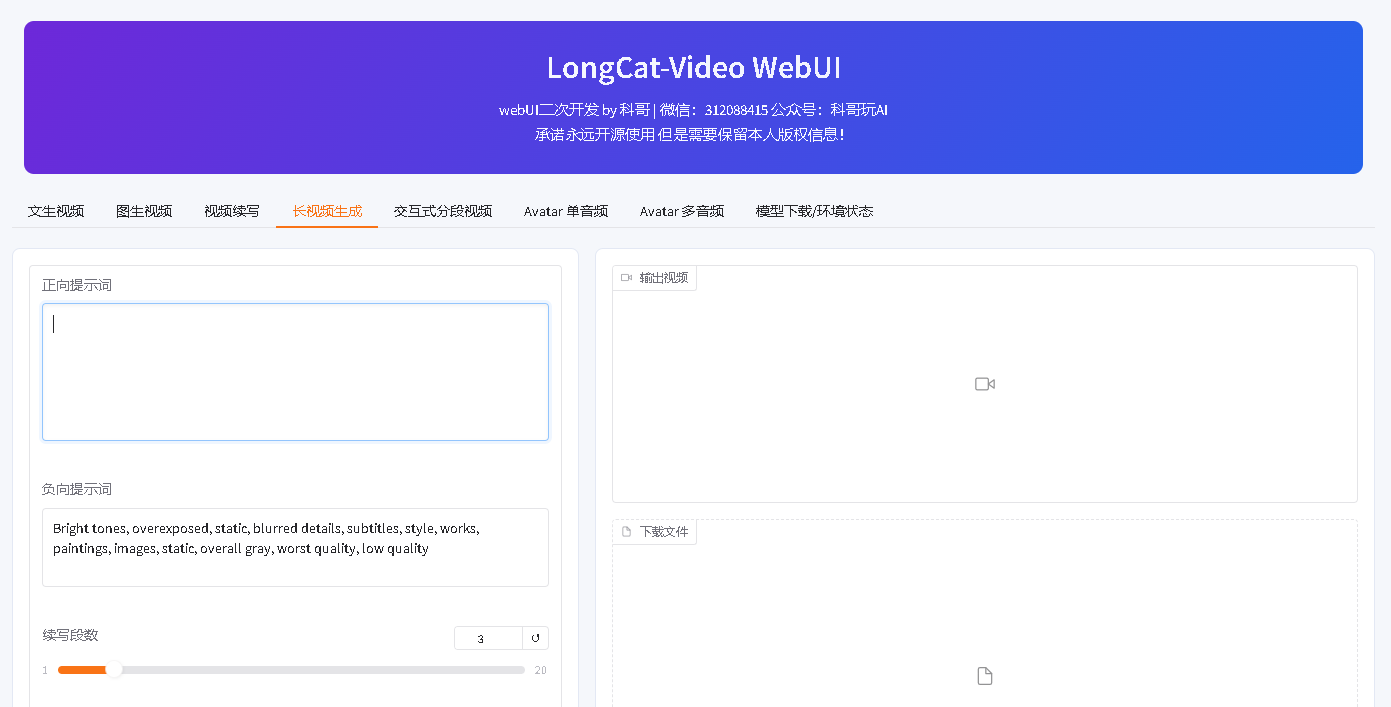
8. 长视频生成
用途:先生成第一段,再用视频续写方式生成更多段。
操作:
- 打开“长视频生成”。
- 填写正向提示词。
- 选择“续写段数”。
- 设置随机种子。
- 点击“生成长视频”。
说明:
- 第一段走文生视频。
- 后续段落走视频续写。
- 每段之间会复用条件帧,减少断裂。
建议:
- 续写段数越多,耗时越长。
- 提示词应描述持续动作,不要只写静态画面。
- 如果出现漂移,减少段数。
9. 交互式分段视频
用途:给每一段写不同提示词,生成有剧情变化的视频。
操作:
- 打开“交互式分段视频”。
- 在“分段提示词,每行一个”里输入多行提示词。
- 至少输入 2 行。
- 设置负向提示词和随机种子。
- 点击“生成分段视频”。
示例:
一名宇航员站在红色沙漠中,看向远处的基地。
宇航员慢慢走向基地,身后扬起尘土。
基地大门打开,蓝色灯光照亮宇航员的面罩。
说明:
- 第一行用于生成第一段。
- 后续每一行用于续写下一段。
- 每一段共享同一个随机生成器。
10. Avatar 单音频
用途:一个人物,根据一段音频生成说话视频。
操作:
- 打开“Avatar 单音频”。
- 选择模型版本,推荐
avatar-v1.5。 - 选择模式:
ai2v:音频 + 图片生成视频。at2v:音频 + 文本生成视频。
- 填写 Prompt。
- 上传人物音频。
ai2v模式下上传参考图。- 设置段数和随机种子。
- 点击“生成 Avatar”。
quality_48gb 档下:
avatar-v1.5会自动使用 Distill。avatar-v1.5会自动使用 INT8。- 相关控件不可编辑。
Prompt 建议:
- 写人物外貌。
- 写人物状态。
- 写背景环境。
- 明确人物在说话。
示例:
一名年轻男性坐在办公室桌前,自然地面对镜头说话,穿白色衬衫,背景是整洁的书架,真实摄影风格。
11. Avatar 多音频
用途:两个人物或两个音频流驱动同一画面。
操作:
- 打开“Avatar 多音频”。
- 选择模型版本,推荐
avatar-v1.5。 - 上传参考图。
- 上传人物 1 音频。
- 上传人物 2 音频。
- 选择音频模式。
- 填写 Prompt。
- 点击“生成 Avatar”。
音频模式:
para:并行说话,适合两段长度接近的音频。add:顺序拼接,通常人物 1 先说,人物 2 后说。
高级 bbox:
- 可选。
- 用 JSON 指定人物区域。
- 不填时系统会按左右半区估算。
格式示例:
{
"person1": [100, 80, 500, 360],
"person2": [100, 420, 500, 700]
}
12. 使用 JSON 输入
Avatar 页支持上传 JSON。
上传 JSON 后,界面里的部分输入会被 JSON 内容替代。
单音频 JSON 示例:
{
"prompt": "一个人在镜头前自然说话",
"cond_image": "/path/to/person.png",
"cond_audio": {
"person1": "/path/to/audio.wav"
}
}
多音频 JSON 示例:
{
"prompt": "两个人坐在沙发上交谈",
"cond_image": "/path/to/two_people.png",
"cond_audio": {
"person1": "/path/to/audio1.wav",
"person2": "/path/to/audio2.wav"
},
"audio_type": "para"
}
13. 模型下载/环境状态
打开“模型下载/环境状态”。
可以看到:
- 基础模型路径状态。
- Avatar 模型路径状态。
- Avatar 1.5 模型路径状态。
- 缺失的必要文件。
- 缺失的可选文件。
按钮:
- “刷新状态”:重新检查模型目录。
- “释放模型显存”:释放当前 WebUI 缓存的模型。
如果生成过多个任务后显存压力变大,先点“释放模型显存”。 正常连续使用时不必每次点击。相同模型会复用,不会重复加载。
14. 快速推理自检
如果要确认模型、GPU、依赖、输出视频链路是否正常,可以运行全量冒烟脚本:
python scripts/run_inference_smoke.py
脚本会顺序跑:
- 文生视频
- 图生视频
- 视频续写
- 长视频生成
- 交互式分段视频
- Avatar 单音频
- Avatar 多音频
输出目录:
outputs/smoke/
日志目录:
outputs/logs/
已生成视频示例:
outputs/smoke/t2v/output_t2v.mp4
outputs/smoke/i2v/output_i2v.mp4
outputs/smoke/vc/output_vc.mp4
outputs/smoke/long_video/output_long_video_1.mp4
outputs/smoke/interactive_video/output_interactive_1.mp4
outputs/smoke/avatar_single/ai2v_demo_1.mp4
outputs/smoke/avatar_multi/ai2v_demo_1.mp4
说明:
- 冒烟脚本会使用低显存参数。
- 目标是快速确认“能不能跑通并产出 mp4”。
- 这不是生产画质参数。
- 脚本会检查 mp4 是否生成、是否为空、是否能被
ffprobe读取。 - 任一任务失败会立即停止,并保留对应日志。
15. WebUI 和冒烟脚本的区别
WebUI 不会完全照搬冒烟脚本参数。
WebUI 对齐的是:
- 模型目录检查
- 输入文件检查
- 底层推理入口
- 错误处理
- 输出视频路径
WebUI 不对齐的是:
--smoke_only- 低分辨率
- 少帧数
- 少采样步数
原因:
- WebUI 是给正常推理使用。
- 冒烟脚本是给连通性测试使用。
- 冒烟脚本生成的视频能证明链路可用,但不代表最终画质。
如果只是想快速确认环境是否可用,先跑冒烟脚本。
如果要正式出片,用 WebUI。
16. 常见 FQA
端口 7860 被占用怎么办?
直接运行:
bash start_app.sh
脚本会自动结束占用 7860 的旧进程,不需要手动确认。
为什么外部机器打不开 WebUI?
确认访问的是:
http://服务器IP:7860
不是:
http://127.0.0.1:7860
还要确认服务器防火墙、安全组放行了 7860。
为什么提示显存不足?
默认 quality_48gb 档要求接近 48GB 的总显存和空闲显存。
如果 GPU 小于 48GB,或显存已被其他任务占用,会直接拒绝生成。
当前判断允许少量容差:
- 47GB 总显存、46GB 可用:通常放行。
- 45GB 总显存、44GB 可用:拒绝。
- 48GB 总显存但只剩 12GB 可用:拒绝。
处理:
- 停止其他占用显存的任务。
- 点击“释放模型显存”。
- 使用 48GB 或更大显存 GPU。
为什么显存检查放行后仍然 OOM?
显存检查只判断能不能尝试运行。
真实推理峰值还受这些影响:
- 分辨率
- 帧数
- 采样步数
- 是否 refine
- 是否
torch.compile - 是否 INT8
- 是否有其他进程抢显存
如果 OOM:
- 先点“释放模型显存”。
- 停掉其他 GPU 程序。
- 用冒烟脚本确认环境链路。
- 正式出片时降低参数或换更大显存。
为什么第一次生成慢,第二次同类任务快?
第一次会加载模型到显存。
第二次如果模型配置相同,会复用缓存模型,不重新加载。
如果切换到不同模型,WebUI 会先卸载旧模型,再加载新模型,所以会再次变慢。
切换任务时会不会把正在推理的模型卸掉?
不会。
WebUI 会等待当前推理结束,再卸载旧模型并加载新模型。
为什么有些参数不能改?
默认 quality_48gb 是生产档。
为了稳定运行,分辨率、步数、Distill、INT8 等部分参数会被固定。
生成结果在哪里?
在项目目录:
outputs/
WebUI 右侧也会显示下载文件。
冒烟脚本结果在:
outputs/smoke/
冒烟脚本日志在:
outputs/logs/
文生视频提示 prompt 不能为空?
正向提示词必须填写。
只填负向提示词不能生成。
交互式分段视频为什么报错?
至少需要两行有效提示词。
每一行是一段。
Avatar 单音频必须上传什么?
最少需要:
- Prompt
- 音频
ai2v 模式建议同时上传参考图。
Avatar 多音频必须上传什么?
最少需要:
- Prompt
- 参考图
- 至少一个人物音频
两个音频都上传,效果更符合多人物对话。
para 和 add 怎么选?
- 两个人同时或交替说话:选
para。 - 人物 1 说完,人物 2 再说:选
add。
FlashAttention 有没有启用?
基础视频模型默认由模型配置启用 FlashAttention-2。
当前 48GB 生产档关闭的是 torch.compile,不是 FlashAttention。
想恢复原始完整流程怎么办?
命令行入口可用:
--production_profile legacy_full
WebUI 默认不建议普通用户切换。生产使用推荐保持 quality_48gb。
冒烟脚本通过,WebUI 还可能 OOM 吗?
可能。
冒烟脚本使用低显存参数,只证明环境、模型、推理链路、视频输出正常。
WebUI 默认生产档参数更高,显存峰值更高。
Avatar 音频分离是否使用 GPU?
当前日志显示:
CUDAExecutionProvider not available in ONNXruntime
含义:
- PyTorch 推理会用 CUDA。
- ONNXRuntime 音频分离当前没有 CUDA Provider,会走 CPU。
这会影响音频分离速度,不代表视频生成没用 GPU。
 认证作者
认证作者
