 0
0VoxCPM2 声音克隆系统webui开机即用 构建by科哥
bug反馈可以加入科哥专属群交流➕ 广告勿进!

-
已经设置开机运行 首次加载大模型时间比较久
-
1、打开 【WebUI】即可进入使用界面;
-
4、模型及源码更新地址:
-
有问题请微信科哥: 312088415
VoxCPM2 WebUI 用户使用手册
VoxCPM2 是来自面壁智能的多语言创意语音合成系统,支持声音设计、音色克隆和极致克隆三种模式。本手册指导你从打开页面到获得音频,全程操作。
一、启动应用
在终端执行以下命令启动应用(推荐使用 start_app.sh,它会自动清理端口和 GPU 残留进程):
bash start_app.sh
启动后终端会依次显示:
>>> Step 1/3 — 检查并释放端口 7860
>>> Step 2/3 — 清理 GPU 显存
>>> Step 3/3 — 启动 VoxCPM2 主程序
[start.sh] Backend is ready (Xs elapsed).
[start.sh] Starting Gradio WebUI on 0.0.0.0:7860 ...
看到 Backend is ready 后,打开浏览器访问:
http://<服务器IP>:7860
首次启动模型加载需要 1~2 分钟,后续热启动较快。
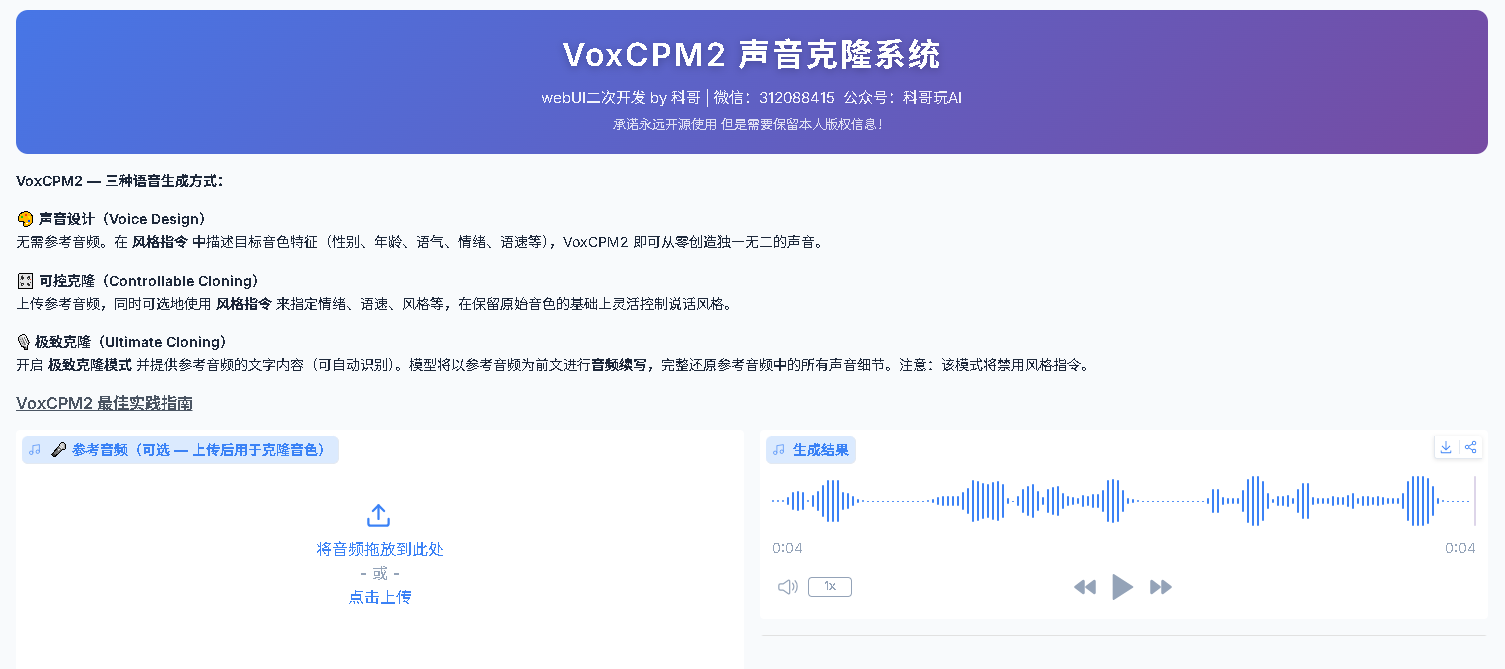
二、页面布局
打开页面后,你会看到左右两栏布局:
┌─────────────────────────────────────────────────────┐
│ VoxCPM Logo │
│ 使用说明简介 │
├──────────────────────┬──────────────────────────────┤
│ 左栏(输入区) │ 右栏(输出区) │
│ │ │
│ 🎤 参考音频 │ 生成结果(播放器) │
│ 🎙️ 极致克隆开关 │ │
│ 🎛️ 风格指令 │ 使用示例 & 方言指南 │
│ ✍️ 合成文本 │ │
│ ⚙️ 高级设置(折叠) │ │
│ 🔊 开始生成 按钮 │ │
└──────────────────────┴──────────────────────────────┘
三、三种使用模式
模式一:声音设计(Voice Design)
适合场景:不需要参考音频,从零创造一个新声音。
操作步骤:
-
参考音频 — 留空,不上传任何音频
-
风格指令 — 用文字描述你想要的声音特征,中英文均可
示例:年轻女性,温柔甜美,语速适中 示例:A deep baritone male voice, slow and authoritative 示例:暴躁中年男声,语速飞快,充满无奈 -
合成文本 — 输入要朗读的内容
-
点击 🔊 开始生成
模式二:可控克隆(Controllable Cloning)
适合场景:有一段参考音频,想克隆其音色,同时可以调整情绪/语速等风格。
操作步骤:
-
参考音频 — 点击上传区域选择音频文件,或点击麦克风图标录音
- 支持格式:WAV、MP3、M4A 等常见格式
- 时长限制:不超过 50 秒,推荐 5~30 秒的清晰录音
-
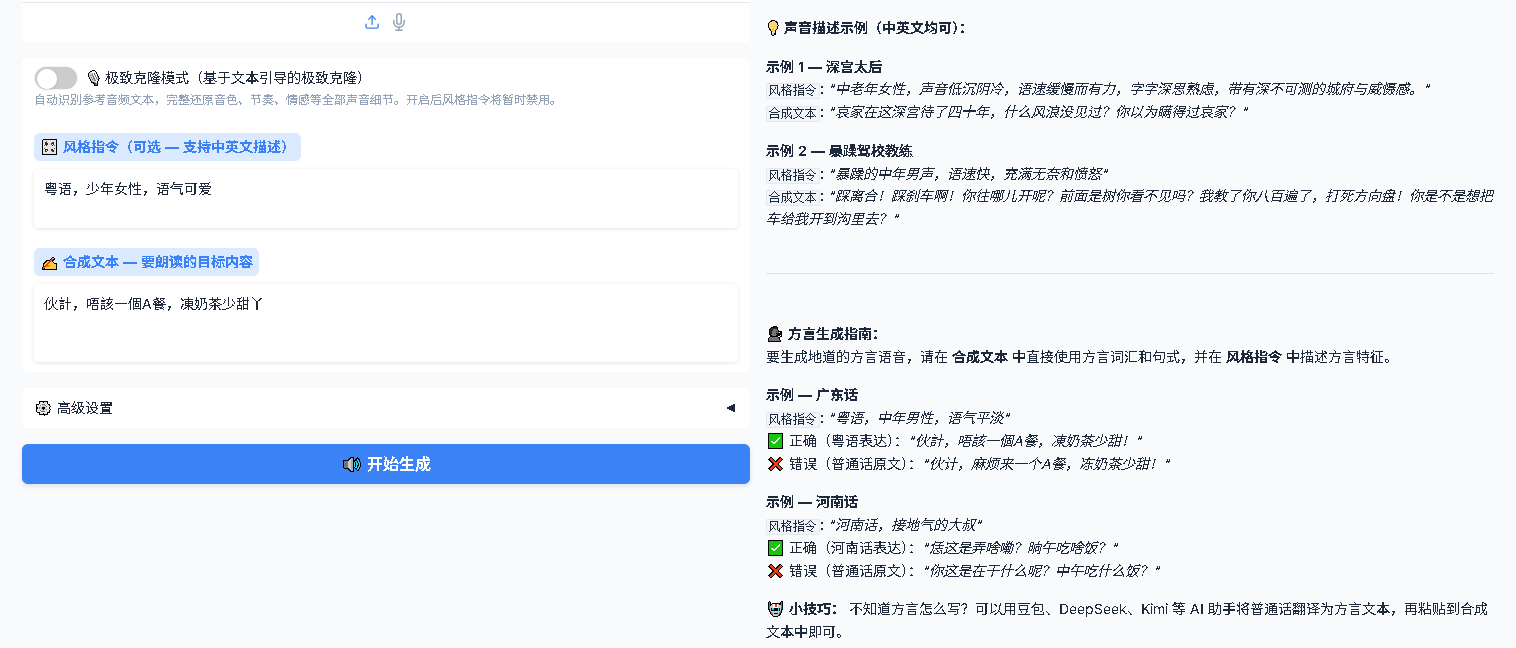
极致克隆模式 — 保持关闭状态(默认关闭)
-
风格指令(可选) — 在保留原始音色的基础上,叠加情绪/风格控制
示例:语速快一些,充满活力 示例:情绪低沉,带一点悲伤 -
合成文本 — 输入目标文本
-
点击 🔊 开始生成
模式三:极致克隆(Ultimate Cloning)
适合场景:需要最高精度地还原参考音频的音色、节奏、呼吸感等全部细节。
操作步骤:
-
参考音频 — 上传参考音频(要求同上)
-
开启极致克隆模式 — 点击 🎙️ 开关,切换为开启状态
-
参考音频文本 — 开关开启后,系统会自动对参考音频进行 ASR 语音识别,识别结果自动填入文本框。
- 等待几秒识别完成
- 识别结果可以手动编辑纠正,文本越准确,克隆效果越好
⚠️ 注意:该模式下风格指令自动禁用,若需要风格控制请改用可控克隆。
-
合成文本 — 输入目标文本
-
点击 🔊 开始生成
四、高级设置
点击 ⚙️ 高级设置 展开以下选项:
参考音频降噪增强
- 功能:使用 ZipEnhancer 对参考音频进行降噪,适合在嘈杂环境下录制的参考音频
- 建议:参考音频质量已经很好时无需开启,开启会增加约 5~10 秒的处理时间
文本规范化
- 功能:自动将文本中的数字、日期、符号转换为可朗读的形式
- 示例:
2024年5月1日→二零二四年五月一日;$100→one hundred dollars - 建议:文本含大量数字/符号时开启,纯自然语言文本可关闭
CFG 引导强度(1.0 ~ 3.0,默认 2.0)
| 数值 | 效果 |
|---|---|
| 1.0 ~ 1.5 | 生成风格更自由,音色变化更丰富 |
| 2.0 | 默认平衡值,推荐大多数场景 |
| 2.5 ~ 3.0 | 更严格贴合参考音色/风格指令,但自然度可能略降 |
五、获取生成结果
生成完成后,右栏会出现音频播放器:
- 播放:点击播放按钮直接试听
- 下载:点击播放器右侧下载图标保存到本地
所有生成的音频同时会自动保存在服务器的 outputs/ 目录,文件名格式:
outputs_20260608143022_a1b2c3.mp3
服务器端文件保留 7 天后自动清理。
六、方言与多语言
VoxCPM2 支持多种语言和方言,使用方言时需要在合成文本中直接使用方言词汇,普通话翻译过来的文字无法产生地道方言效果。
广东话示例:
- ✅ 合成文本:
伙計,唔該一個A餐,凍奶茶少甜! - ❌ 错误写法:
伙计,麻烦来一个A餐,冻奶茶少甜!
河南话示例:
- ✅ 合成文本:
恁这是弄啥嘞?晌午吃啥饭? - ❌ 错误写法:
你这是在干什么呢?中午吃什么饭?
💡 小技巧:不知道方言怎么写?可以用豆包、DeepSeek、Kimi 等 AI 助手将普通话翻译为方言文本,再粘贴到合成文本中。
七、风格指令写法参考
人物角色类
| 效果 | 风格指令示例 |
|---|---|
| 深沉女性 | 中老年女性,声音低沉阴冷,语速缓慢而有力,带有威慑感 |
| 暴躁教练 | 暴躁的中年男声,语速快,充满无奈和愤怒 |
| 温柔助手 | 年轻女性,声音温柔,语速适中,充满亲和力 |
| 正式播音 | 男性播音腔,字正腔圆,语速均匀,情绪稳定 |
情绪控制类
| 效果 | 风格指令示例 |
|---|---|
| 开心 | 活泼开朗,语速轻快,带有笑意 |
| 悲伤 | 声音略带哽咽,语速缓慢,情绪低落 |
| 激动 | 兴奋激动,语速加快,语调上扬 |
| 严肃 | 语气严肃认真,不带情绪波动 |
英文场景
A warm and friendly young female voice, speaking at a moderate pace
A deep authoritative male narrator, slow and deliberate
Excited sports commentator, fast-paced and energetic
八、常见问题 FAQ
Q:点击"开始生成"后一直转圈,没有结果?
正常情况。首次请求需要加载模型(约 30~60 秒)。后续请求通常在 10~30 秒内完成,具体取决于文本长度和服务器 GPU 性能。如果超过 5 分钟无响应,请检查服务器后端是否正常运行(查看
logs/backend.log)。
Q:上传参考音频后报错"参考音频太长了"?
参考音频时长限制为 50 秒以内。请裁剪音频后重试,推荐使用 5~20 秒的清晰片段。
Q:极致克隆模式下,ASR 自动识别的文字不准确怎么办?
直接在文本框中手动修改识别结果即可,文本越准确克隆效果越好。特别是人名、地名、专业词汇建议手动核对。
Q:生成的声音和参考音频差异很大?
建议:
- 参考音频尽量清晰,背景噪音少(或开启"参考音频降噪增强")
- 使用极致克隆模式(精度高于可控克隆)
- 适当提高 CFG 引导强度(调至 2.5~3.0)
- 参考音频时长在 5~30 秒为佳
Q:生成的声音有杂音或音质差?
检查参考音频质量,建议:
- 使用高质量 WAV 格式(44100Hz 或 48000Hz,16bit 以上)
- 避免压缩过度的音频(如低码率 MP3)
- 开启"参考音频降噪增强"
Q:生成的中文数字读法奇怪(如"2024"读成"两千零二十四"而非"二零二四")?
开启"文本规范化",或手动将数字改为汉字形式,如
二零二四年。
Q:如何生成方言?
在合成文本中直接用方言词汇书写,并在风格指令中注明方言类型(如"粤语"、"闽南话")。不知道方言怎么写可以借助 AI 翻译工具。
Q:页面提示"后端暂时不稳定,请稍后重试"?
后端模型推理失败。请查看
logs/backend.log确认错误原因,常见原因包括 GPU 显存不足、模型文件损坏等。重新执行bash start_app.sh通常可解决。
Q:多人同时使用会排队吗?
是的,系统内置请求队列(默认最多 10 个排队),GPU 同一时刻只处理一个推理任务,多用户会依次排队处理。
Q:生成的音频文件保存在哪里?
服务器端自动保存在项目目录的
outputs/文件夹,文件名包含时间戳,保留 7 天。也可以通过页面播放器直接下载到本地。
九、操作流程速览
打开浏览器访问 http://<IP>:7860
│
├─ 只想设计一个新声音?
│ └─ 填写风格指令 → 填写合成文本 → 点击生成
│
├─ 有参考音频,要克隆音色?
│ └─ 上传参考音频 → 可选填风格指令 → 填写合成文本 → 点击生成
│
└─ 要最高精度克隆?
└─ 上传参考音频 → 开启极致克隆 → 等待/修正ASR文本
→ 填写合成文本 → 点击生成
│
▼
右栏出现播放器 → 播放 / 下载
 认证作者
认证作者
 支持自启动
支持自启动