MultiTalk数字人优化加速版本-无限时长-唱歌/说话数字人
MultiTalk数字人优化加速版本-2步采样,对精度有要求修改采样数为4或者8
 5
50元/小时
v1.1
MultiTalk 数字人优化加速版-无限时长
镜像简介
本镜像搭载MultiTalk数字人优化加速系统,支持生成无限时长的唱歌或说话数字人视频,显著提升生成速度与流畅度。适用于虚拟主播、内容创作、在线教育等场景,提供高效、稳定的数字人生成体验。
- MultiTalk数字人优化加速版本-2步采样-无限时长-唱歌/说话数字人,初始化后,等待服务启动,大概2分钟,随后点击SD-WEBUI即可
使用教程
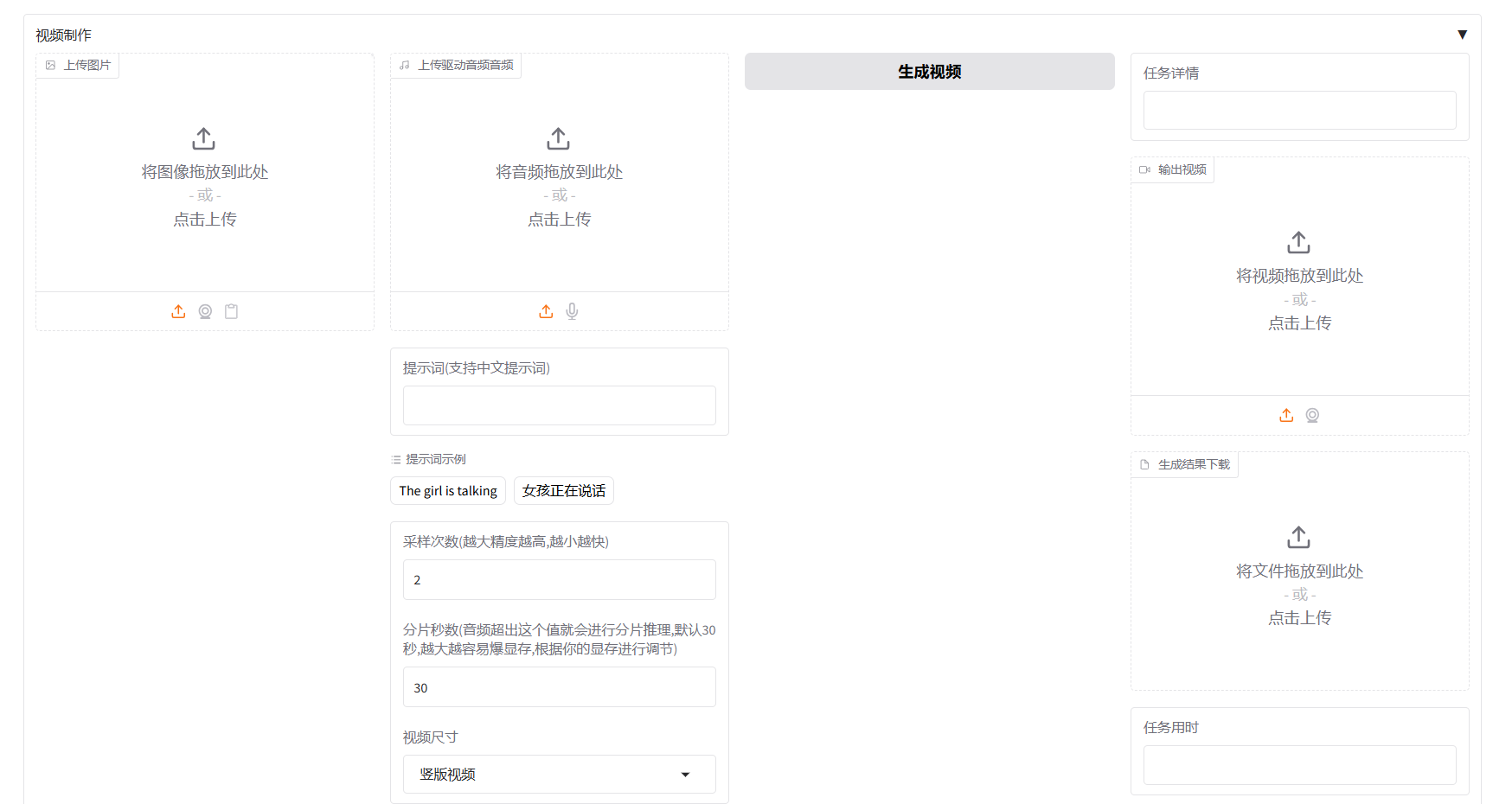
1、该镜像支持自启动,实例部署后,等待服务启动,大概2分钟。然后在控制台点击 SD-WebUI 按钮即可访问

2、上传驱动图片,上传驱动音频,然后点击生成数字人即可
刘悦的镜像交流官方社群

@刘悦的技术博客 认证作者
认证作者
认证作者
镜像信息
已使用130 次
运行时长
1437 H
 支持自启动
支持自启动镜像大小
170GB
最后更新时间
2026-02-02
支持卡型
RTX40系20803080Ti309048G RTX40系2080TiH20A800P40A100RTX50系V100SV100S
+13
框架版本
CUDA版本
12.8
应用
JupyterLab: 8888
版本
v1.1
2026-02-02