GPT-SoVITS-V2
GPT-SoVITS-V2镜像提供高效零样本语音克隆与文本转语音工具,所需训练素材少、耗时短且情绪控制更精准,集成完整API接口及环境依赖,开箱即用。相比V1版本显著优化音色还原度与合成自然度,并增强跨语言支持与长音频稳定性,支持一键式本地部署。
 3
30元/小时
v1.0
GPT-SoVITS-V2项目介绍
项目官方仓库地址:https://github.com/RVC-Boss/GPT-SoVITS
可以的话还请给个star⭐
[整合包地址](lj1995/GPT-SoVITS-windows-package at main (hf-mirror.com))
该镜像的webui界面依赖于gradio public url,但是这玩意可能会挂
因此,这里放个链接,使用者手动检查gradio share link是否可用
点击👇
如果显示为down时,则不可用,此时不建议开机子训练. 等之后更新cli训练笔记本
推荐使用显存≥24g的卡,例如3090,4090,a100等
有问题请加群
交流群:829974025
官方示例以及整合包发布 BV12g4y1m7Uw
云端训练视频教程(基于autodl,但通用) 视频由我制作 BV1vU421d7Pi
使用步骤
进入JupyterLab后,打开“GPT-SoVITS.ipynb”文件可以看到详细教程
1. 先将长音频放到 workdir/GPT-SoVITS/input 文件夹中
2. 运行“GPT-SoVITS.ipynb”文件中“启动WebUI”代码块

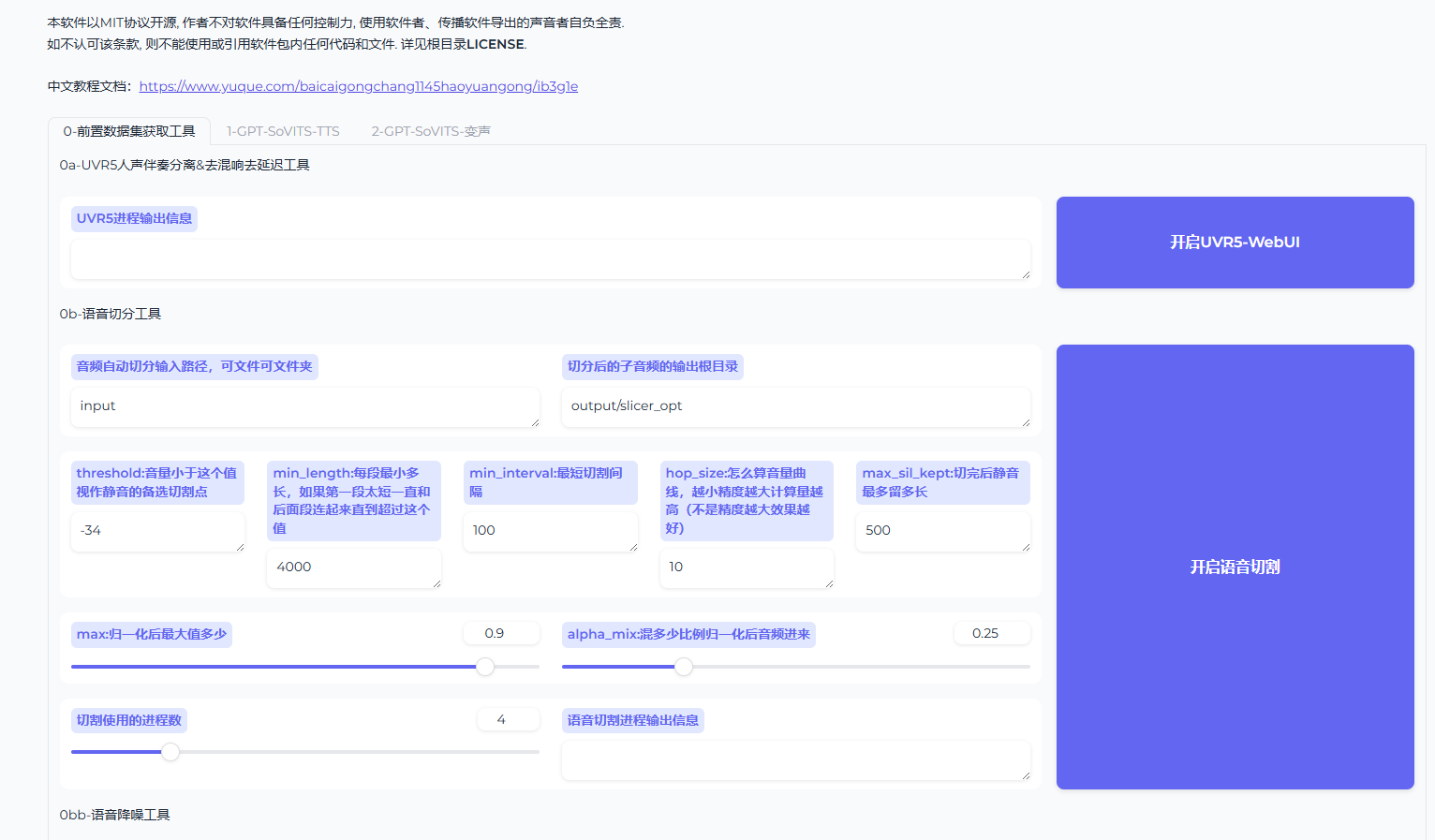
运行代码块后,当运行结果如图所示时,在浏览器中打开 http://0.0.0.0:9874 即可访问WebUI界面,将0.0.0.0替换为外网ip,外网ip可以在控制台-基础网络(外)中获取

3. 进入WebUI界面如下图所示
@39c5bb 认证作者
认证作者
认证作者
镜像信息
已使用320 次
运行时长
99 H
镜像大小
40GB
最后更新时间
2025-07-11
支持卡型
RTX40系20803080Ti309048G RTX40系2080TiH20A800P40A100RTX50系V100S
+12
框架版本
CUDA版本
11.8
应用
JupyterLab: 8888
版本
v1.0
2025-07-11